


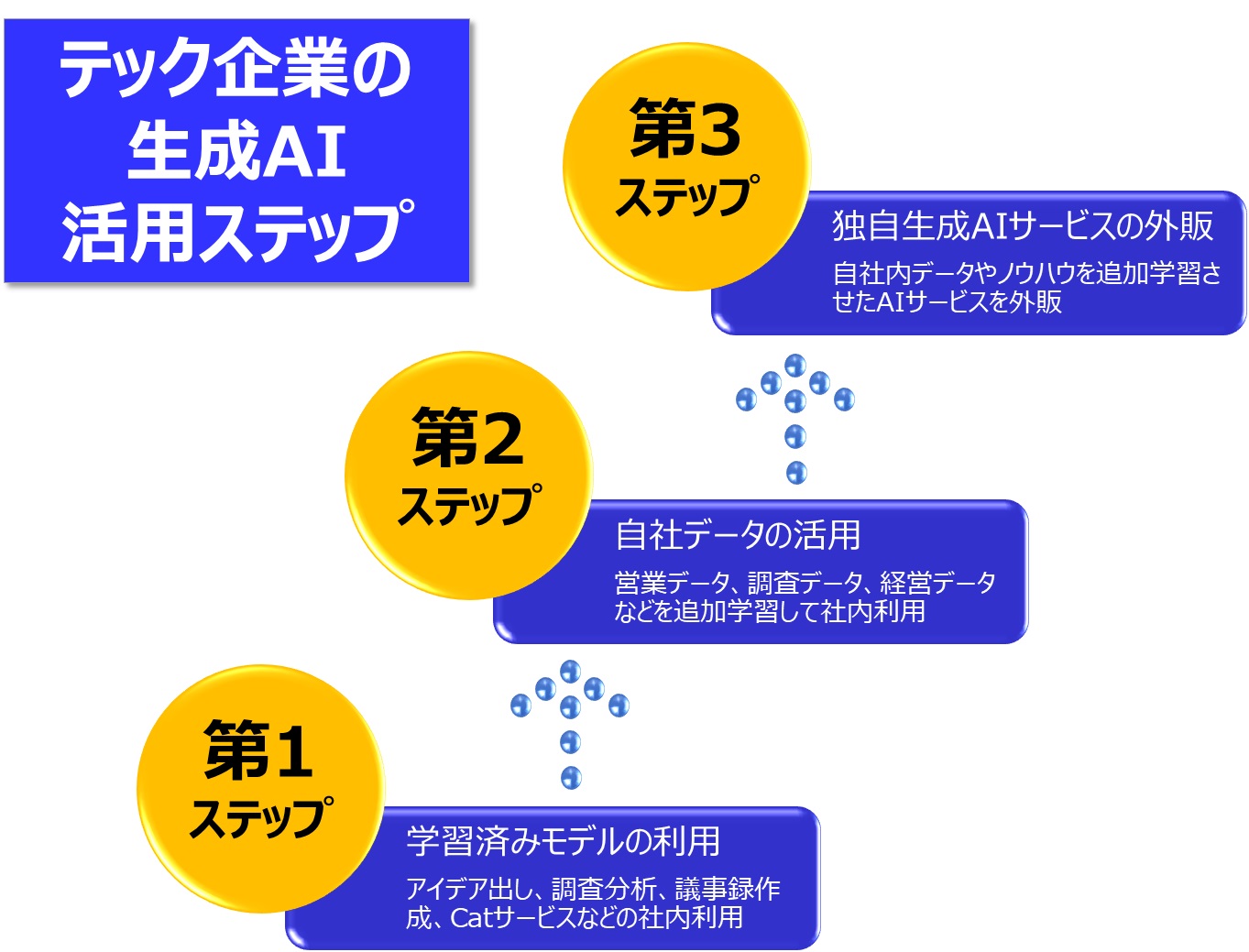
※図版:著者作成「テック企業の生成AI活用ステップ」
![]()
では話を進めます。“進化するAIは仕事をどう変えるのか(第4回)”で説明しましたが、生成AIの利用当初は事前学習済みの知見を利用した会話形式のサービスから利用を始めていると思います。GPT-4が実装されたCatGPTなら、通常の事務作業はデフォルト状態で十分業務に役立てるはずです。これが図の第1ステップです。
生成AIのUI(ユーザーインターフェース)は従来のコンピュータと異なり言葉なので、一般企業や自治体でも手軽に利用して業務効率化ができます。この画期的なUIと大量の事前学習があるため大流行したのですが、テック系企業ならこの段階で止まらずに、早々に次のステップへと進むべきです
![]()
なぜですか?生成AIは、業務を効率化して社員の生産性が上げるためのツールですよね
![]()
もちろんそうですが、ビッグテックが提供する生成AIを利用するには相応のコストが発生します。シンプルなツールの利用としての労働生産性向上だけでは、ビッグテックが潤うだけでテック系企業同士の生存競争にも勝てません
![]()
ではどうしたらよいのですか?市場を牛耳っている巨大なプラットフォーマーに対抗することができるのですか?
![]()
そこで、各企業が社内に抱えている、販売データやマーケット調査データ、品質管理データ、設計ノウハウなどの独自のデータが鍵となります。これらのデータは、業界特有であり非常に貴重なデータです。
生成AIは、基本的にネットで公開されているテキストや画像を大量に学習していますが、公開されていない企業内データや業界固有のデータなどは、もちろん学習していません、というかできません
![]()
そういえば、無料で使えるCatGPT3.5は数年前のネット情報から学習しているので、ロシアのウクライナ侵攻すら知らないんですよね
![]()
学習済みの生成AIもオープンソースとして公開されているので、今からは学習データの価値が非常に上がってきます。Google、Meta(Facebook)、Amazonは、ユーザーのアクセスログを収集・分析して、莫大な個人データを獲得することで巨大な収益を得てきました。メガプラットフォーマーになり、データを独占することが、今現時点で最高のビジネスモデルだったのです
![]()
ですから、そんなアメリカのメガプラットフォーマーに、どうすれば対抗できるのですか?
![]()
では欧州の戦略を参考にしましょう。欧州が2018年に施行した、EU一般データ保護規則(GDPR)は、包括的なデータプライバシー法です。この強力な法律によって、EU域内の個人に対して商品やサービスを提供する企業に適用され、EU域内に拠点がなくても、EU域内の個人データのEU域外持ち出しや目的外利用が禁止されます。
違反した企業には、莫大な損害賠償を負わされます。実際にAmazonは、2021年7月にGDPR違反として制裁金970億円の支払いを命じられました
![]()
とりあえずビッグテックの欧州での活動に制限を加えたのですね。個人情報保護という理由なら表立って反対できませんからね。でもそれだけでは、依然としてプラットフォーマーとしての地位は揺らぎませんね
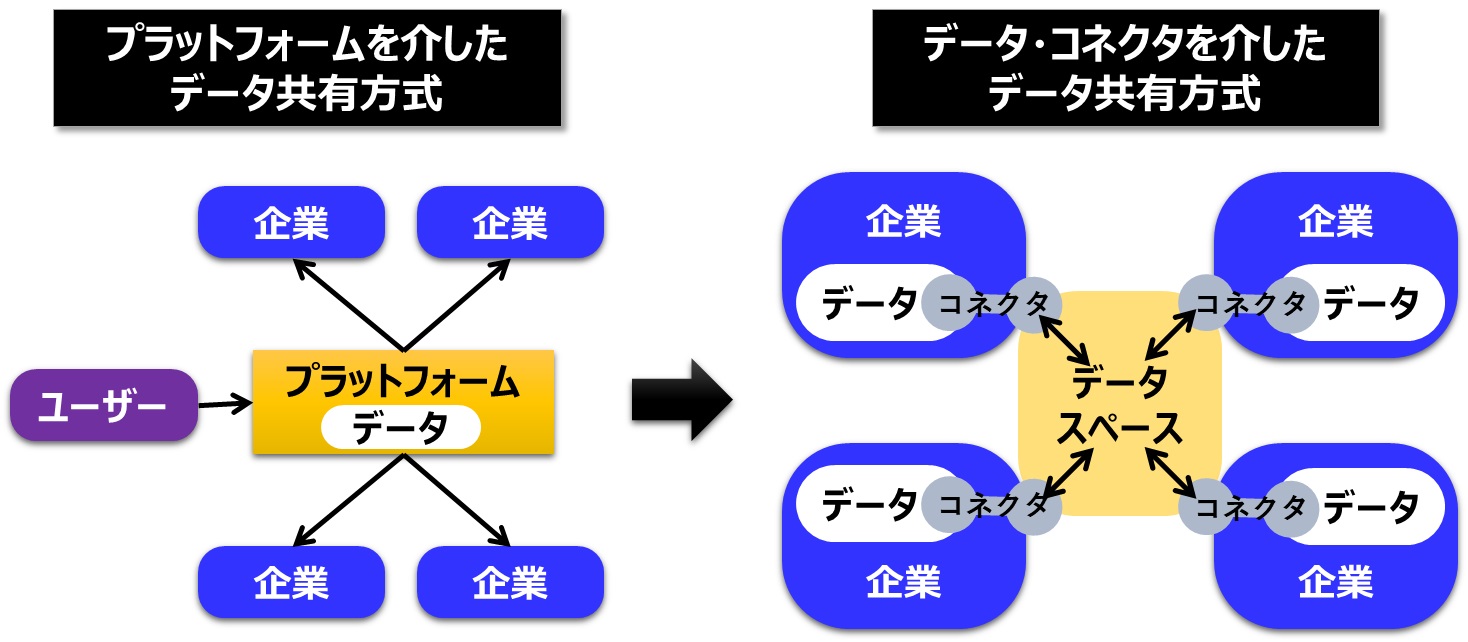
※図版:著者作成「プラットフォーマーとデータの民主化」
![]()
次の手として欧州は、”データの民主化”を謳いだしました
![]()
どういうことでしょうか?
![]()
図の左側は、現在のプラットフォームを介したユーザーデータの共有方式を模式図にしたものです
![]()
具体的なイメージが分かりませんが
![]()
例えばGoogle Chrome は2023年9月時点で、ブラウザの世界シェアトップであり2位以下を大きく引き離し65%を占めています。Googleはアクセスログを常時解析し、ユーザー個別の好みや関心ある広告を表示し、クリック率に応じた広告費を年間8兆円以上スポンサー企業から稼いでいます
![]()
まぁそれは有名な話ですね
![]()
これだけでなく、特定の分野においてシェアトップになりそうなベンチャー企業が登場すると、ビッグテックはすぐに企業買収を仕掛けます。これはその企業が持つ技術や人材が欲しいだけでなく、ユーザーデータの獲得も目的なのです。
例えば、Googleは赤字だったスマートウォッチメーカーのFitbit社を、2021年に3300億円を投じて子会社化しています。これは世界で急成長を続けるFitbit社が持つ、貴重なヘルスケアデータが目的のはずです
![]()
どういうことですか?
![]()
Fitbit社は世界100カ国以上でデバイスを1億2,000万台以上販売し、ユーザー数が3,000万人以上います。(註1)ユーザーの性別や年齢は登録されており、デバイスはGPSや各種センサーによって位置情報と活動量、体温、心拍数などのバイタルデータを常時測定してクラウドにアップしています
![]()
ジョギングやトレーニングをしている人にとっては、スマートウォッチは有益な情報を提供してくれるので役に立ちますが、Googleはなぜ大金を投じてまでFitbit社を欲しがったのですか?
![]()
GoogleはApple Watchを持つApple社と同じく、ライフサイエンス領域に進出しつつあります。ウエアラブル機器は医療と親和性が高いので、高い成長が見込めるライフサイエンス領域の足掛かりとしてFitbit社を買収したのです。しかも数千万人分の10年近いバイタルデータはとても貴重なのです。データが金の卵を産むニワトリであることを熟知しているGoogleだから大金を投じたのです
![]()
ということはスマートウォッチのトップメーカーであるApple社は、すでにヘルスケア領域で活用しているのでしょうね。Amazonは購買データからユーザーに商品をレコメンドしていることは知っていますが、Googleと似たようなことをやっているのですか?
![]()
Amazonは2022年に、ロボット掃除機ルンバのアイロボット社を赤字だったにもかかわらず2,300億円で買収しています。Amazonは家電部門の強化のためと発表していますが、ルンバが収集している家庭内の間取りデータが目的だとも言われています
![]()
購買履歴と突き合わせて各家庭の状況を知られてしまうのは、なんだか怖いですね。で、データの民主化の話からかなり逸れていますが
![]()
ここで話を欧州の戦略に戻したいのですが、残念ながら時間切れです。IT後進国になってしまった日本は、今後どうすれば生成AIを利用して巻き返せるかについては、申し訳ないですが次回に話しますので
続く
図版・著者:谷田部卓
AIセミナー講師、著述業、CGイラストレーターなど、主な著書に、MdN社「アフターコロナのITソリューション」「これからのAIビジネス」、日経メディカル「医療AI概論」他、美術展の入賞実績もある。
(TEXT:谷田部卓 編集:藤冨啓之)
メルマガ登録をしていただくと、記事やイベントなどの最新情報をお届けいたします。
ChatGPTとAPI連携したぼくたちが
機械的に答えます!
何か面白いことを言うかもしれないので、なんでもお気軽に質問してみてください。
ただし、何を聞いてもらってもいいですけど、責任は取れませんので、自己責任でお願いします。
無料ですよー
学びをシェアする



30秒で理解!インフォグラフィックや動画で解説!フォローして『1日1記事』インプットしよう!























データ越境者に寄り添うメデイア「データのじかん」が提供する便利ツールです。
本ツールは、JavaScriptを用いてお客様のブラウザ上で処理を行います。サーバーとの通信は行われず、入力データはお客様のみの端末内で処理されます。

































引き続き、生成AIが世界に大きなインパクトを与えていく話をします
先生は前回の最後に、”テクノロジーは、いつもカルチャーに先行する。テクノロジーは手段であって、カルチャーはその結果にすぎない”とおっしゃっていましたが、ボクには違和感のある言葉です。特にカルチャーはテクノロジーの結果だという言葉ですが、文化はその土地の気候風土から生まれるものだと思いますよ
確かに、その土地の気候や風土に文化は大きな影響を受けます。しかし、そもそも人類の狩猟文化は槍や弓矢の発明によって生まれたもので、人類が定住を始めたのは、農耕技術の発達によるものです。つまり、狩猟や農耕の技術が発達しなければ文明や文化は生まれなかったのです
まぁそこまで遡ればそうでしょうけど
現代でも、インターネットが発達してスマホが登場するなどICTがなければ、世界に広がったSNS文化は存在しません。生成AIという前例のないテクノロジーの登場によって、世界のカルチャーがどのように変貌していくかは想像もできませんが、まったく新しい文化や生活スタイルが出現してくはずです
なるほど。で、最初は何の話でしたか?
生成AIが世界を回す話です。前回、生成AIの登場によってソフトウェア技術だけでなく、自然科学分野や人文学分野まで大きく発展させるので、生成AIは世界を加速させるブースターだと話しました。また、生成AIは登場して1年も経っていないので、その応用例が非常に少ないとも前回言いました。しかし、世界の先進的企業は生成AIを利用した自社の製品やサービスを既に開発し社会実装しているようなのです
え?そうなのですか?なぜ積極的に発表しないのでしょうか
今年になって生成AIに関する論文が、毎週大量に発表されていたので、私も勘違いしていたのですが、これらのほとんどが大学の研究論文で企業からではなかったです。非営利企業だったOpenAIからは技術資料が公開されていましたが、営利企業であるビッグテックなどは自社技術を公開するメリットがないので、生成AIの利用方法を水面下では積極的に研究開発しているようです
それはそうでしょうね。Apple社は昔から徹底した秘密主義でしたから
つまり、未だに生成AIは誤答が多く未成熟な技術だからしばらく様子見しよう、などと言っている昔ながらの日本企業は、あっという間に周回遅れになるでしょう
でも先生、ICT業界のサービスや製品は、後からリリースされたものの方が常に高性能低価格でしたよ。つまり後出しジャンケンが勝つ世界なのでは?
いや、進化の激しい現代ではある程度のリスクを覚悟するアーリーアダプターであるべきです。”虎穴に入らずんば虎子を得ず”です。失敗は得難い経験値だと考えなければなりませんよ