



左ゲスト)株式会社Box Japan プロダクトマーケティング部 エバンジェリスト 浅見 顕祐 氏
右ホスト)ウイングアーク1st株式会社 取締役 執行役員事業統括担当 兼 CTO 島澤 甲
島澤:われわれのお客様の中にも、帳票データをBoxで管理している企業は多く、Box内のデータを活用したいというニーズがかなりあります。多くのユーザーにとってBoxは、エンタープライズ領域のドキュメント管理サービスというイメージが強く、AI技術との結びつきは想像しにくいかもしれません。そこで、BoxのAI技術に対する立ち位置から、伺えればと思います。

ウイングアーク1st株式会社 取締役 執行役員事業統括担当 兼 CTO 島澤 甲
Boxは、データストレージサービスをエンハンスする(拡張する)ためにAI技術を使っていく立場なのか、それともAI技術を生み出し、そこでリーダーシップを取りに行く立場なのか、どちらでしょうか。
浅見:使う立場です。ベンダー各社が提供するAIとBoxを組み合わせて、コンテンツをユーザーに活用していただくという観点でAIを実装していくのが基本的な姿勢です。コンテンツの活用には、具体的には①コンテンツの生成/管理、②コンテンツの検索/探索、③コンテンツの要約/理解という3つのフェーズがあり、その全域でAI技術を使っていくことを考えています。

株式会社Box Japan プロダクトマーケティング部 エバンジェリスト 浅見 顕祐 氏
島澤:2019年ごろにTransformer(機械学習モデル)が次々に登場して以降、AIの進化が加速し、昨今の生成AIへとつながっていると思います。それ以前の取り組みはどのようなものでしたか。
浅見:Boxは、さまざまなコンテンツを1カ所のクラウドサービスで集約・管理することで、ユーザーに価値を感じていただく世界観を持っています。例えばお客様が自動車メーカーで、ある原動機型式に関する動画や図面、報告書などがBoxに保存されているとします。それをすばやく検索するためには、その原動機型式を示す識別番号が「メタデータ(属性情報)」として各コンテンツに付与されていることが重要になります。そこで最初に着目したのが、Box内のファイルにAIを使ってメタデータを自動的に付与することでした。それが、2017年に発表した「Box Skills」です。
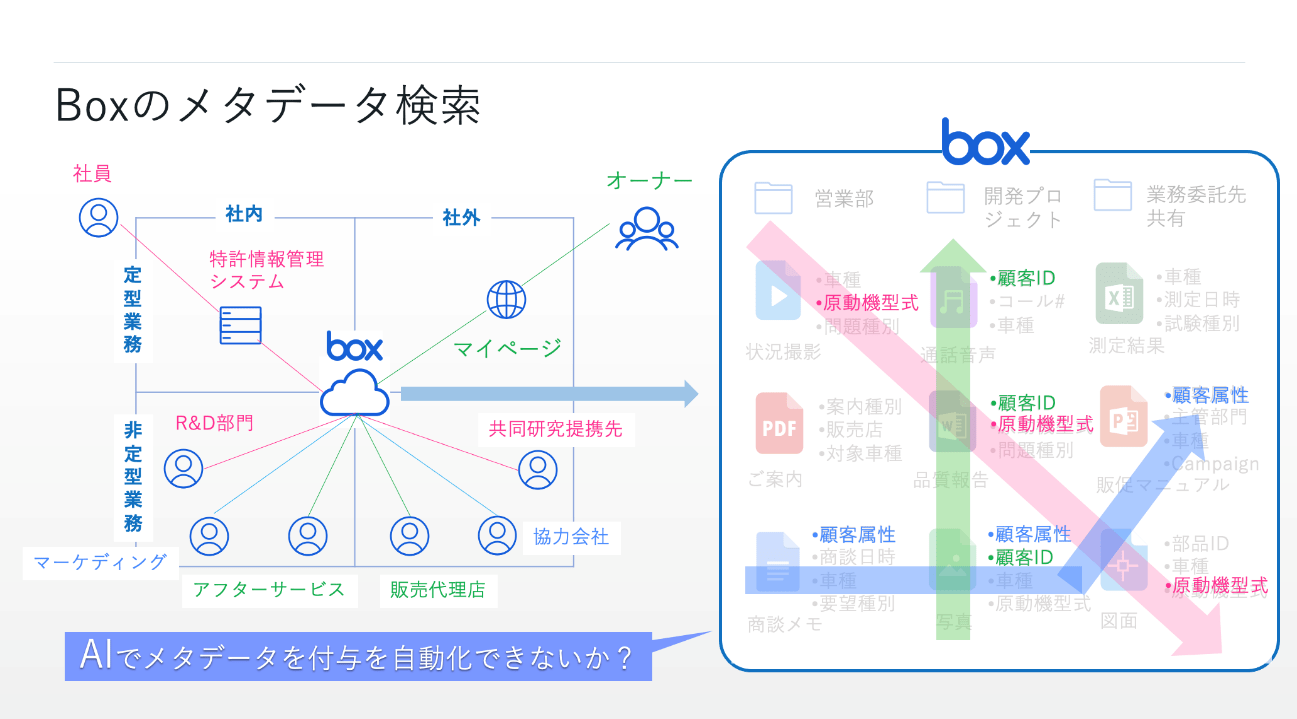
Boxのメタデータ検索の世界観のイメージ(自動車メーカーの例)。メタデータを付与することで、横串での高速な検索が可能となる。
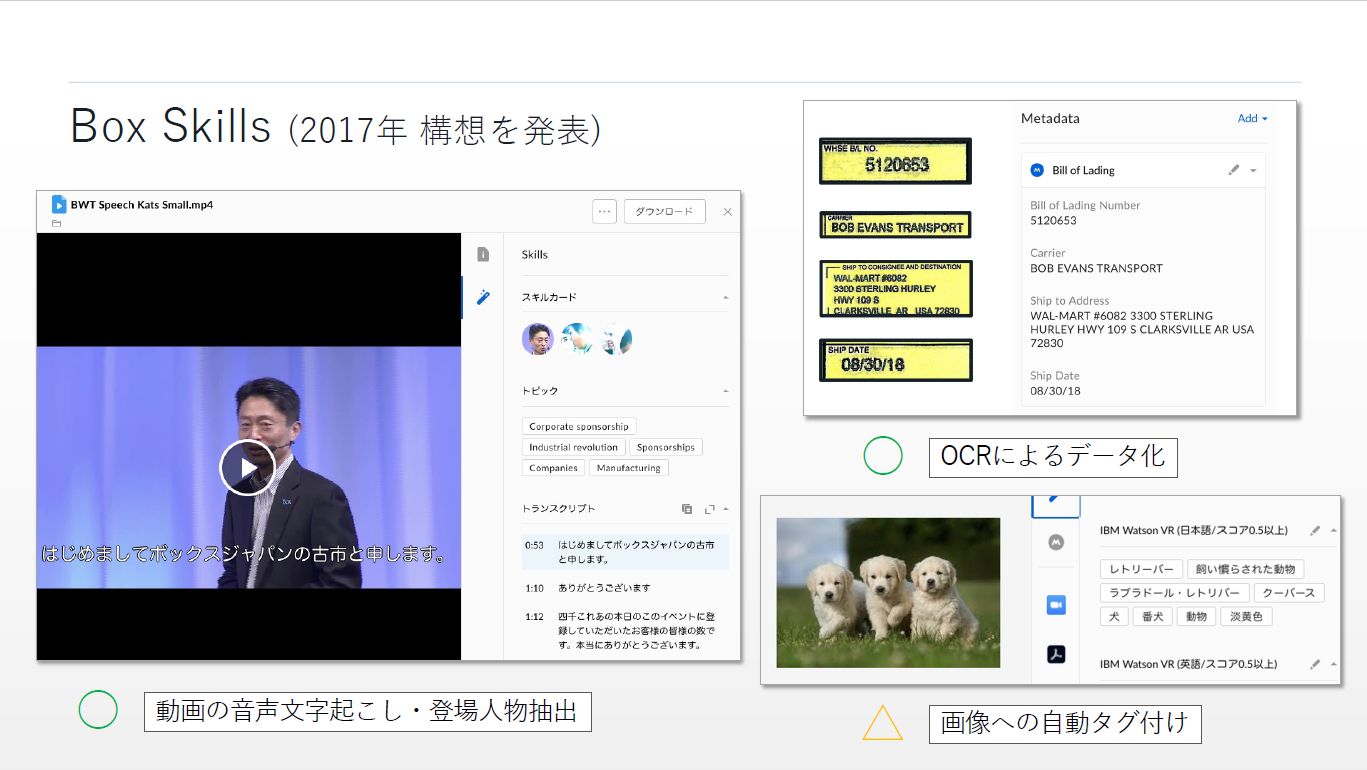
ファイルをBoxにアップロードすると、AIによりメタデータが自動で付与されるというしくみ。動画であれば、人物の登場時刻や音声の文字起こしデータ、および頻出単語など。画像や写真であれば、OCRで読み取ったデータや、被写体の情報などがメタデータとなる。
その構想の中で、「動画の音声文字起こし・登場人物抽出」「OCRによるデータ化」は想定通りのメリットを出すことに成功したのですが、課題を感じたのが「画像への自動タグづけ」でした。例えば、犬の画像に「犬」というメタデータがついたとしても、それが利便性向上につながるケースは少数です。ユーザーが本当に欲しいのは、⼀般名詞によるラベリングではなく、製品名など固有名詞によるラベリングだったのです。
もう1つ課題だったのが、「文章の要約」で、当時のAIでは、頻出単語が羅列されるだけで終わってしまっていました。実用的なものにするためには、大量の教師データによる学習が必要でした。
これらの課題から、「カスタマイズとAIの学習が必要である」という結論に至り、「Box Skills Kit」をリリースすることになりました。
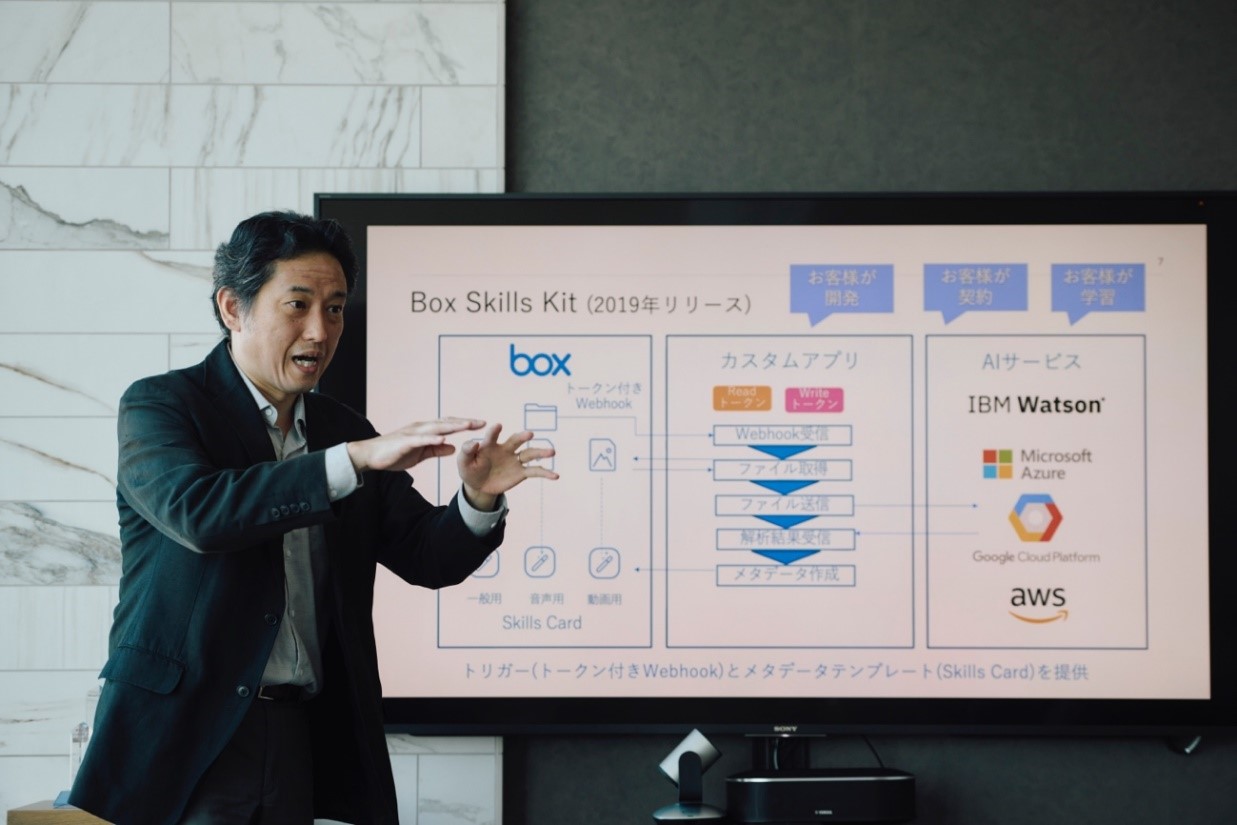
BoxとAIサービスを連携するフレームワークと開発ツールキット。サードパーティーが提供するAIサービスをBoxと連携させることで、Box上に格納された画像やオーディオ(音声)、動画などのコンテンツへのメタデータ付与を自動化できるようになる。
島澤:BoxとAIサービスをつなぐために、ユーザー自身がカスタムアプリを開発することを前提としたモデルだったのですね。
浅見:そうです。そのため、ユーザーはカスタムアプリを開発できる企業に限られ、用途も限定的でした。
島澤:私たちも、すでにウェブベースで呼び出せるAPI環境を製品ごとに提供しており、顧客に「インテグレーションすれば利用できます」と提案しますが、実際に取り組むユーザーはかなり少数派でした。でも生成AIが登場して急速に進化している現在、この部分が大きく変わる可能性があるのではないでしょうか。
浅見:生成AIが従来のAIと大きく違うのは、やはりユーザーが学習させる必要がない、カスタマイズが必須ではないという点です。そこをユーザーが理解した瞬間、使ってみようと思う層が一気に拡大すると見ています。当社としては、その層をしっかりつかんでいきたいと考えています。
もう1点、生成AIに100%の正解を求めない用途が、ニーズのストライクゾーンでしょう。例えば、文章の要約も正解が1つではないため、生成AIが生きる領域です。ユーザーとしては大まかな内容がつかめればよいのです。AIに対する期待値と、実際の効果がマッチしていることが大切だと思います。
島澤:改めて、生成AIの登場をどのように捉えていますか。
浅見:Boxにとっても、生成AIのインパクトは計り知れません。Box Skillsでは、AIといってもメタデータの自動付与とか、動画のトランスクリプトなど、限定的でした。その点、生成AIはコンテンツとの相性がよく、学習なしで使えます。この特性を踏まえると、前述した3フェーズの全ての領域で応用できると期待しています。
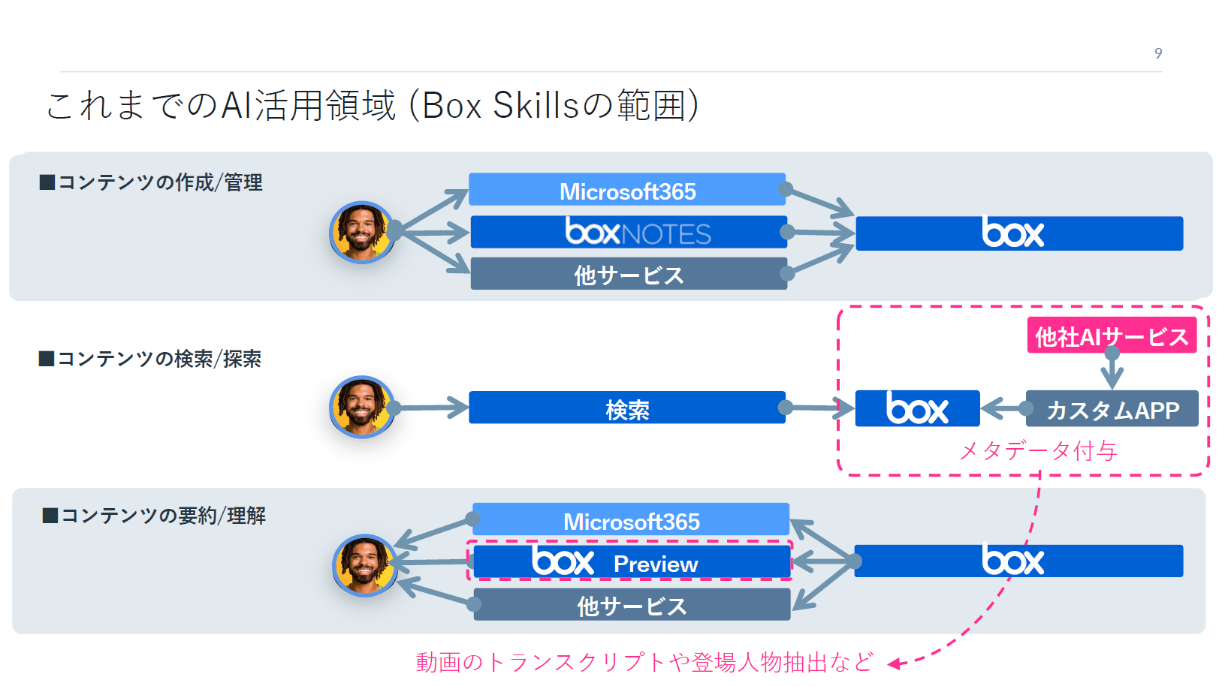
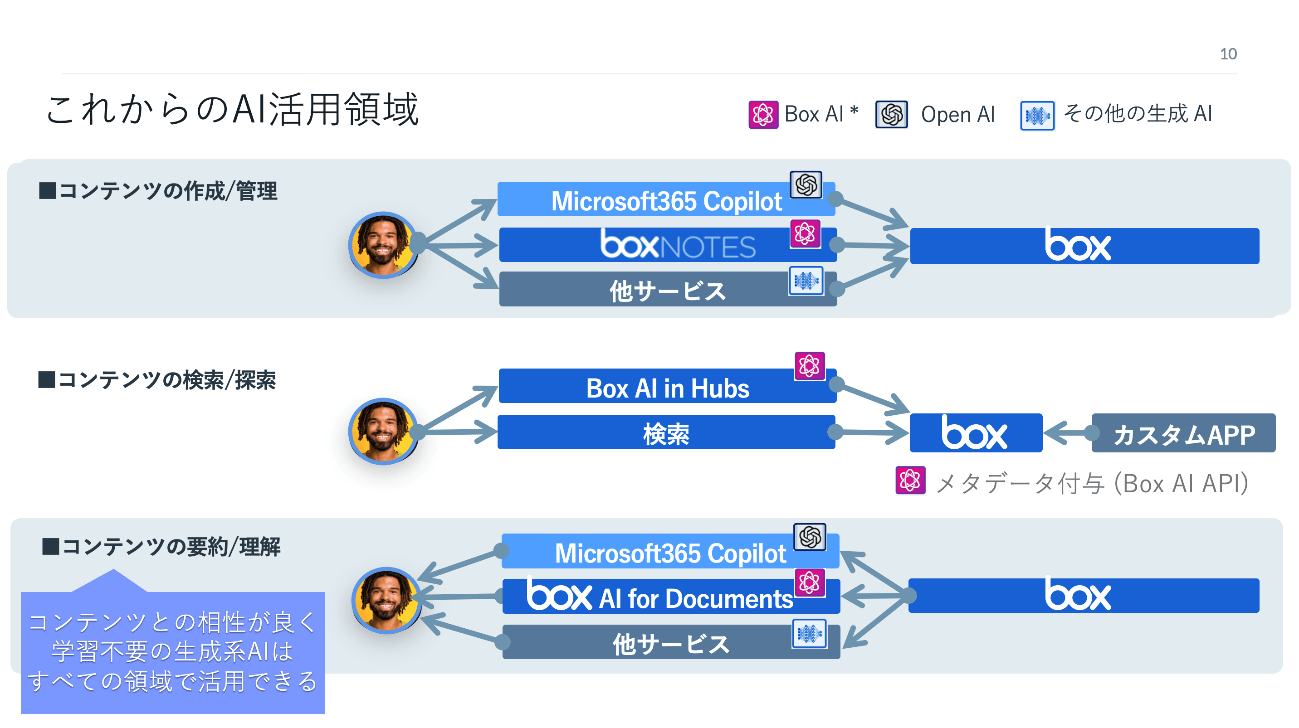
これまでのAI活用領域(上)と、生成AIが登場したこれからのAI活用領域(下)。
島澤:その具体的なサービスとなるのが、2023年5月に発表されたBox AIですね。ドキュメントの要約や文書作成をはじめ、非常に多彩な機能があると聞きました。

Box AIは、高度なAIモデルをコンテンツクラウドにネイティブ統合する強力な新機能スイート
浅見:例えば、Box AI for Documentsというドキュメントの要約・理解の機能を使うと、長文のドキュメントの内容についてAIに質問したり、AIに要約させたりすることができます。当社のCEO 兼 共同創業者のアーロン・レヴィが、日本銀行が発行した40ページくらいあるレポートの内容を理解するために利用したところ、日本語が分からないレヴィが、数分で必要な内容を理解することができました。
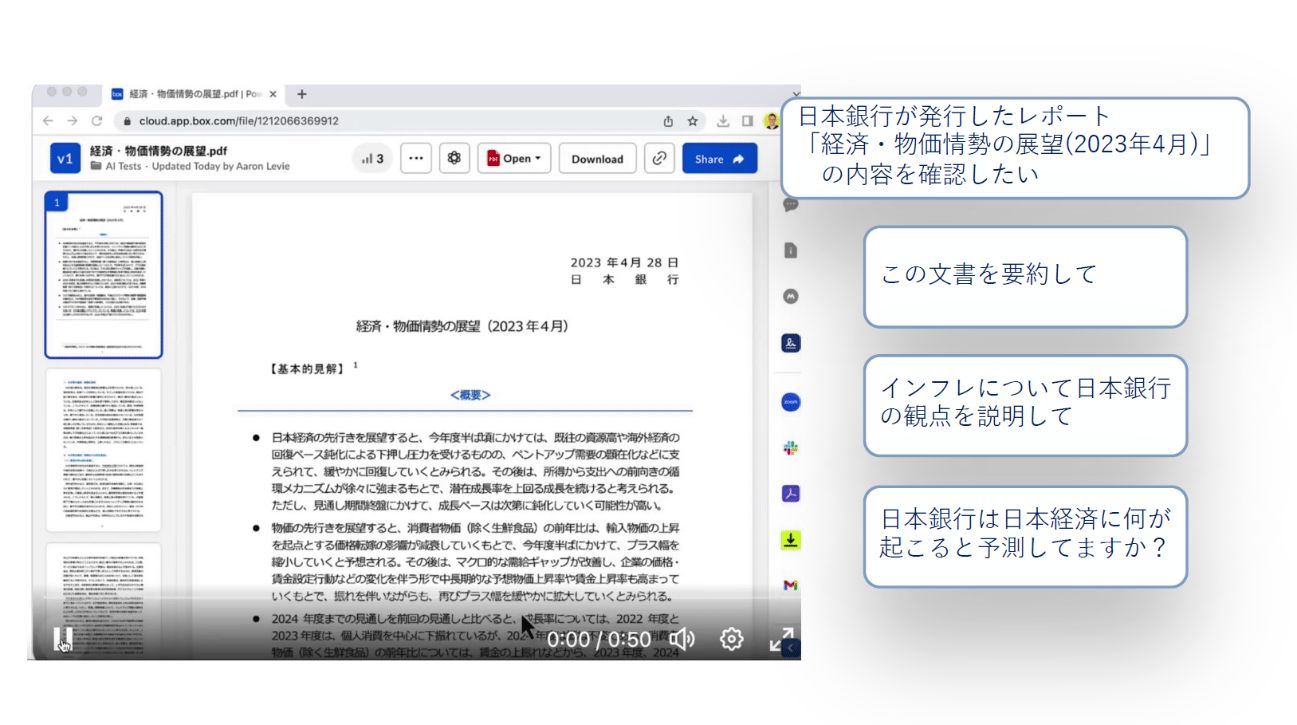
Box AIプロンプトを起動し、質問や指示を投げかけると、それに対してAIが応えてくれる
島澤:単に要約するだけでなく、ユーザーの母国語に翻訳してくれるところまで、1つのサービス上で完結できるのは、なかなかエポックメイキングですね。経営トップ自ら試されたということですが、Box Japanの社内でも活用されているのですか。
浅見:私はマーケティングが担当なので、ブログの記事のレビューなどに活用していますが、ここではBox Notesというドキュメント作成ツールを使っています。これにも生成AIが搭載されていて、例えば、ブログのドラフト文章をNoteに貼り付けて、簡潔な内容に修正するようAIに対して指示を出したり、ブログ内でフィーチャーしたい「事例カタログ」の紹介文をAIに作成させたりすることで、以前より短い時間で業務を進めることができるようになりました。
島澤:AIが生成AIに進化した結果、単純に作業効率がアップするとか、人間の負荷が減るといったことだけでなく、ドキュメントや記事制作の業務そのものが変化していく。あるいは、情報を収集・分析・理解するプロセスが劇的に効率化されて、情報から具体的なアクションまでの距離感が変わっていく期待があります。

島澤:ITベンダーのビジネスという観点からは、この先AIをどのように取り込んでいくか。また、自社のコンピテンシーとどう融合・統合していくのかは、極めて重要な課題だと思います。Boxの場合はいかがでしょうか。
浅見:かなり注力している部分です。全機能を対象にAIを用いてブラッシュアップしていくという方針に沿って、取り組みを進めているところです。複数のベンターが生成AIを提供しており、それぞれの特徴があります。どのAIモデルが適しているのかの判断も、Boxの機能として担うことで、ユーザーは意識する必要がない状態を目指しています。ウイングアーク1stも、すでにいろいろと試みているそうですが。
島澤:実は当社でも現在、OpenAIやChatGPTなどを中心にAIモデルを複数並べて、生成AIの活用に取り組んでいます。私たちの場合は、生成する対象がSQLやPythonのコードであったり、それを動的に生成してユーザーの業務に反映したりといった使い方にトライしています。
ただ、そうなるとかなり専門的になってくるので、最終的にはある程度汎用的なAIモデルで複数の領域を扱えるようにすることを目指しています。こうした汎用化や外部システムとの連携について、Boxではどうされているのでしょう。
浅見:これについては、2つの観点があります。1つ目は、Box AIを汎用的に使っていただくという観点ですが、先日、米国本社が主催したイベントで、Box AIのAPIを発表しました。これにより、Boxの画面上だけでなく、お客様のカスタムアプリケーションからBox AIを呼び出して使うことも可能となります。2つ目は、逆に、生成AIを統合した他社ソリューションとBoxを連携させる観点ですが、これは、今ウイングアーク1stとも進めているエコシステムソリューション連携で実現していきます。パートナーの生成AIの力を借りて、Boxのコンテンツの価値をさらに高めることが出来るようになります。
島澤:それは素晴らしいですね。Box AIをAPIで利用できるということは、ユーザー自身が苦労してプロンプトエンジニアリングを行う必要がなくなるわけですね。当社でも、プロンプトエンジニアリングの必要性が生じることが課題の一つと捉えており、この部分の難易度の高さが、いっそうのAI普及への壁だと考えています。そこで当社では、最初からある程度用途を絞り、AIで実現したい技術や能力を明確にした上でユーザーに提供するというアプローチをとっています。
今後は、Box単独ではなく、各々コンピテンシーを持つ多様なAIベンダーとの協業も盛んになってくるのではないでしょうか。
当社の扱っている帳票という領域では、データの整合性が厳格に求められます。このためAI OCRを行った読み取り結果も、それが正しいかどうか人の目で確認しなくてはなりません。生成AIが出てきたときに、この整合性を担保する支援の仕組みとして使えるのではないかと感じました。そうした新しいアイデア・気づきから、協業に発展する可能性は高いと考えています。
浅見:AI OCRの出す読み取り結果が、現状では正解率80%で合格ラインではあるが、それ以上の精度を求めるお客様が、自社のドキュメントに適した他社AIを使いたい場合、それをソリューションに組み込んでいけるマルチベンダー戦略なども、これから追求していきたいと考えています。
島澤:「1社のAIに縛られず、ベスト・オブ・ブリードの組み合わせをどうつくり、それを顧客の価値としてどう届けるのか」ということですね。ウイングアーク1stの電子帳票プラットフォームであるinvoiceAgentを例に考えると、私たちはinvoiceAgentで、業務の特定のレイヤーを担っているわけですが、ユーザーは、それ以外にも業務内で発生するさまざまな非定型情報を使って、トライしてみたいことがたくさんあるはずです。
しかし、例えばドキュメントの内容に応じてシステムの振る舞いを変えるといった機能を開発したくても、そもそもinvoiceAgentに文章を理解させること自体が難しいし、機械学習で精度を上げるのも簡単ではない。そこでBox AIとAPI連携させてもらえば、当社単独ではこれまでできなかったことを「できるようになりました」、とユーザーに言えるのではないかと、大いに期待しています。
島澤:現在、AI社会実装における倫理について盛んに議論されています。特にBtoB領域において留意すべき点はなんでしょうか。当社は、ユーザーの契約情報を数多く保管していることもあり、やはりセキュリティーやアクセス制御が一番の課題だと思っています。
一方では、ユーザーの情報をどこまで活用できるかが、今後のBtoBにおけるポイントになります。もちろんその中心はセキュリティーとプライバシーであり、これを押さえながらAI活用に取り組んでいきたいと考えています。その意味では、これまで個人の興味や関心に委ねられていた、コンシューマーレベルでのAI活用とは全く異なる難しさを感じています。
浅見:当社も、BtoBとBtoCの大きな違いはセキュリティーだと考えています。ビジネスユースでは、情報を使う人の立場によってアクセス権限が異なります。これはAI活用の大原則であり、最重要ポイントです。ところが現在のAIを使ったソリューションでは、情報検索をするとき、アクセス権限をかけ合わせたサーチが難しい状況です。
こうした個人ごとの権限に応じたアクセス権設定ができない現状に悩むユーザーが多くいましたが、Boxが1つの解決策を提案できる予定です。それはBox Hubsという機能で、2024年内にはβ版をリリース予定です。これを使うと、検索時には個々人のアクセス権限を踏まえて、その人がアクセスできるコンテンツだけをピックアップする、いわゆるインテリジェント検索をBox AIを使ってできるようになります。
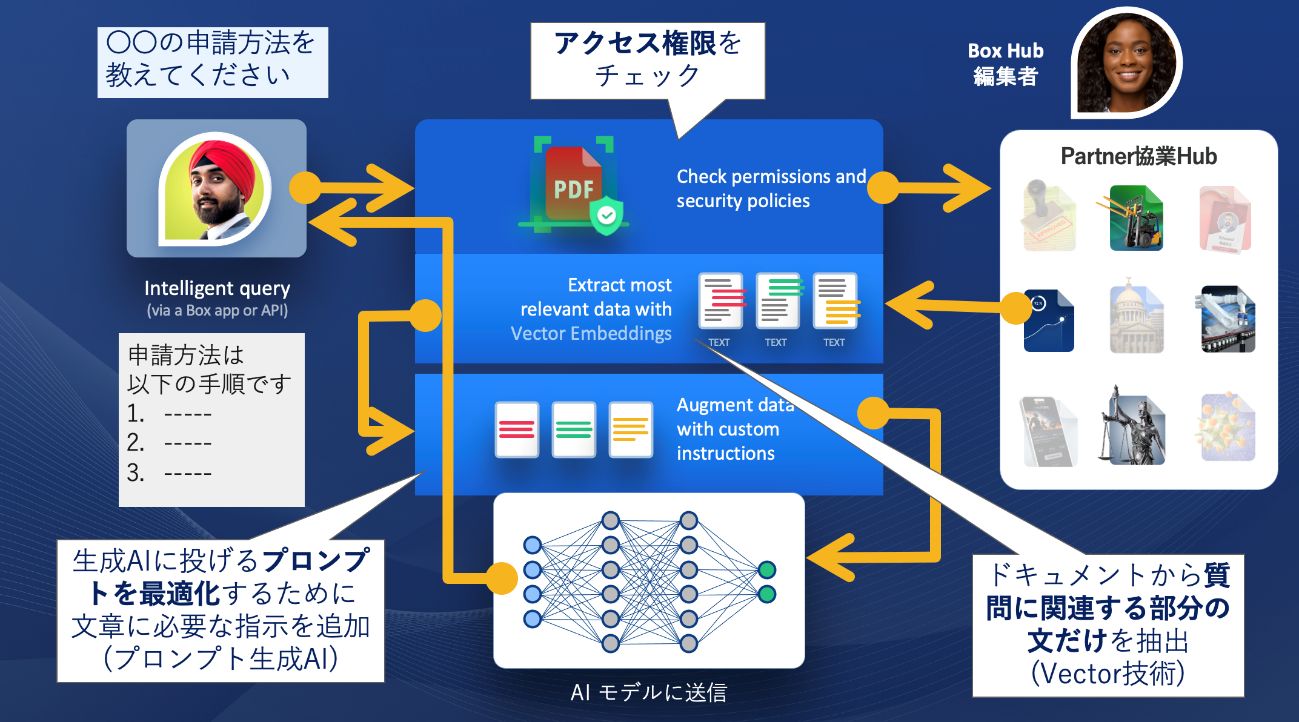
Box AI in Hubs動作イメージ。公開される全てのコンテンツは、エンタープライズグレードのセキュリティー、ガバナンス、コンプライアンス機能で保護されており、各コンテンツはアクセス権のあるユーザーにのみ提供される。
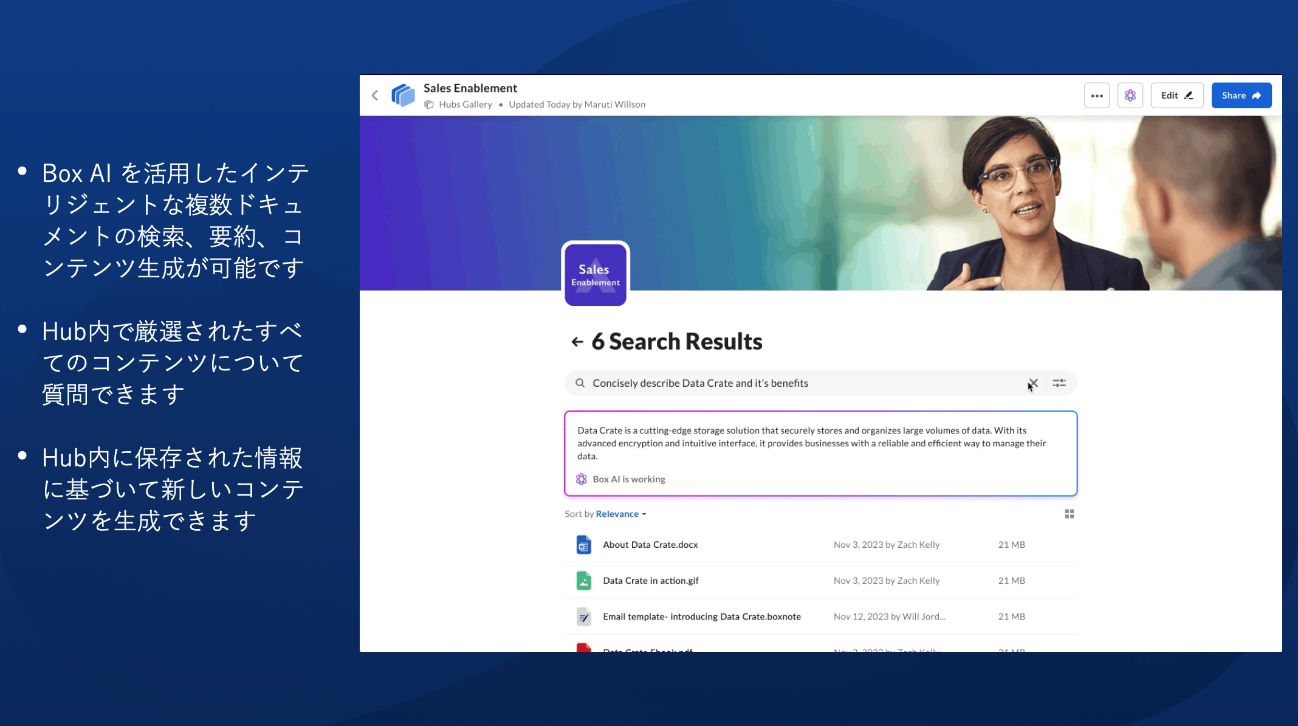
Box Hubsイメージ画面。公開される全てのコンテンツは、エンタープライズグレードのセキュリティー、ガバナンス、コンプライアンス機能で保護されており、各コンテンツはアクセス権のあるユーザーにのみ提供される。
島澤:素晴らしい機能ですね。大いに期待しています。セキュリティーをはじめ、今後はさまざまな要素技術や業務知識が広く求められる中で、より企業間のコラボレーションが必要になります。その観点でinvoiceAgentにフォーカスすると、実際のユーザーの業務オペレーションや企業間でのやりとり、あるいは法対応やルール対応などについて、当社が貢献できると思っています。
一方で、データを一元管理できるようになると、ユーザーは、データに業務以外のいろいろな役割を持たせたいと考えるようになります。そうしたデータ活用の未知数の可能性が大きくなっていく中で、Boxをはじめとしたストレージにデータを集約する流れはさらに加速していくでしょう。いわゆる「データ資産の活用」のハンドリングについて、Boxに対する期待は高まっていますし、今後、非常に明確なシナジーが生まれてくるのではないかと思っています。
例えば、当社はデータ入力のダッシュボードなど、ユーザーが直接触れるフロントエンドである「ユーザーインターフェース」に注力。一方で、入力されるデータのライフサイクル管理や権限管理はBoxに任せるといったコラボレーションが考えられます。

島澤:AIがデータやコンテンツを生成していくようになると、その量は爆発的に増えていきます。しかし、一方で使う側である人間が処理できるデータ量は、増えていくことはありません。そこで、膨大な量のデータをいかに人間が使えるようにするかが、より一層、重要になってきます。この課題に対して、われわれは構造化データのレイヤーで取り組んでおり、Boxは非構造化データのレイヤーで取り組んでいます。両社が組むことによる、シナジーにも期待しています。
浅見:同感です。これからは、構造化データと非構造化データのどちらも活用していくことが求められるでしょう。実際に活用するためには、「データの塊」を「インサイト」に変換する時間をどれだけ短縮できるかが鍵になります。必要なデータを集約した「データレイク」と「コンテンツレイク」、それに「AI」を掛け合わせることで、この時間を圧倒的に短縮できるようになるでしょう。
島澤:本日は貴重なお話をありがとうございました。
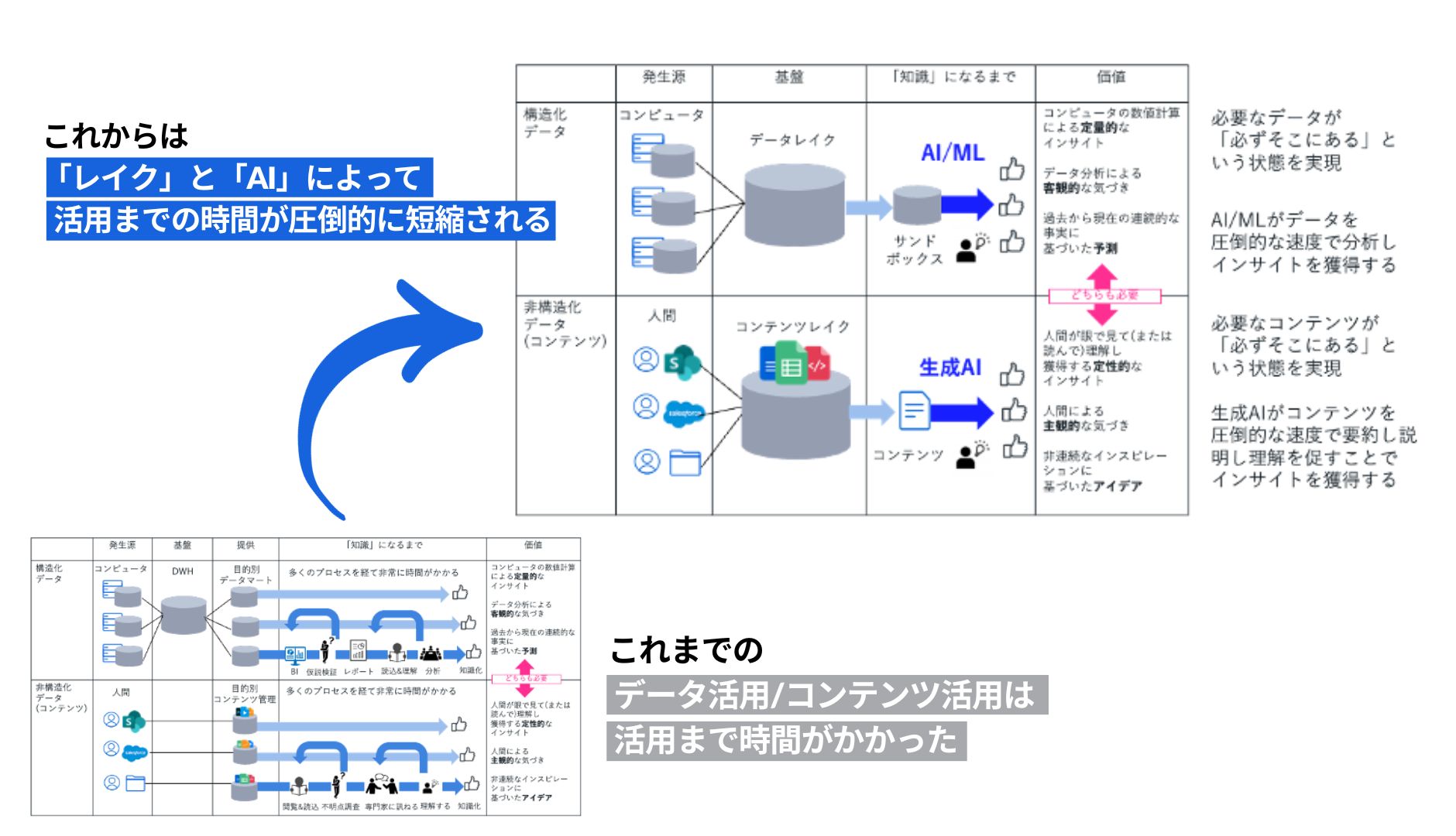
従来は、構造化データ、非構造化データともに、価値を生み出すまでに多くのプロセスと時間を要していたが、「レイク×AI・生成AI」により短時間で価値創出までたどり着けるようになる。構造化データ部分をウイングアーク1stが担い、非構造化データ部分をBoxが担う。

(取材・TEXT:JBPRESS+稲垣/下原 PHOTO:渡邉大智 企画・編集:野島光太郎)
メルマガ登録をしていただくと、記事やイベントなどの最新情報をお届けいたします。
学びをシェアする



30秒で理解!インフォグラフィックや動画で解説!フォローして『1日1記事』インプットしよう!























データ越境者に寄り添うメデイア「データのじかん」が提供する便利ツールです。
本ツールは、JavaScriptを用いてお客様のブラウザ上で処理を行います。サーバーとの通信は行われず、入力データはお客様のみの端末内で処理されます。









































