



(本稿は2023年10月20日の第10回データサイエンティスト協会シンポジウムで行われたスキル定義委員会パネルディスカッションの内容を編集部で再構成した。)
データサイエンティスト協会は、社会のビッグデータ化に伴い重要視されているデータサイエンティスト(分析人材)の育成のため、その技能(スキル)要件の定義・標準化を推進し、社会に対する普及啓蒙活動を行う目的で設立された一般社団法人だ。主に、データサイエンティストに求められるナレッジやスキルの定義、実態調査、ガバメントリレーションを含む情報発信に加え、セミナー・トレーニング・検定プログラムなどを実施しており、スキル定義委員会は「ナレッジやスキルの定義」を担っている。
同委員会は、協会理事と同委員会の委員長を兼務する安宅 和人氏(慶應義塾大学環境情報学部教授 / LINEヤフー株式会社 シニアストラテジスト)、協会事務局長と同委員会の副委員長を兼務する佐伯 諭氏(株式会社ビーアイシーピー・データ 取締役 COO ※2024年 1⽉ 1 ⽇付で就任)をはじめ、実務家中心の構成となっている。今回のパネルディスカッションには、上記お二人に加え、下記の委員が参加した。


スキル定義委員会 委員長 安宅 和人氏(慶應義塾大学環境情報学部教授 / LINEヤフー株式会社 シニアストラテジスト)
データの量が爆発的に増大し、データの取り扱いや分析の良否が社会に多大な影響を及ぼすようになった今日、データサイエンティストの役割はますます重要になっている。2013年5月に設立されたデータサイエンティスト協会は、2014年12月にデータサイエンティストを「データサイエンス力、データエンジニアリング力をベースにデータから価値を創出し、ビジネス課題に答えを出すプロフェッショナル」と定義(図1)し、その職能についての「ミッション、スキルセット、定義、スキルレベル」(2014年)を発表。2015年には「データサイエンティスト スキルチェックリスト」を発表している(同協会内のスキル定義委員会による)。このスキルチェックリストは隔年で更新され、2023年10 月20日に発表された最新版は、Ver.5(https://www.datascientist.or.jp/common/docs/skillcheck_ver5.00_simple.xlsx)である。
また、スキルチェックリストと並行して独立行政法人情報処理推進機構(IPA)と共同でデータサイエンス領域の「タスクリスト」も発表(2017年4月)しており、その最新版の「2023年版 タスクリスト ver.4」も同日に発表された。
(https://www.ipa.go.jp/jinzai/skill-standard/plus-it-ui/itssplus/data_science.html)
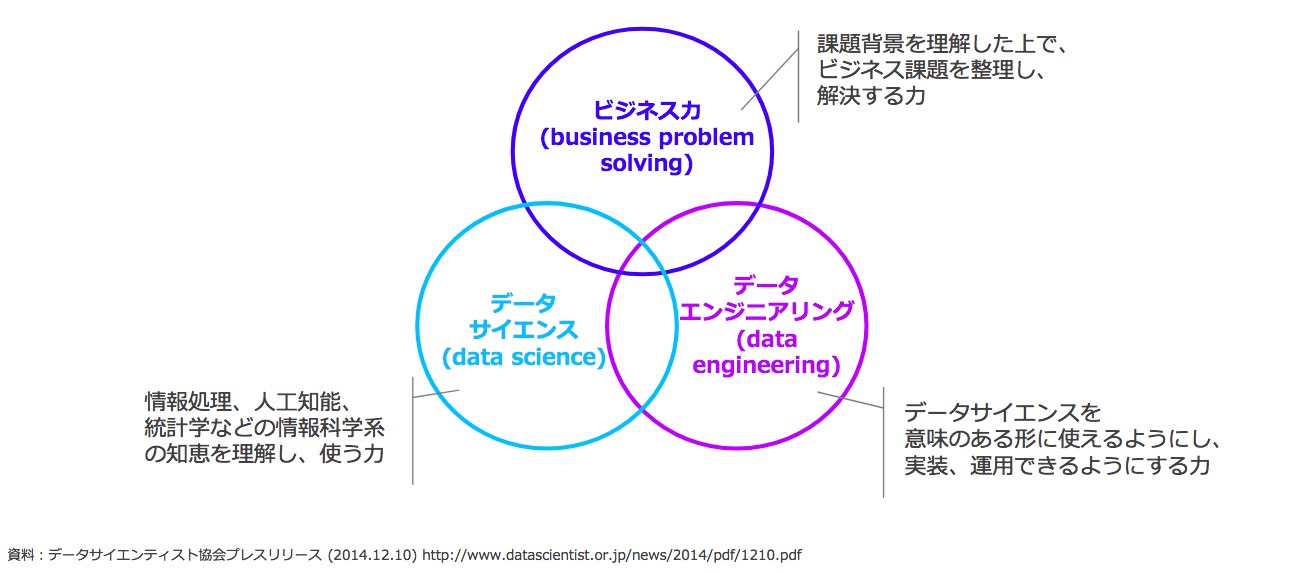
図1 データサイエンティストに必要な3つの領域
スキルチェックリストの今回の更新にはAI利活用スキルが追加された他、従来からのスキル定義も追加分と整合するように整理された。スキル定義委員会の安宅 和人委員長(慶應義塾大学環境情報学部教授 / LINEヤフー株式会社 シニアストラテジスト)は、「自然言語で対話できるGPT-4の登場は、知的生産現場における変革の歴史の1つの深い局面変容だ」と語った。そして「このようなLLM(大規模言語モデル)は途方もなく賢い。例えば、日本語と英語とフランス語とスペイン語とサンスクリット語を混ぜたテキストを読み解ける人間はまずいないが、LLMなら読み解ける。テーマが物理と経済学と政治、しかもスペインの政治と日本の政治を混ぜ合わせたテキストであっても読み解く。このような知性はいまだかつて存在したことはなく、人類史上全く特殊な何かが発生していることに間違いない」と続けた。

人間の脳の働きとして「共通性の発見」「関係性の発見」「グルーピングの発見」「ルールの発見」などがあるが、現在のLLMはまさにこれらの働きを担うことができる。人間はこのあまりに有能なLLMを使いこなすために「これまでよりもはるかに広い領域で深さと専門性を持った真の教養が求められる」と安宅氏は言う。そのようなプロフェッショナルがいなければ、人間が「機械の言いなりの存在になってしまう」可能性があるからだ。
同氏はさらに述べる。「従来からのデータサイエンス領域は『使える人』が5%いるかどうか、『つくり実装する人』や『企画する人』は1%以下の希少人材。それが生成AI領域では『使える人』が90%以上になる。生成AI領域では使えるのが当たり前で、むしろ実装や企画の方のスキルが重要になる(図2.1)。従来からのデータサイエンスのスキルも重要ではあるが、生成AI領域ではAIを使い倒す(AI利活用)スキルがより重要になる。そのことを踏まえ、これからのデータサイエンティストのスキルは、2つのスキル群(図2.2)に分けて考えざるを得ない」。
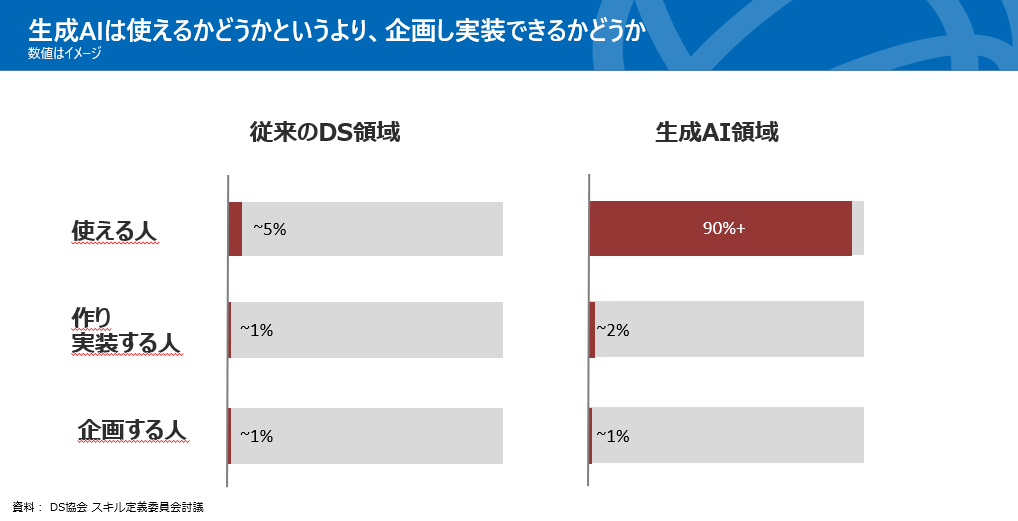
図2.1 DS領域と生成AI領域の違い

図2.2 データサイエンティストに必要な2群のスキル(イメージ)
ただし、AI利活用スキルは従来のスキルと隔絶したものではなく、「従来スキルの延長上にほぼ全てある。実際には3領域にクロスオーバー(交差)するようにスキルを定義している」と安宅氏。データサイエンス、ビジネスエンジニアリング、ビジネスの領域それぞれにAI利活用スキルは入り込むが、スキルチェックリストはAI利活用系のスキルだけを引き出すこともできるようにつくっているという。

スキル定義委員会 孝忠 大輔氏(日本電気株式会社AI・アナリティクス統括部長)
追加されたAI利活用スキルは、図3に見るように「利活用スキル」そのものとして34項目、「背景理解・対応スキル」として35項目、合計69項目である。
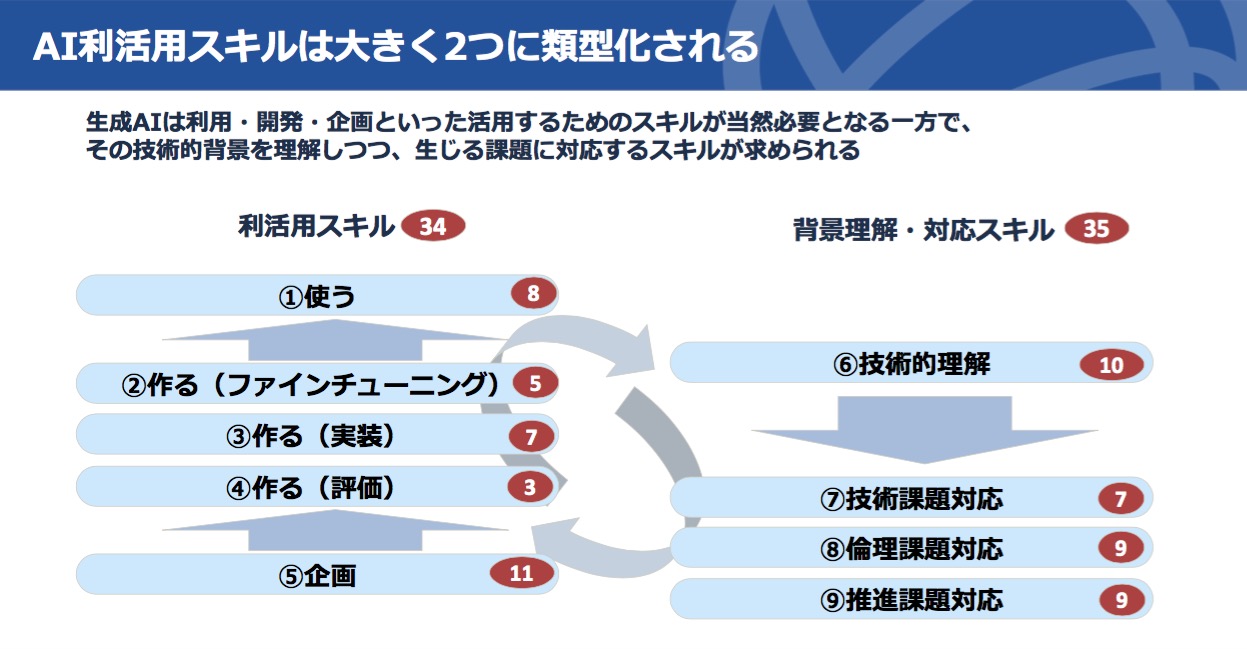
図3 AI利活用スキルの2類型(赤楕円数字はスキルの数)
スキル定義委員会メンバーである日本電気株式会社(NEC)の孝忠大輔AI・アナリティクス統括部長は、「これまではモデル構築やアルゴリズムを理解した実装といった基盤モデルをつくる部分が重要だったが、現在は基盤モデルのチューニング/アライメントや、業種・業務に沿ったチューニング、あるいは周辺システムづくりが重要になっている。この違いはかなり大きい。またこれまで使ってこなかった人が生成AIを利用することを考えると、メディア・リテラシー/ネットリテラシーを学び直すことも必要になる」と、2類型にわたるスキルの必要性を語った。

スキル定義委員会 高橋 範光氏(株式会社ディジタルグロースアカデミア 代表取締役社長)
また同メンバーの株式会社ディジタルグロースアカデミア 高橋範光代表取締役社長は、「例えば、プロンプトエンジニアリングに関して、エンジニアリング力/ビジネス力/サイエンス力などのカテゴリにふさわしいのかの議論が難航した。画像生成AIのプロンプトはプログラミングに近い要素があり、しかも議論の最中にChatGPTに画像生成AIが組み込まれるなど新しい動きも出てきた。いったんプロンプトエンジニアリングもデータエンジニアリングのカテゴリとしたものの、今後はどうなるか分からない状況にあり、まさに時代の転換点にいることを感じた」と話した。そのような議論を通して、従来からのスキル定義もAI技術に対応して整理されていった。
追加と整理を加えた結果、スキルチェックリストは従来の更新時の変化よりもはるかに大きく変貌した。安宅氏が「今回ほど激変したと感じたことは、これまでなかった」と語るほどである。次に、AI利活用スキルを図3中の利活用フェーズ①~⑨(使う~推進課題対応)に沿って、スキル定義委員会メンバーのコメントを記す。
音声入力/出力などのインタフェースやテキストチャット、画像の利用などにより、AIは誰にでも使えるものになる。このフェーズではあまりプロの仕事はない。「例えば、プロンプトエンジニアリングのスキルが★1つ、見習いレベルであることに注意してほしい。プロになる人はこのくらいはできていて当たり前」(安宅氏)。ハルシネーション(AIが事実にもとづかない情報を生成する現象)への注意や画像生成のプロンプトなどはややレベルが高い。
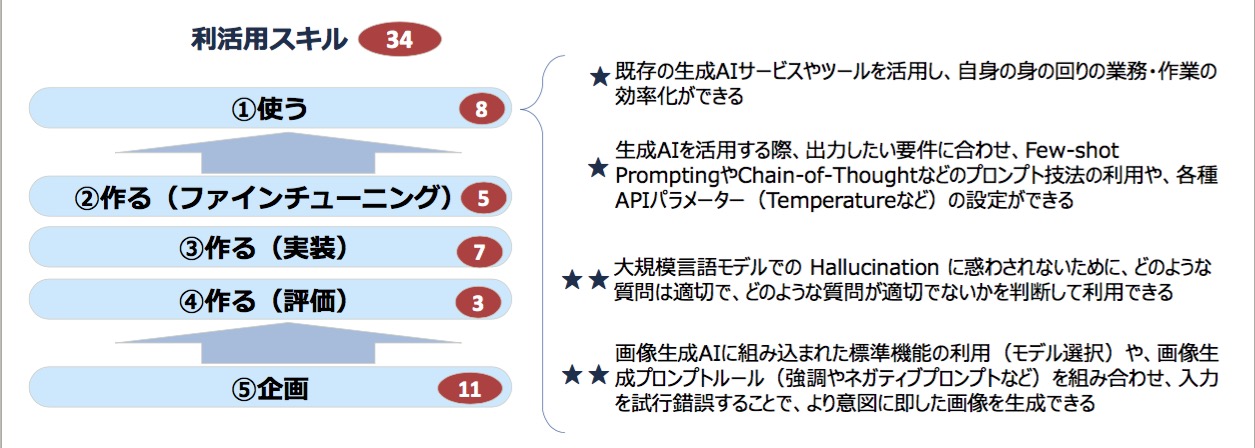
図4 使うフェーズのスキル例
| ★ | アシスタント・データサイエンティスト/見習いレベル |
| ★★ | アソシエート・データサイエンティスト/独り立ちレベル |
| ★★★ | フル・データサイエンティスト/棟梁レベル |
| ★★★★ |
シニア・データサイエンティスト/業界を代表するレベル |
※スキルの★印はレベルを表す。
生成AIのファインチューニングや実装は少し前まで困難な作業だったが、現在ではファインチューニングや実装環境が大幅に変わっている。「議論当初はLLMのモデルに手を加えられるかを話していたが、すぐに簡単にファインチューニングできる環境が出てきた。またAPIやプラグインも登場してシステムにつなぐ部分も出来てきた。現状では★2つレベルにした」(高橋氏)。
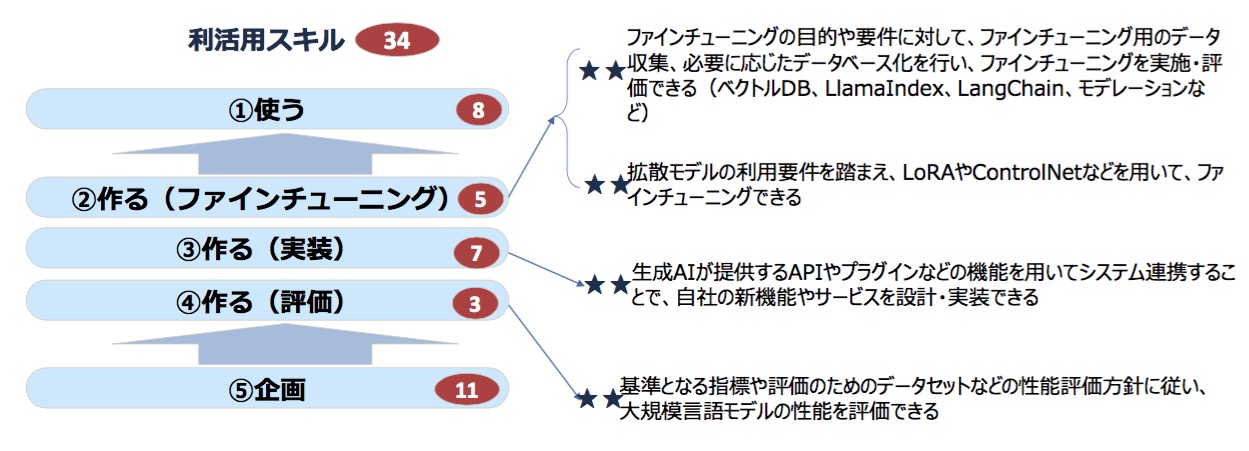
図5 作るフェーズのスキル例
株式会社アトラエのデータサイエンティストである杉山聡氏は「ChatGPTのファインチューニング機能も注目されるが、LLaMA(メタ社のLLM)のファインチューニングもよく使われている。これまで不可能に近いと思われていたことが、この1年で誰でもできるようになった。そうはいってもまだコストは高いが、AIの世界では1~2年で1桁ずつコストが落ちていく傾向がある。年を追うごとにコストは下がっていくため、今後やれることは増えていく」とオリジナルなLLM構築への期待を語った。

スキル定義委員会 杉山聡氏(株式会社アトラエ データサイエンティスト/AIciaSolid Project主催)
また安宅氏も「LLaMA2は月間ユーザー数7億人未満なら商用でも無料で使えるということで、事実上使い放題。カンブリア紀の大爆発のようにLLaMA周りの活動が爆増している状況になった。これにエキサイトしている人が、どの会社にもいるのが好ましいと思う」と話した。
アイデアを出すのが企画フェーズだ。しかしそれはただの思いつきでなく、データへの理解や開発・運用コスト/リスクの把握、新技術のキャッチアップからの新サービス企画・設計などのスキルを背景にしていなければならない。「先般、ソフトバンクグループ内で生成AI利活用のアイデアコンテストに優勝者に報奨金1000万円、賞金総額2500万円を出す試みが話題になったが、これも企画の重要性を認識しているからこその取り組みだろう(ちなみに5.2万件の提案があったという)」(安宅氏)。

スキル定義委員会 副委員長 佐伯諭氏(データサイエンティスト協会事務局長)
スキル定義委員会の副委員長である佐伯諭データサイエンティスト協会事務局長は、「何のためにAIを使うかは当初は曖昧なのが普通。それを会社のプロジェクトとして予算をとって進めるには、利用するLLMなどのコスト差の問題、ファインチューニングのコストを考えるばかりでなく、外部サービサーに社内データを一時的にも保管してよいのか、著作権侵害はないか、商用利用は回避できるかなど、生起するいろいろな問題を総合的に判断できるスキルが重要になってくる」と語った。

スキル定義委員会 森谷 和弘氏(データ解析設計事務所 兼 データアナリティクスラボ株式会社CTO)
データ解析設計事務所の森谷和弘代表(兼 データアナリティクスラボ株式会社CTO)は、「生成AIが普及し、使い方も簡単になって誰でも使えるようになったとき、AIが学習しているデータが間違っていると悪影響が広がることになる。データの品質についての理解が必要だ」と指摘した。
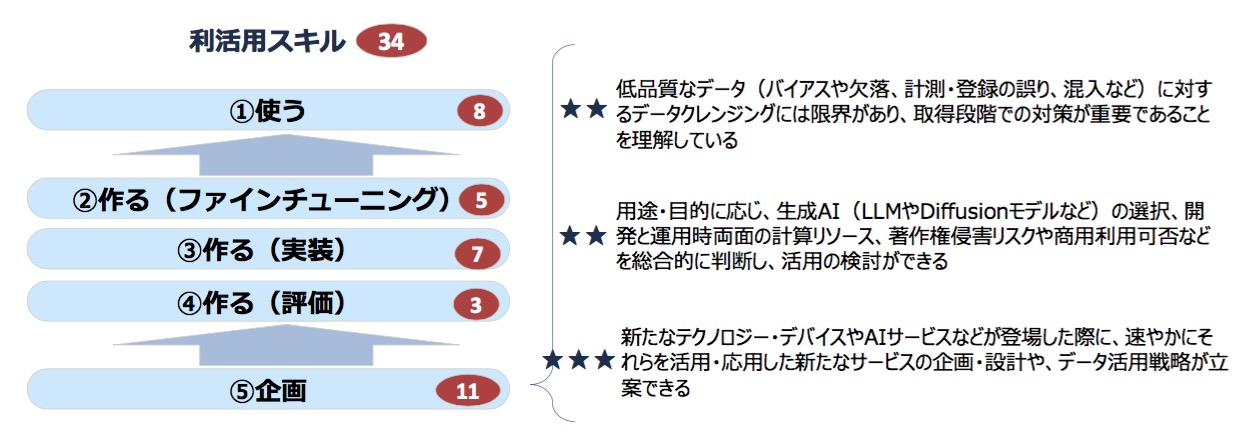
図6 企画フェーズのスキル例

スキル定義委員会 菅由紀子氏 (株式会社Rejoui 代表取締役)
AI利活用のためには背景となる技術的理解スキルや課題対応スキルも当然必要になる。これについて35種のスキルが組み込まれた。
株式会社Rejouiの菅由紀子代表取締役は「技術的な背景の理解がないと、技術課題・倫理課題・推進課題に対応ができない。これは非常に深く議論をしたところ」だと振り返った。
株式会社日立アカデミーの田中貴博研修開発本部部長は、「スキルの中に(図7の★1つの箇所に)直感的にわくわくし……という言葉がある。データサイエンティストには、この感覚を持ち、興味を持ってリサーチするという基本動作が必要だというメッセージを込めた」と語った。
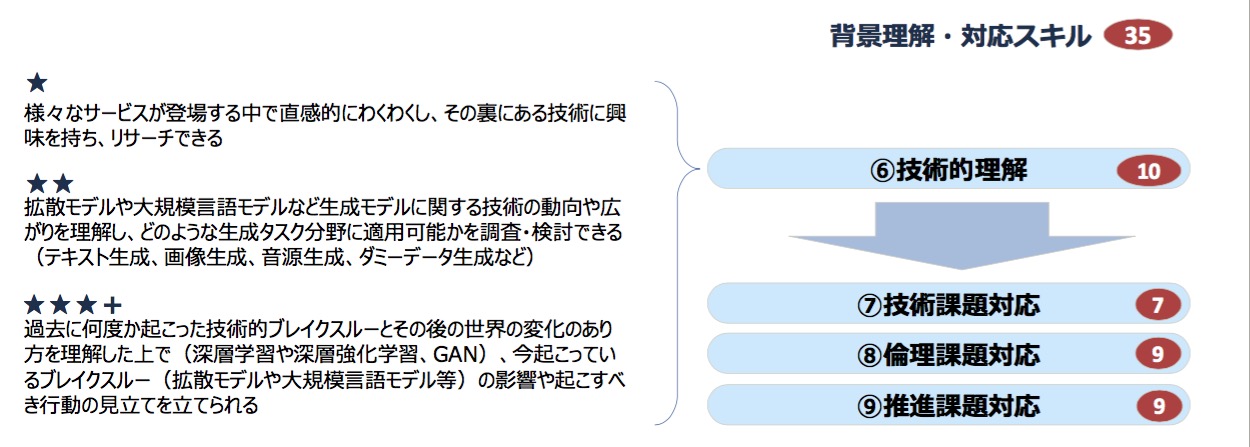
図7 技術的理解に対するスキル例

スキル定義委員会 田中貴博氏(株式会社日立アカデミー 研修開発本部部長)
田中氏は、⑦~⑧の課題対応に関してこう語った。「このあたりはビジネス力に主に組み込まれた。特に法整備が不十分なこともあり、おそらくグレーゾーンの中で今後活動せざるを得ないことがある。例えば、Azure OpenAIの環境を社内で構築したとして、そこにどこまでデータを入れてよいのかというガイドラインをつくって周知する必要がある。プライベートクラウドなのになぜ個人情報は入れてはいけないのかといった反発もあるだろう。つまり、組織としてどうルールを定めて遵守させるのかを考える必要がある。ChatGPTの登場当初は多くの企業でシャドーITの形で使われたと思うが、そのときのように、どこまでのことをやっていいのかをユーザー各自で判断できることは大事だという議論をした」。
また、佐伯氏は「例えば、金融会社で社外秘の情報をクラウドのAIサービスに出すのはリスクが高いが、やり方を変えてリスクのない仕組みを構築できないか。そのようなことを考えることが私たちに課された使命だ。やらない理由をつくるのは簡単だが、みんなでやる方向に持っていかなければいけない。ガイドラインを策定するなどの対応をした上で、積極的にデータ利活用を推進していくことが重要」だと指摘した。

図8 技術課題・倫理課題・推進課題に対するスキル例
以上、①~⑨の利活用フェーズのスキル例をスキル定義委員会メンバーのコメントとともに示した。各フェーズのAI利活用スキルは、データサイエンティストのスキル3領域に組み込まれている。その数とレベルを図9の通りだ。
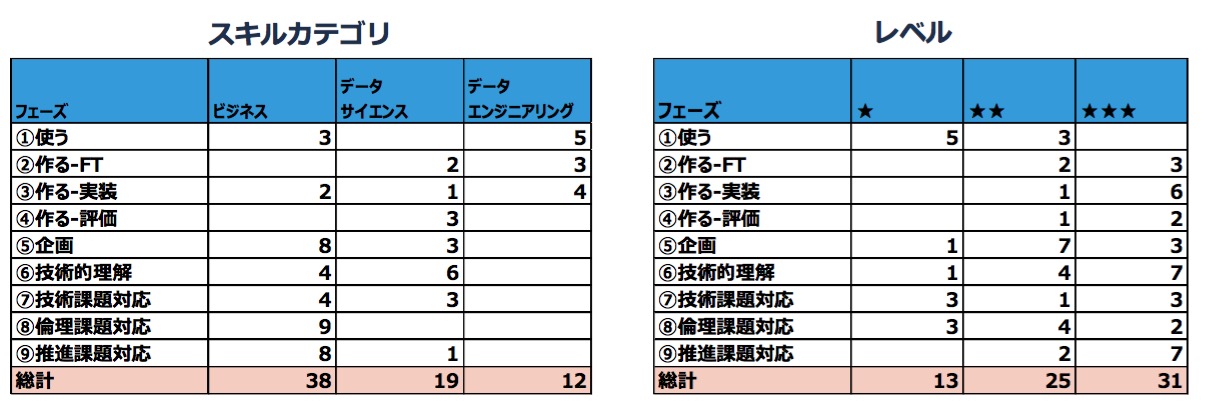
図9 AI利活用フェーズのスキル数(カテゴリ別、レベル別)
安宅氏は「これまで設定していたビジネス/データサイエンス/データエンジニアリングのスキルの中で、不要になるものはなかった。また、新たに組み込まれたAI利活用スキルは、ビジネス寄りで俯瞰的に見て判断するようなスキルが多い。データサイエンス領域は企画と技術的理解が中心になる。データエンジニアリング領域は実装が中心だ」と概要を説明する。
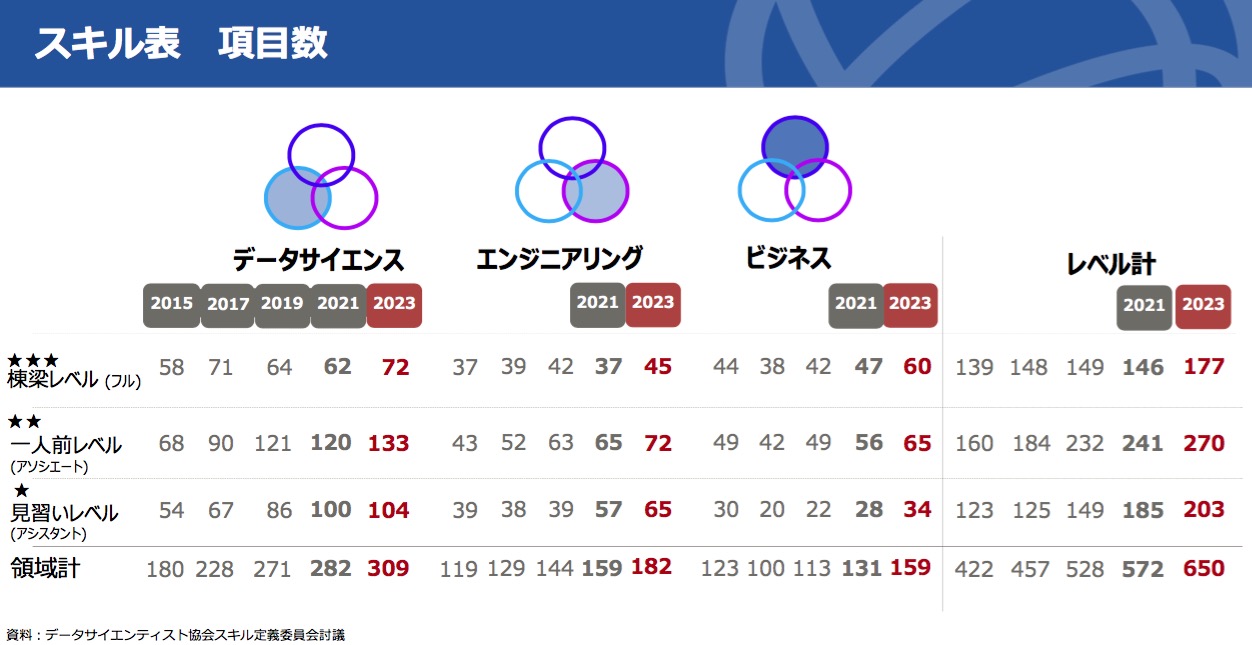
図10 スキルチェックリストのスキル項目の推移
安宅氏は「スキル項目数を減らすことに心を配ったが、結果として項目は増えた。学ぶことは増えている。またビジネス/データサイエンス/データエンジニアリングの3領域それぞれに組み込まれているAI利活用スキルは、現実のプロジェクトでは領域を越えて激しく交差する(図11)。その“交差する系”の能力を高めることが、少なくともチームリーダー級の人々には強く求められることは間違いない。現在は(数人の)データサイエンティストが3領域を分業するような形をとっているケースが多いと思うが、当面は全方位的に見られる人が1人は必要だと私たちは考えている」と語った。
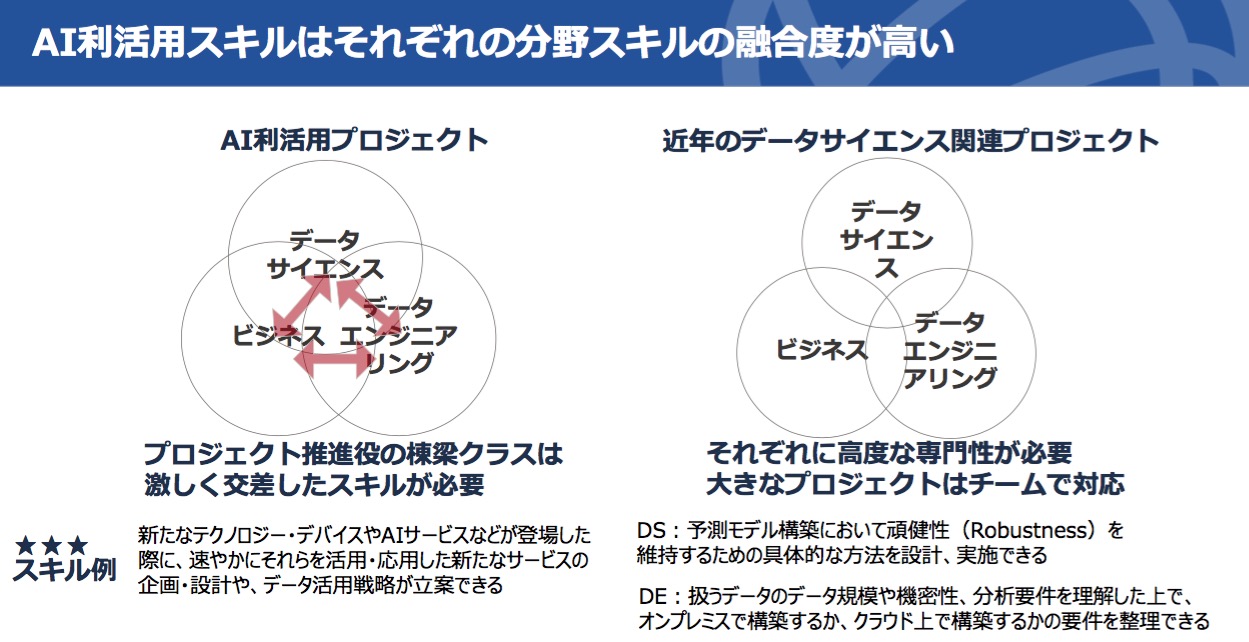
図11 3領域を激しく交差するAI利活用スキル
同日「AI利活用タスクリストVer.4」も発表された(IPAとの共同発表)。これは実際にプロジェクトを推進するときのタスク項目の流れのモデルだ。スキルチェックリストの内容とタスクフローは実際には掛け算のようになる。旧版までのタスクリストでは、プロジェクト立ち上げ、データ収集、データ解析/可視化、評価、業務への組み込みといった流れを描いていたが、その抜本的な見直しが図られた。
この作成に当たって孝忠氏は、「従来どおりのタスクリストと、AI利活用タスクリストの両方を提供している。生成AIの登場によってデータサイエンティストの業務も大きく変化する。その利活用のために『企画する』『実装する』『使う』というそれぞれの視点でタスクを整理した。生成AIの利用においては『ビジネスデザイン』や『ユーザー環境整備』が重要となる。既存のデータサイエンティストタスクリストとは異なるタスクも多くなるため、独立したAI利活用タスクリストとして作成した」と同リスト作成の背景と理由を示した。
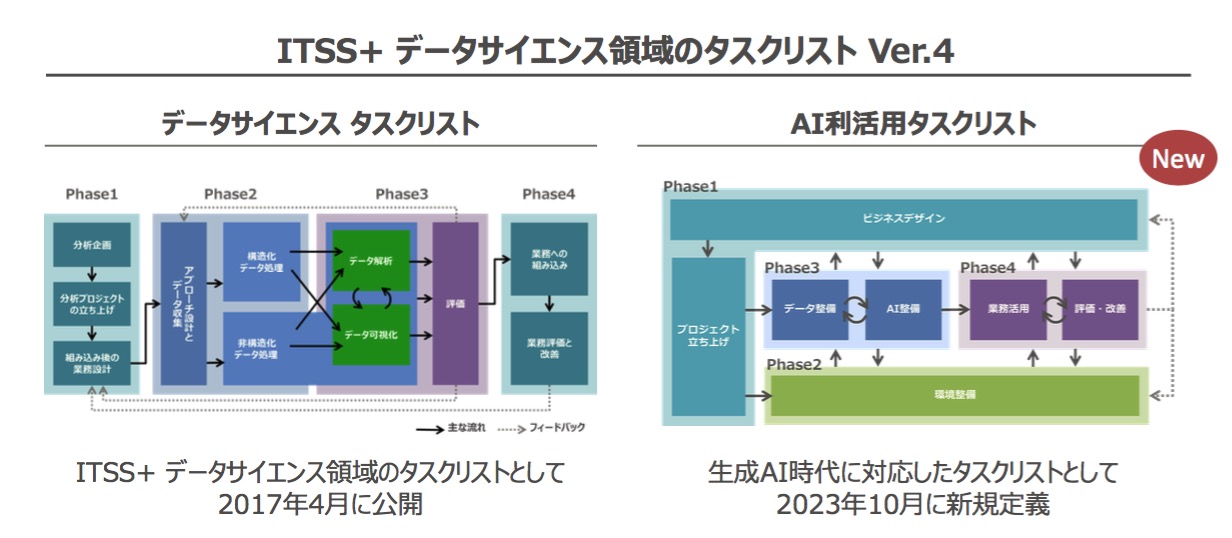
図12 従来どおりのデータサイエンスタスクリストとAI利活用タスクリスト
実際には、図12右のAI利活用タスクリストの各フェーズのそれぞれに詳しい業務フローが定義されている。孝忠氏はそれぞれのフェーズの重要ポイントを次のように解説した。
| フェーズ1 | ビジネスデザイン | 技術の理解があってはじめてビジネスモデルを検討できる。技術を踏まえて検討することが重要 |
| フェーズ2 | 環境整備 | 運用ルールの整備の一貫として、生成AIのリスクを理解してガイドラインを策定する |
| フェーズ3 | AI整備 | 生成AIモデルのファインチューニングやアライメントによる整備 |
| フェーズ4 | 業務活用 | 生成AIの出力をユーザーがどう使うか。UI/UXの重要性が高くなるため、そのデザインしっかりできる人が必要 |
安宅氏は「ガイドライン策定についても、結局、データサイエンティストが深く関わらないと実際には使われないという事例もある。この点も含め、AI利活用についてデータサイエンティストはこれまでとは異なる仕事でもやるべき局面を迎えている」と語った。データサイエンティストの役割はさらに重く、カバー領域は広くなる。しかしディスカッション参加者の表情はなべて明るく、「あまり重く考えず、わくわくする未来をつくろう」という発言も出るなど、希望を感じさせた。
メルマガ登録をしていただくと、記事やイベントなどの最新情報をお届けいたします。
ChatGPTとAPI連携したぼくたちが
機械的に答えます!
何か面白いことを言うかもしれないので、なんでもお気軽に質問してみてください。
ただし、何を聞いてもらってもいいですけど、責任は取れませんので、自己責任でお願いします。
無料ですよー
学びをシェアする



30秒で理解!インフォグラフィックや動画で解説!フォローして『1日1記事』インプットしよう!























データ越境者に寄り添うメデイア「データのじかん」が提供する便利ツールです。
本ツールは、JavaScriptを用いてお客様のブラウザ上で処理を行います。サーバーとの通信は行われず、入力データはお客様のみの端末内で処理されます。






















































