

「Webスクレイピングは違法なの?」
「Webスクレイピングのメリットや活用事例が知りたい!」
このようにお悩みではありませんか?
データ活用の前提として、まず材料となるデータがなければなりません。
そのために例えば機械学習のために大量の画像データを収集する、Webサイトから情報を集め、CSVファイルにまとめるといった作業を行いたい場合があるでしょう。
その際、役に立つのがWebスクレイピングです。
本記事ではWebスクレイピングとは何なのか、実際の実行方法、法律・マナーに反しないために押さえるべき注意点など基本事項を初心者向けにわかりやすくご紹介します。

Webスクレイピングとは“データを収集し使いやすく加工すること”です。
英単語のscraping(こすり、ひっかき)に由来し、特にWeb上から必要なデータを取得することをWebスクレイピングといいます。ツール・プログラミングでWebスクレイピングを自動化すれば、冒頭に挙げたようなデータ活用の前準備にかかる手間・時間は大幅に省略可能です。
Webスクレイピングと同じような意味の言葉にクローリングがあり、こちらは“Web上からデータを収集すること”を意味します。集めたうえで使いやすく抽出・加工するのがWebスクレイピングの特徴というわけですね。
なお、企業や公共機関はWebスクレイピングをするまでもなく情報を常時提供してくれることもあり、その際使われる仕組みをAPI(詳しくはコチラ)といいます。Webスクレイピングをする前に必要な情報がAPIで提供されていないか調べてみるのがおすすめです。
機械学習、マーケティング、サービス開発などWebスクレイピングは幅広い領域で活用されています。

次に、Webスクレイピングのメリットを3つ紹介します。
● 効率的にWebデータの収集ができる
● 最新の情報を収集できる
● APIでは手に入らないデータまで収集できる
それぞれのメリットについて解説するので、参考にしてください。
Webスクレイピングをすることで、効率的にWebデータの収集が可能です。
Webスクレイピングを活用することで、手動で情報を収集する必要がなくなります。自動化されたプログラムを使用することで、大量のデータを短時間で収集できます。
別の作業をしながらでも自動的にデータ収集ができるので、時間と労力を大幅に軽減可能です。
Webスクレイピングをすることで、最新の情報を収集可能です。
自動的に最新のデータを収集できるため、市場の動きや競合他社の傾向をリアルタイムで追い続けられます。最新かつ膨大なデータを得られるため、今後の動きの計画などが立てやすいでしょう。
Webスクレイピングをすることで、APIでは手に入らないデータまで収集可能です。
Webサイトでは、開発者向けにAPIを提供している場合があります。APIを使えばWeb上にあるデータの収集や共有がしやすくなりますが、すべてのWebサイトで提供されているわけではありません。
しかし、WebスクレイピングではAPIに関わらずデータの抽出ができるため、より多くの情報を得られます。

次に、Webスクレイピングのメリットを3つ紹介します。
● Webスクレイピングを行うこと自体が法律に触れる可能性がある
● Webスクレイピング対象サイトに負荷をかけてしまう可能性がある
● 著作権侵害の可能性がある
それぞれのデメリットについて解説するので、参考にしてください。
Webスクレイピングを行うこと自体が法律に触れる可能性があります。Webサイトの中には、利用規約で禁止されているものも少なくありません。利用規約を無視したり相手のWebサイトで不利益が生じたりすると、悪意の有無や意図的かどうかに関わらず動産不法侵入や偽計業務妨害罪に問われてしまう場合があります。
そのため、事前に必ず利用規約を確認しましょう。
Webスクレイピングを行うと、設定によっては対象のウェブサイトに負荷をかけることがあります。大量のリクエストを送信することでサーバーに過負荷がかかるため、利用規約やマナーに注意しましょう。
定期的に行う場合は、頻繁に収集すべきかどうかを吟味することが大切です。
Webスクレイピングを行うと、収集するデータによっては著作権侵害の可能性があります。
Webスクレイピングでは、テキストや画像・動画などの収集が可能です。しかし、すべてのデータをそのまま利用してしまうと著作権法に抵触する恐れがあります。
抽出したデータをそのまま活用したい場合は、抽出元に許可を申請したりフリー画像だけを使用したりしましょう。

次に、Webスクレイピングの活用事例を5つ紹介します。
● Webスクレイピングの活用事例①市場調査
● Webスクレイピングの活用事例②製品価格調査
● Webスクレイピングの活用事例③営業リストの作成
● Webスクレイピングの活用事例④最新コンテンツの収集・集約
● Webスクレイピングの活用事例⑤ビジネスの自動化
それぞれの活用事例について詳しく解説します。
Webスクレイピングでは、市場調査が可能です。市場調査に必要なデータを膨大かつリアルタイムに収集できます。市場調査において競合他社の動きを見たりトレンドを把握したりすることはビジネスにおいて非常に重要です。
膨大なデータを収集することで、過去の経験や勘に頼ることなく事実に基づいたマーケティングが可能となります。
Webスクレイピングでは、製品価格調査も可能です。
Amazonや楽天などのECサイトから商品の情報を収集することで、製品価格やトレンドを可視化できます。事実に基づいた効率的なビジネス戦略が取れるため、製品開発にはかかせません。
Webスクレイピングでは、営業リストの作成も可能です。
Webサイトの中には、特定の業種をまとめたページが存在します。ターゲットのデータだけを抽出することで、効率よく営業先のデータが集められるため、簡単に営業リストの制作が可能です。また、データによっては年齢・住所・関心などの情報も得られるため潜在顧客の獲得にも活用できます。
Webスクレイピングでは、最新コンテンツの収集・集約も可能です。
Web上には日々新しいニュースやトレンドが更新し続けられており、すべてをチェックすることは不可能です。しかし、Webスクレイピングを活用すれば事前に設定しておいた条件のデータを自動的に集め続けられます。
収集し続けられた情報はデータとして蓄積され、自社の製品開発などの参考にすることが可能です。
Webスクレイピングでは、ビジネスを自動化することも可能です。
例えば、定期的なビジネスレポートを作成し続けることは大きな労力がかかります。しかし、Webスクレイピングを活用すれば自動的にExcelやスプレッドシートにデータが溜まっていくため、単純に労働時間が短縮されます。
短縮された時間を考察や整理に充てれば、より高度なビジネスモデルの構築も可能でしょう。

スクレイピングの実践方法は大きく分けて2つあります。
ひとつは無料/有料のWebスクレイピングツール・サービスを利用すること。「Octoparse」「キーウォーカーWEBクローラー」「ScrapeStorm」「Web Scraper」などが例として挙げられます。かけられるコストとやりたいことがちょうど釣り合うものがあれば手っ取り早い選択肢です。
ふたつめの方法は自分でプログラミングすること。
Python、Ruby、JavaScript、PHP、VBAといった言語がプログラミングに用いられます。その中でもWebスクレイピング用のライブラリが豊富、かつプログラミング初心者でも比較的学習しやすいことで知られるPythonで実際にWebスクレイピングを行ってみます。
まずは、“どこからどのデータを取得したいのか”を決めましょう。
Webスクレイピングはあくまでも手段です。集めたデータが実際に活用できるかどうかは、ここでどれだけ明確に目的を定められるかに大きく左右されます。
今回は身近な例を提示するためYahoo! Japanニュースの経済カテゴリトップページに掲載された見出し(画像赤枠部分)のテキストとそのリンクをWebスクレイピングしたいと思います。なお、ブラウザはGoogle Chromeを使います。
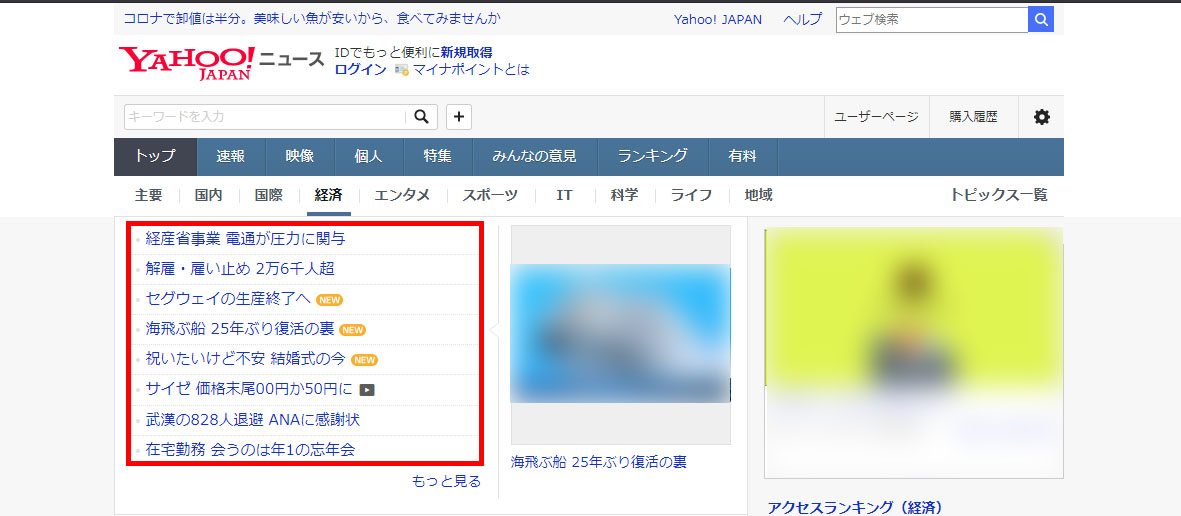
2020年6月24日(水)14:42時点のYahoo! Japanニュースの経済カテゴリトップページ
Webスクレイピングの対象が決まったらF12もしくは「右上の縦『…』>その他のツール>デベロッパーツール」でデベロッパーツールを開きます。デベロッパーツールにより、WebサイトのHTML構成を確認することができます。
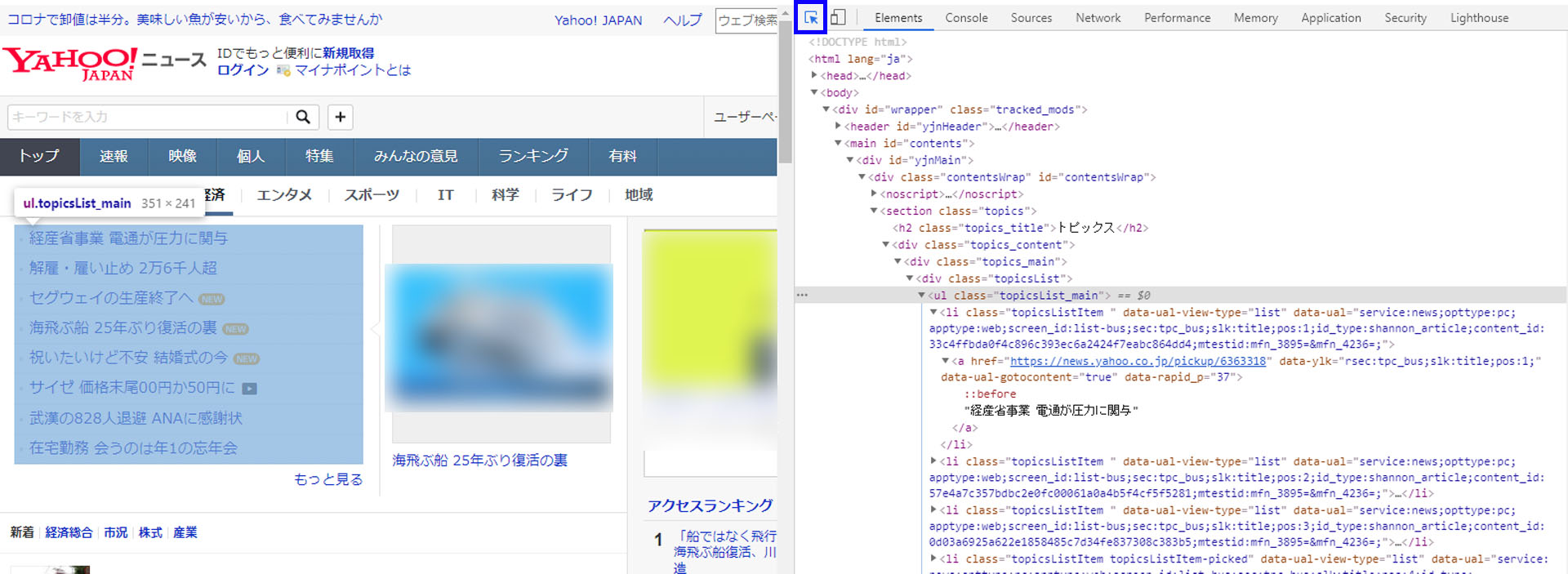
四角の中に矢印が記載された「セレクトボタン」(画像青枠部分)をクリックして、カーソルをWebページのWebスクレイピングしたい情報が記載された部分に持っていきましょう。色が変わって範囲が選択されるとともに、その個所に対応するタグが灰色にマーキングされます。
ここからさらに「▼ボタン」で下の階層を探ることで、手に入れたいデータ(今回の場合見出しのテキストとリンク)を指定するためのタグがわかります。 今回の場合、topicsList_mainクラスのaタグで囲われた部分に目的のデータが記述されているようです。

いよいよ、Pythonによるプログラミングを行います。
今回はJupyterLabを開発環境として用いました。 利用したライブラリはスクレイピングでよく用いられる「requests」と「BeautifulSoup4」です。
実際に記述したプログラムは以下の通り。
import requests
from bs4 import BeautifulSoup
load_url = "https://news.yahoo.co.jp/categories/business"
html = requests.get(load_url)
soup = BeautifulSoup(html.content, "html.parser")
topic = soup.find(class_="topicsList_main")
for element in topic.find_all("a"):
print(element.text)
url = element.get("href")
print(url)
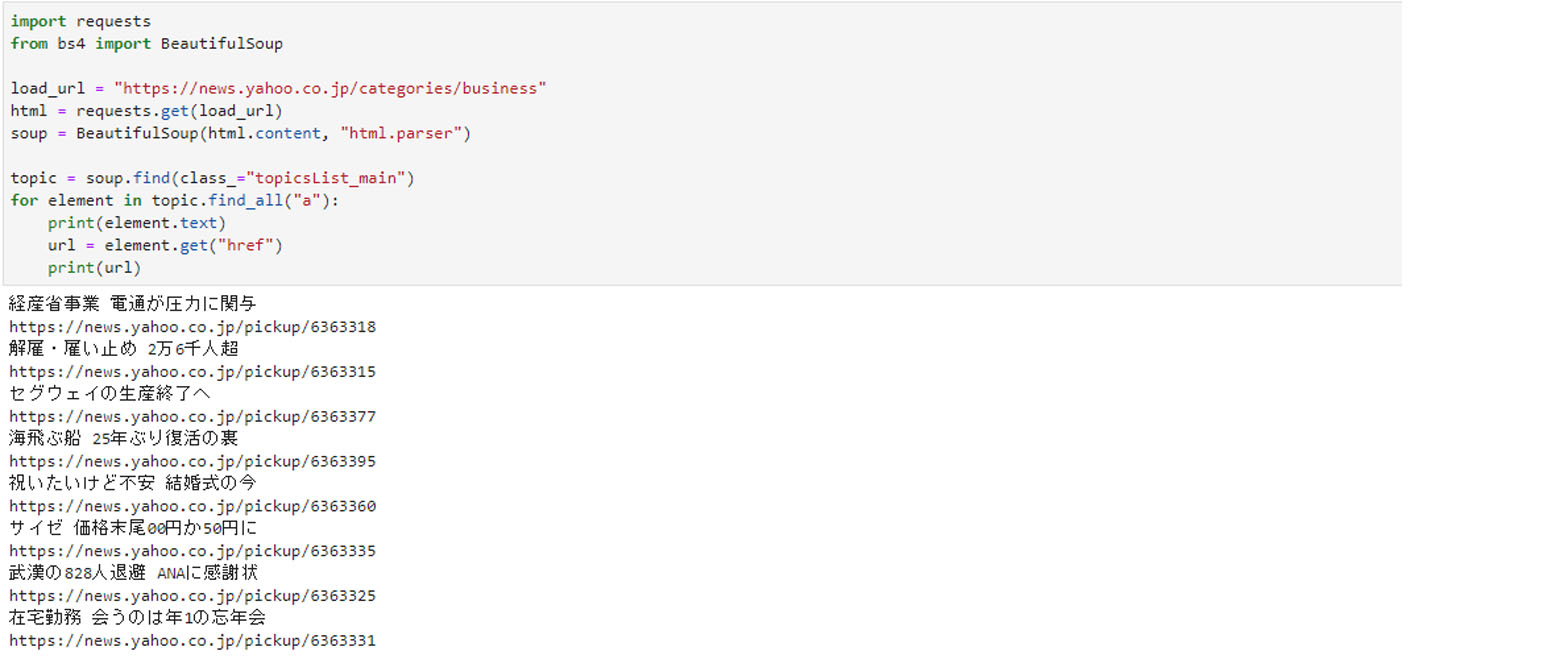
ご覧の通り、見出しのテキストとリンクが取得できました。
今回は少数のテキストデータとリンクをWebスクレイピングするだけでしたが、より多くのアクセスを必要とする場合は「time」ライブラリなどを使ってサイトに負荷を与えない配慮が必要になります。
なお、Webスクレイピングに関わるpythonのライブラリにはほかにもクローリング、Webスクレイピングに特化した「Scrapy」や解析やグラフ描画に使われる「pandas」「matplotlib」などがあります。
また、最近ではChatGPTでもノーコードでWebスクレイピングができるスクリプトが開発されています。
例えば、以下のようなコードでWebスクレイピングが可能です。
以下の条件を満たすコードを python で作成お願いします。 コードはインデントに注意してコードブロックで出力お願いします。 ■やりたいこと ウォーキングイベントのチーム対抗ランキングの特定3チームの、順位、チーム名、総歩数の平均をgoogle スプレッドシートに保存する。 ■条件 ・使用ライブラリ/ツール ・selenium 4 ・driver.find_element_by_id 等は使用せず、 driver.find_element(By.ID, 等を使用する ・webdriver webdriver.Chrome()のexecutable_path引数は使用しない。 Serviceオブジェクトを使用する。 ・webdriver-manager https://pypi.org/project/webdriver-manager/ ・Google Sheets API ・認証情報は同じ場所に credentials.json として保存されている ・service_account.Credentials.from_service_account_file の引数は2つ ・特定3チームのチーム名 ・「ACCESS_A」が含まれるチーム。 実際は「【募集】ACCESS_A」等前後に別のテキストが含まれる可能性あり ・「ACCESS_B」が含まれるチーム ・「ACCESS_C」が含まれるチーム ・起動引数でオプション ・headless モード有りオプション。 ・デフォルトはheadlessモードオフ。 ・コードはベタ書きではなく適切に関数化 ・チーム名、ファイル名、シート名等あとから変更する可能性があるものはコードの上部にまとめて記載 ・IDとパスワードは login_info.json に記載し、そこから読み込むようにしてください ・credentials.json や login_info.json のローカルファイルは cron で実行できるように 本スクリプトの PATH を起点にしてファイルを開けるようにしてください ・特定チームが見つかった時点のスクリーンショットを取得 ・まずアクセスする URL は https://pepup.life/campaign/XXXX/ranking?mode=team&page=1 だが、ログインが必要なので https://pepup.life/users/sign_in に自動的にリダイレクトされる。 ログイン完了後は https://pepup.life/campaign/XXXX/ranking?mode=team&page=1 に自動的に遷移する。 その後順次以下のように URL を変更し巡回する。 https://pepup.life/campaign/XXXX/ranking?mode=team&page=2 https://pepup.life/campaign/XXXX/ranking?mode=team&page=3 ・エラー処理 ■ログインページの selector ID、パスワード、ログインボタン、それぞれ以下。 sender-email user-pass <input type="submit" name="commit" value="ログイン" class="btn btn-default btn btn-primary btn-block" data-disable-with="ログイン"> ■取得するデータ ・ランキングの table タグ。 3列あり、左から「順位」、「チーム名」、「総歩数の平均」。 1ページ30位まで記載があり、何ページまであるかは分からない。 1つの順位分の tr タグ例は以下。 これらのHTMLを selector としてください。 <table> <tbody> <tr class="table-row head"><td style="text-align: right;">順位</td><td style="text-align: left;">チーム名</td><td style="text-align: right;">総歩数の平均</td></tr> <tr class="table-row"><td style="text-align: right;"><span class="num-value">768</span><span class="gray">位</span></td><td style="text-align: left;">ACCESS_A</td><td style="text-align: right;"><span class="num-value">61715</span><span class="gray">歩</span></td></tr> ■保存先 https://docs.google.com/spreadsheets/d/XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX/edit シート名:ウオキング A1セル:「順位」というテキスト B1セル:「チーム名」というテキスト C1セル:「総歩数の平均」というテキスト D1セル:「URL」というテキスト A2セル:ACCESS_A チームの順位 B2セル:「ACCESS_A」というテキスト C2セル:「ACCESS_A チームの総歩数の平均」という数値 D2セル:ACCESS_A チームの URL A3セル:ACCESS_B チームの順位 B3セル:「ACCESS_B」というテキスト C3セル:「ACCESS_B チームの総歩数の平均」という数値 D3セル:ACCESS_B チームの URL A4セル:ACCESS_C チームの順位 B4セル:「ACCESS_C」というテキスト C4セル:「ACCESS_C チームの総歩数の平均」という数値 D4セル:ACCESS_C チームの URL引用:ChatGPT(GPT-4) で一撃でスクレイピングするコードを生成出来たので感想とコツ

便利なWebスクレイピングですが、注意点を守らなければ法律違反・トラブルとなる可能性もあります。
その注意点は、以下の通り。
取得したデータをそのまま公開・販売する、複製して頒布するなどの行為は著作権法で禁止されています。他者の著作物は、情報解析もしくは検索サービス提供のために用いられる場合のみ記録・翻案することが許されます。
また、取得先のサイトに負荷を与えることは偽計業務妨害罪に当たると判断される可能性があります。例えば、2010年に起こった岡崎市立中央図書館事件では、図書館の蔵書システムにアクセスし図書情報を取得していた男性が、システムアクセス障害が生じたことをきっかけに逮捕されました。男性は不起訴となり、また図書館システム自体に問題があったことが指摘されましたが、悪意のないスクレイピングであっても逮捕につながった事例があることは押さえておきたいところです。
また法律違反でなくとも、サイトの利用規約で禁止されているのにスクレイピングを行えば民事訴訟に発展する可能性も少なくありません。例えばTwitterは利用規約によりTwitter社による同意のないWebスクレイピングを禁止しています。
Webスクレイピング・クローリングに対するサイト側の考えは利用規約のほかに、サイトに設置されたrobots.txtというファイルやHTML内の「robots metaタグ」で確認することができます。
ほかにも、不当な目的のためにWebスクレイピングをしてはいけません。Webスクレイピングを悪用すればコピーコンテンツの作成やデータの販売も簡単にできてしまいます。しかし、Webスクレイピングを悪用した場合には法律違反となる場合もあるため、やめましょう。

最後に、Webスクレイピングに関するよくある質問を4つ紹介します。
● WebスクレイピングとAPIは同じ?
● Webスクレイピングとは?クローリングとの違いは?
● Webスクレイピングは違法?
● Webスクレイピングが禁止されているか確認する方法は?
それぞれの質問に対して回答します。
WebスクレイピングとAPIは別物です。どちらもデータを収集できる点では同じですが、過程や集められるデータが異なります。WebスクレイピングはHTMLを解析させるため、Web上にあるあらゆるデータを収集できます。一方で、APIは外部ツールを使用して開発者向けに提供されている情報です。
例えば、X(旧Twitter)やFacebookなどとAPI連携をすることでアカウントの情報を得られます。なお、APIが収集できるデータには制限があり、すべてのデータをそのまま集めることはできません。
Webスクレイピングとは、「特定のデータを収集する」ことです。一方で、クローリングは「巡回してWebの構造や要素を探る」ことを指します。Webサイト上をbotが巡回する動作自体は似ているものの、最終目的が違います。
ただし、特定のデータを得るためにはサイト構造を探らなければいけないため、Webスクレイピングとクローリングは同時に行われることも少なくありません。
Webスクレイピング自体は基本的に違法ではありません。なぜなら、Web上に公開されているデータを集めるだけなので、Webサイトを閲覧していることと同等の行為だからです。しかし、抽出したデータの扱い方によっては違法になってしまう可能性があります。Webサイトの利用規約を確認し、データの抽出が禁止されていないかどうか、データの取り扱いに指定はないかどうかを事前に確認しておきましょう。
Webスクレイピングについては、Webサイトの利用規約で禁止されているかどうかを確認できます。例えば、Amazonの利用規約には以下のように記載されています。
この利用許可には、アマゾンサービスまたはそのコンテンツの転売および商業目的での利用、製品リスト、解説、価格などの収集と利用、アマゾンサービスまたはそのコンテンツの二次的利用、第三者のために行うアカウント情報のダウンロードとコピーやその他の利用、データマイニング、ロボットなどのデータ収集・抽出ツールの使用は、一切含まれません。引用:Amazon.co.jp利用規約

データ収集の強い味方「Webスクレイピング」の基本をまとめました。
データは今やマーケティング、商品開発、企画、営業などほとんどの仕事でかかせない武器の一つです。その調達を助けるWebスクレイピングは、非常に汎用性の高い技術だといえるでしょう。
法律・マナーの順守は徹底しつつ、まずは興味のある分野のデータを取得することからどんどんチャレンジしてみてください!
(宮田文机)
・ 森巧尚『Python2年生 スクレイピングのしくみ 体験してわかる!会話でまなべる!』翔泳社、2019
・ スクレイピング 【 scraping 】 ┃IT用語辞典e-words
・ スクレイピングとクローリングの違いとは?コードで解説(Python)┃Workship
・ データ収集だけ解説しても意味がない―『Pythonによるクローラー&スクレイピング入門』インタビュー┃CodeZine
・ PythonでWebスクレイピングする時の知見をまとめておく┃stimulator
・ 柿沼太一「「STORIA法律事務所」ブログ:改正著作権法が日本のAI開発を加速するワケ 弁護士が解説」┃AI+ by IT media NEWS
・ スクレイピングは違法?3つの法律問題と対応策を弁護士が5分で解説┃TOPCOURT
・ 「SIerとしての責務を果たせていなかった」 図書館システム問題でMDIS謝罪┃ITmediaNEWS
・ 柿沼太一「進化する機械学習パラダイス ~改正著作権法が日本のAI開発をさらに加速する~」┃STORIA法律事務所
・ 政府統計の総合窓口e-Stat
・ 電子政府の総合窓口e-Gov
メルマガ登録をしていただくと、記事やイベントなどの最新情報をお届けいたします。
ChatGPTとAPI連携したぼくたちが
機械的に答えます!
何か面白いことを言うかもしれないので、なんでもお気軽に質問してみてください。
ただし、何を聞いてもらってもいいですけど、責任は取れませんので、自己責任でお願いします。
無料ですよー
学びをシェアする



30秒で理解!インフォグラフィックや動画で解説!フォローして『1日1記事』インプットしよう!























データ越境者に寄り添うメデイア「データのじかん」が提供する便利ツールです。
本ツールは、JavaScriptを用いてお客様のブラウザ上で処理を行います。サーバーとの通信は行われず、入力データはお客様のみの端末内で処理されます。








































