



左ゲスト)HEROZ株式会社Generative AI SaaS Division担当 執行役員 関 享太氏
右ホスト)ウイングアーク1st株式会社 取締役 執行役員 事業統括担当 兼 CTO 島澤 甲
島澤:私は学生時代に将棋ソフトをやり込んでいたこともあり、以前より「将棋×AI」の世界に関心を持っています。今回は、「将棋ウォーズ」を手がけるHEROZの関さんとの対談ということで、楽しみにしていました。HEROZといえば、やはり2013年に開発したAIが現役のプロ棋士に勝利したことが、大きなトピックだと思います。

関:間違いなくそうですね。現在は、「将棋ウォーズ」「CHESS HEROZ」「BackgammonAce」といった頭脳ゲームの開発を通じて蓄積した機械学習などのAI関連の手法をコア技術として、企業のAI活用の構想策定から実装、運用までを支援しています。しかし、いまだに「将棋の会社」という印象が強いことでしょう。
島澤:コンピュータ将棋の歴史を振り返ると、1990年代は「柿木将棋」や「AI将棋」などの将棋ソフトがあり、私もあれには勝てていました。
関:探索アルゴリズムの「αβ法」がベースだったころですね。
島澤:ところが、機械学習が導入され、将棋プログラム「Ponanza」が登場して辺りから全く勝てなくなりました。アルゴリズムベースのコンピュータ相手には、勝てるパターンが存在しました。しかし、ディープラーニングの登場によって局面の判定能力が飛躍的に向上し、人間の脳を上回り始めたのだと思います。関さんは、コンピュータ将棋の歴史をどのように捉えていていますか。
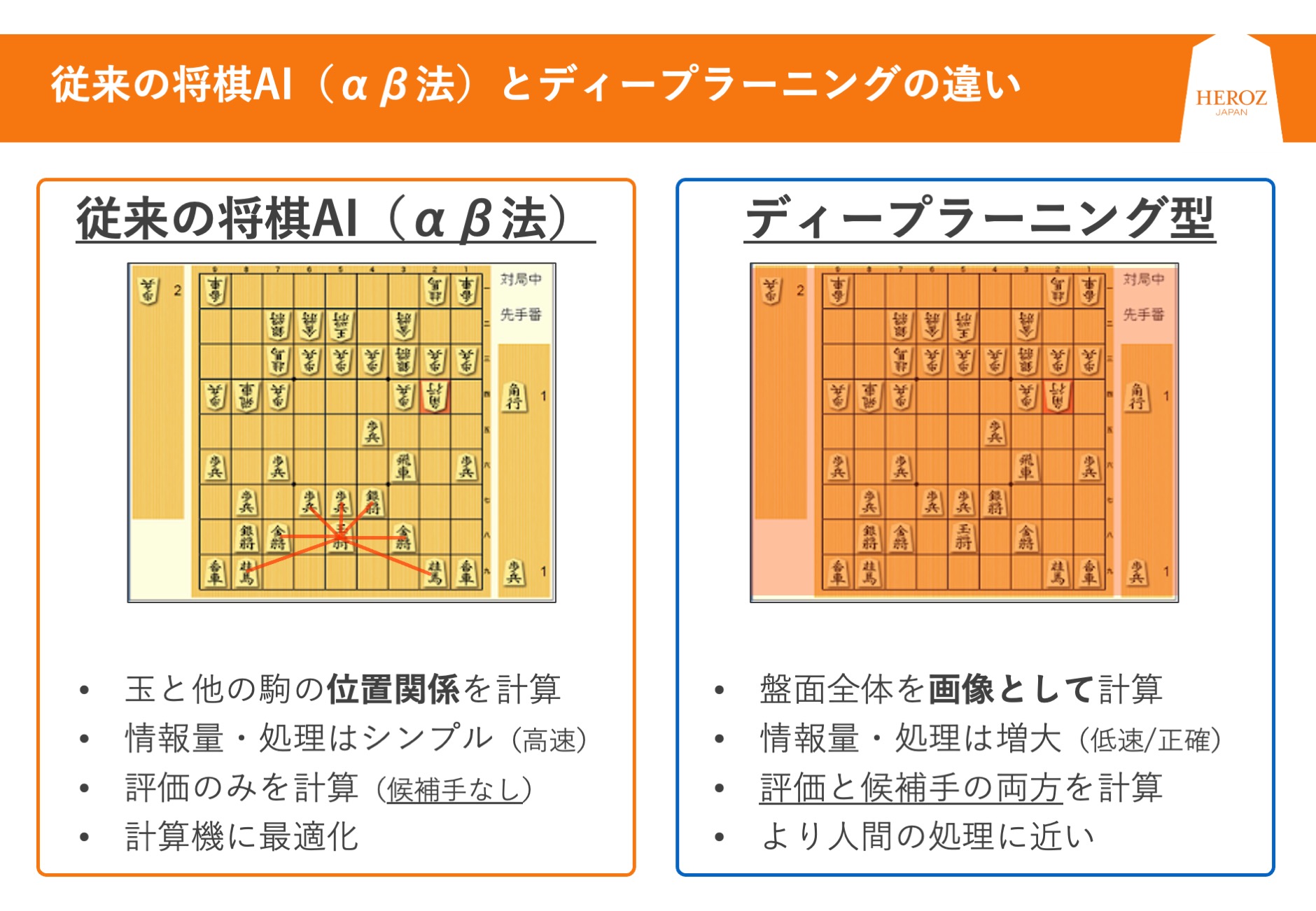
従来の将棋AI(αβ法)とディープラーニングの違い(資料:HEROZ社提供)
関:コンピュータがプロ棋士に初めて勝利したのが、確か2012年です。翌年には、山本一成さんが開発したPonanzaが佐藤慎一四段(当時)に勝利しました。これが「現役」のプロ棋士を始めて破った瞬間です。その後、2017年には佐藤天彦名人(当時)に勝利しました。これば、私がHEROZに入社する1年前の出来事ですが、将棋界に激震が走ったと聞いています。

人間とAIの「競争」の時代を経て、現在はAIと「共創」する時代に入った
島澤:2017年の対局は、私も観戦していました。探索アルゴリズムのアプローチだと、2050年ぐらいまではコンピュータは人間(名人)に勝てないと見られていました。私もこの時、「こんなに早いタイミングで人間が負けたのか」と衝撃を受けたのを覚えています。でも一方で、「人間が足し算や掛け算で電卓に勝てないのと同じだな」とも感じました。

関:はたから見ていた人によっては「AIの進化が思ったより早かった」程度のことだったかもしれませんが、将棋界は涙も出ないくらいのショックで静まり返っていたようです。
でも、当時子供でその場面を見ていた世代から、藤井聡太竜王・名人のような名棋士が誕生しています。今や若手のプロ棋士をはじめ、AIを使って学ぶのが一般的になっていて、私たちもそうしたプロ向けのサービスを提供しています。また、センスある人は将棋を覚えて1年で段位を取ってしまうような世界になってきました。
島澤:AIの登場と進化によって、将棋界のレベルが底上げされたのですね。将棋AIの開発側としては、現在のコンピュータ将棋の世界をどのように捉えていますか。
関:パワーゲーム化しつつあります。「世界コンピュータ将棋選手権」では、昨年(2023年)まで当社のエンジニアチームが2連覇してきたのですが、今年(2024年)は2位でした。Ponanzaは長らく深層学習を取り入れておらず、いわゆる探索と従来型の定跡を機械学習で覚えさせるという方法を採用していました。そこに、当社は深層学習を取り入れた「dlshogi with HEROZ」を出し、圧勝しました。でも、翌2023年にはもう深層学習は当たり前で、クラウドのリソースをフル活用してGPUをいくつつなぐかが勝敗を左右するようになりました。今では、深層学習と探索ベースのアルゴリズムを局面で使い分けるノウハウが重要になり、そこをうまくやったチームが勝率を高めている印象です。

島澤:冒頭の関さんのお話にもありましたが、 HEROZでは将棋AIの開発で培った技術やノウハウをもとに、企業のAI活用を支援されています。2024年にはエンタープライズ向けのAIアシスタントSaaS「HEROZ ASK(ヒーローズ アスク)」を発表され、本格運用を受けて、これからさらにアップデートしていかれると思います。例えば独自のLLM(大規模言語モデル:Large Language Model)を開発するなど、この先の見通しを聞かせていただけますか。
関:独自の基盤モデルは公表していませんが、いわゆるオープンソースのモデルをファインチューニングするような試みはしていました。最近だとSLM(小規模言語モデル:Small Language Model)と呼ばれている領域です。例えば、当社の顧客には金融業界や建築業界の企業が複数いるのですが、そうした業界に特化した知識を言語モデルに与えたものを提供できるのではないかという仮説を持って検証していました。しかし、あんまりうまくいきませんでした。

HEROZの取り組み(抜粋)。2021年からSaaSビジネスへのシフトを開始し、2024年にはAIアシスタントSaaS「HEROZ ASK(ヒーローズ アスク)」をリリース
島澤:そうすると、ビックテック系のLLMを使っていくことがメインになるのですね。
関:はい、その通りです。個人的な野望としては、時期を見て再挑戦したいと考えていますが、独自のLLMをはじめとした基盤モデルをつくることはないでしょう。ビックテックと同じ土俵に立ち、パワーゲームに参加しても、到底及ばないからです。では、どうするのかというと、現在の世界的な生成AIの大波に日本がただ飲み込まれないために、日本企業として地に足をつけたビジネスを精一杯やるべきだと考えています。例えば、経済産業省などでも、日本語に特化した、特定の業界のドメイン知識を持った日本独自の言語モデルを国内で開発して、活用も含めて推進していこうと取り組んでいます。私たちも、こうした「日本の生成AI」に貢献していくのが、非常に重要な使命だと考えています。
島澤:先ほど、SLM(小規模言語モデル:Small Language Model)についても、触れられました。当社のプロダクトを導入するユーザーは、実現したい目的や方向性がほぼ定まっているため、さまざまなことに対応できるLLMの柔軟性は、正直、トゥーマッチ(過剰)なことが多いんです。だからSLMで、できればある程度のポータビリティがある形で組み込みたいと考えています。HEROZはどう捉えてますか。
関:SLMの形でやるのか、もう完全にRAG(検索拡張生成:Retrieval-Augmented Generation)だけでやるのか、そこは性能がいい方をシンプルに選ぶべきだと思っています。ここ半年は、ファインチューニングするよりもRAGの方が知識をきちんと検索することはできるし、メンテナビリティーは圧倒的に高くて、ユーザー体験としてもいいプロダクトができると感じています。
| 略語 | 正式名称 | 概要 |
| LLM |
大規模言語モデル Large Language Model |
大量のテキストデータを学習して、人間のように自然な言葉を生成することが出来るモデル。OpenAIのGPT-4oやo1、Anthropic社のClaudeなどが有名。これらのモデルは、文章の生成、質問応答、翻訳など、さまざまな言語関連のタスクをこなすことができる。 |
| SLM |
小規模言語モデル Small Language Model |
LLMと比較して比較的小規模なデータセットやパラメータ数で学習・運用される言語モデル。計算リソースが限られているシステムや、特定のタスクに特化したアプリケーションで使われることが多い。 |
| RAG | 検索拡張生成 Retrieval-Augmented Generation |
文書やデータベースから情報を検索し、それを元に文章を生成する手法。言語モデルが学習した情報だけでなく、リアルタイムで外部の情報を取り込むことで、より正確で関連性の高い応答を生成することができる。主に、特定の情報を必要とする質問に対して有効。 |
LLM/SLM/RAGの比較
島澤:なるほど、その「日本の生成AI」活用をユーザー視点から見た場合、HEROZさんとしては生成AIを通じて、どんな顧客体験を提供していきたいとお考えですか。
関:いろいろなお客様とお話ししていると、大企業は情報システム部門を筆頭に、積極的に生成AIを導入する準備を進めていて、当社もお手伝いをさせていただく機会が増えています。一方、中小企業は、「ChatGPTは知っているけど……」くらいで止まっている方が多い印象です。本当は、中小企業ほどAIやデジタルを使って生産性を飛躍的に上げていく必要に迫られているのだから、私たちはもっとそちらに貢献するべきだという気持ちがあります。
そういう意味で、企業規模の大小を問わず日本全体の生産性を確実に向上させていくために、いかに生成AIをセキュアに、かつ専門的な知識がなくても使えるようにしていくか。これは、かなり重要な論点だと思います。
島澤:「HEROZ ASK」などは、まさにそこを意識したプロダクトになっていますが、どのような活用の仕方をされているのか、具体的な例を聞かせていただけますか。
関:例えば建設業の場合、他の産業にも増して少子高齢化が進んでいて、若手に技能継承をしなくてはいけないのに、その伝えるべき暗黙知が、どこにあるか分からないという大きな課題を抱えています。そうした中で、あるお客様をHEROZ ASKの開発前から個別案件でお手伝いしました。

見習い中の若手社員が新しいプロジェクトに配属されて、建物を設計するよう命じられたのですが、どこから手をつけていいのか分からない。そうした時に、社内に蓄積されている何百何千という建築設計データから、今回の要件に近い建物をAIがピックアップして、その理由とともに可視化するようにしました。
島澤:若手技術者にとっては、「手取り足取り」のサポートですね。日常の仕事をアシストしながら、同時にナレッジの継承もできるという点で、建設業だけでなく製造業など、日本のものづくりの成長に大いに貢献できるのではないでしょうか。
島澤:「HEROZ ASK」には、「AIアシスタントSaaS」という名称が与えられていますが、その機能の特徴や解決が期待できるユーザー課題などについて、もう少し詳しくお聞かせいただけますか。
関:基本的な機能としては、ChatGPTと会話しながら、業務に必要な情報の検索や文章の要約、作文や添削、あるいは情報の管理などが行えます。またエンタープライズ向けのサービスですから、セキュリティも重要です。その点、「HEROZ ASK」はAzure OpenAI Serviceを用いて構築しているため、いつでもセキュアに使えるという点が、第1の特徴です。
第2の特徴は、業務に合わせてChatGPTのRAG環境を非常に簡単につくれる点です。例えば、一般的なChatGPT関連のサービスであれば、求人票作成を行う場合、サンプルの求人票をデータ登録しておいて、「この求人票の中から候補者に対して魅力的なワードを抽出してください」などと指示を出すのですが、このChatGPTに指示を出すことや、目的に合わせて会話を切り出すことが、意外と手間であったり、難しかったりするようです。その点、HEROZ ASKは、特定の業務を推敲する際に、こちらから会話を切り出さずに、HEROZ ASKのインストラクションに沿って操作していけばいいようになっています。
島澤:生成AIで何をするのか、目的を明確に定めて使える人が、まだ少ないということですね。
関:深層学習ブームが始まった2018年頃は、大企業ではDX やAI導入にどんどん予算がついていました。しかし残念ながら、DX やAI導入が目的化していました。2023年からの生成AIブームにも、同様の懸念があります。

島澤:同感です。やはり最初に明確な目的があり、そこにAIを手段としてどう落とし込んでいくかという議論になるべきだと思います。ここまでお話を伺ってきて、「HEROZ ASK」もユーザーのやりたいこと(目的)を起点としてサービス設計しているのが、よく分かりました。
島澤:最後に、今後の展望についてお教えください。
関:先ほどお話したように、私たちは特に中小企業の方たちがAIを使って飛躍的に成長するのを支援していきたい。その意味で、AI初心者に刺さるような、徹底的に使いやすく、ユーザー数も1人から使えるサービスを展開していきます。
もう1つは、業種や業務に特化したデータを生成AIに取り込み、「本当に仕事に使える」AIツールを提供していきたいと考えています。例えば建築業界などは、無数のドメイン知識が日本中に眠っているはずで、それらを何らかの形でユーザーが自分で活用できるようなサービスをイメージしています。
島澤:「The Data Empowerment Company」をスローガンにしている当社としても、大いに共感する展望です。どこかに眠ったまま存在しているデータを、ユーザー自身が目的に応じて使える仕組みがあれば、おのずとその情報やナレッジはユーザーの中で組み合わされ、有益なものになると思います。
これからもHEROZと関さんの挑戦を追いかけさせていただきます。私たちがお手伝いできることがあれば、ぜひお声がけください。本日は貴重なお話をありがとうございました。

今回の対談はウイングアーク1stが開設したイノベーションラボ「D.E.BASE」で行われた。

(取材・TEXT:JBPRESS+稲垣 PHOTO:Inoue Syuhei 編集:野島光太郎)
メルマガ登録をしていただくと、記事やイベントなどの最新情報をお届けいたします。
ChatGPTとAPI連携したぼくたちが
機械的に答えます!
何か面白いことを言うかもしれないので、なんでもお気軽に質問してみてください。
ただし、何を聞いてもらってもいいですけど、責任は取れませんので、自己責任でお願いします。
無料ですよー
学びをシェアする



30秒で理解!インフォグラフィックや動画で解説!フォローして『1日1記事』インプットしよう!























データ越境者に寄り添うメデイア「データのじかん」が提供する便利ツールです。
本ツールは、JavaScriptを用いてお客様のブラウザ上で処理を行います。サーバーとの通信は行われず、入力データはお客様のみの端末内で処理されます。








































