2024年2月末、AI・機械学習関連で話題となったニュースといえば「1ビットLLM」の可能性でしょう。2月27日、『The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits(1ビットLLMの時代:すべてのLLMは1.58ビットに)』と題した論文がMicrosoft Researchと中国科学院大学の研究チームにより発表されたことがその発端となっています。
1ビットLLMとは何なのか? 具体的にどんな技術で、どんなメリットをもたらす可能性があるのか?
大きく世の中を変えるかもしれないこの技術の基本について、今のうちに押さえておきましょう。

1ビットLLMとは、0または1の2値でデータを表現する1ビット量子化を用いて学習・推論を行うLLM(大規模言語モデル)です。量子化とは、連続したアナログの数値を離散的なデジタルの数値に置き換えることであり、機械学習やディープラーニングに用いることで、メモリ消費量や計算量、それに伴う消費電力などの削減につながることは以前から知られていました。しかし、それと引き換えにモデルの精度が下がるという課題があり、8ビット、4ビットなど量子化と精度のバランスを取ることに取り組まれている状況にありました。
Microsoftは同テーマに取り組み続けており、2023年10月17日には『BitNet: Scaling 1-bit Transformers for Large Language Models』と題した中国科学院大学、清華大学の共同研究チームとの論文により、1ビットLLMでありながら精度を保つ可能性を示す技術としてTransformerにおけるnn.LinearをBitLinearに置き換えた「BitNet」が発表されました。
そして、そのバリエーションとして2024年2月末に発表された「BitNet b1.58」が、1ビットLLMに大きな注目を集めるきっかけとなります。

「BitNet b1.58」は、(0,1)の2値で重み(機械学習において入力値の重要性を数値化したもの)を量子化する「BitNet」に対し、(-1, 0, 1)の3値で重みを量子化するLLMです。1.58の由来は、平衡三進法を1ビットで処理する(log2(3)= 1.58496250072…)から。
「BitNet b1.58」は、Meta社のオープンソースLLM「LLaMA」(FP16 (16ビット浮動小数点数))に対し、一定時間内に処理できるデータ量やメモリの消費量、エネルギー消費量などにおいて各モデルサイズで優越していながら、ARC-Easy・ARC-Challenge:・HellaSWAG・BoolQ・OpenBookQA・PIQA (Physical Interaction: Question Answering)・WinoGrandeなどのデータセットを用いたゼロショット精度 (Zero-Shot Accuracy)においてひけを取らない精度を出し、大きな衝撃を与えました。
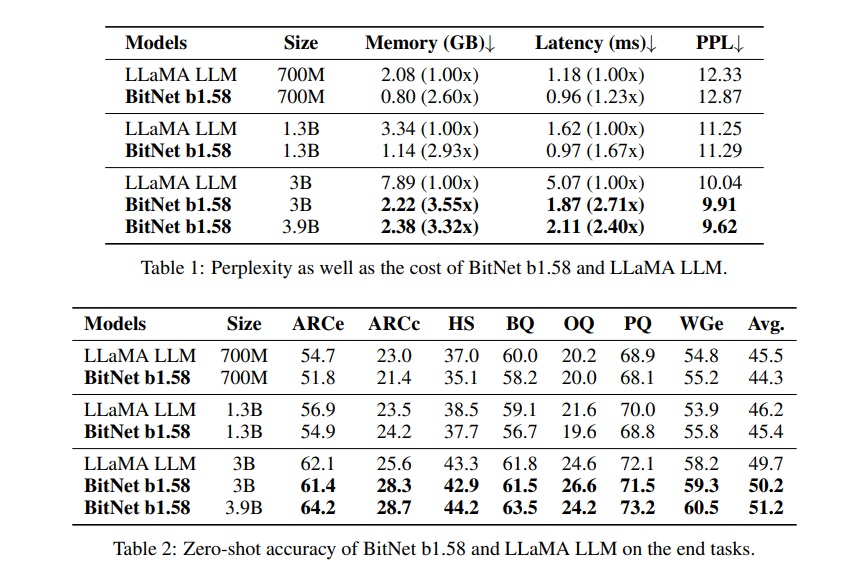
引用元:Shuming Ma, Hongyu Wang, Lingxiao Ma, Lei Wang, Wenhui Wang, Shaohan Huang, Li Dong, Ruiping Wang, Jilong Xue, Furu Wei『The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits』┃arxiv
BitNet b1.58が発表されてからほどなく、実装してみたという技術者やその報告記事が登場し、より話題は大きく広がりました。3月にはBitNetの研究チームから『The Era of 1-bit LLMs: Training Tips, Code and FAQ』と題した補足的な論文が公開されました。同論文には実際のトレーニングにおけるTipsやFAQに加え、PyTorch(Python向けの機械学習ライブラリ)における、BitNet b1.58、BitNet b1(オリジナルのBitNet)の実装方法(コード)が記述されています。

1ビットLLMに大きな注目が集まったのは、その技術的、また社会的インパクトにおける将来性に期待が持てると考えられたからです。特定のタスクに特化した複数のニューラルネットワークを組み合わせるMixture-of-Experts(MoE)、長文テキストの処理におけるメモリ消費の削減、スマホなどメモリや計算能力が制限されるデバイスでのLLM活用、1ビットLLM向けの新たなハードウェアの誕生などがその例として論文に記述されており、またLLMの消費電力による環境負荷の低減にも効果を発揮することが期待されます。
たとえば、工業製品や家電などに高精度なLLMを用いたアプリケーションが搭載され、さまざまな指示や質問に応えるといった未来も想像されるでしょう。また、1ビットLLMにより大規模な計算能力が必要とされなくなり、結果AI開発により加速したGPU不足の解決につながるという予測も語られています。
いまだ研究がはじまったばかりの技術のため、今後1ビットLLMが幻滅期を迎えることも予想されますが、深層学習におけるTransformerのような影響を与えるかもしれないと期待を集めていることは間違いありません。
2024年初頭に生成AIや機械学習界隈の話題をさらった「1ビットLLM」についてご紹介いたしました。計算能力や消費電力など、人工知能が発展するに伴ってその資源の制約は必ず問題となります。1ビットLLMはその解決につながるとともに、新たな人工知能活用の扉を開く可能性も大いにあります。ぜひ今のうちに、その仕組みと可能性を押さえておきましょう。
(宮田文机)
・Shuming Ma, Hongyu Wang, Lingxiao Ma, Lei Wang, Wenhui Wang, Shaohan Huang, Li Dong, Ruiping Wang, Jilong Xue, Furu Wei『The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits』┃arxiv・まっくす『BitNetから始める量子化入門』┃Zenn・清水 亮『1ビットLLMの衝撃! 70Bで8.9倍高速 全ての推論を加算のみで!GPU不要になる可能性も』┃WirelessWireNews・Hongyu Wang, Shuming Ma, Li Dong, Shaohan Huang, Huaijie Wang, Lingxiao Ma, Fan Yang, Ruiping Wang, Yi Wu, Furu Wei『BitNet: Scaling 1-bit Transformers for Large Language Models』┃arxiv・Matthieu Courbariaux, Itay Hubara, Daniel Soudry, Ran El-Yaniv, Yoshua Bengio『Binarized Neural Networks: Training Deep Neural Networks with Weights and Activations Constrained to +1 or -1』┃arxiv・tech-Mira『【論文丁寧解説】BitNet b1.58とは一体何者なのか』┃Qiita・ The Era of 1-bit LLMs: Training Tips, Code and FAQ┃GitHub
メルマガ登録をしていただくと、記事やイベントなどの最新情報をお届けいたします。
学びをシェアする



30秒で理解!インフォグラフィックや動画で解説!フォローして『1日1記事』インプットしよう!























データ越境者に寄り添うメデイア「データのじかん」が提供する便利ツールです。
本ツールは、JavaScriptを用いてお客様のブラウザ上で処理を行います。サーバーとの通信は行われず、入力データはお客様のみの端末内で処理されます。