



![]()
まずはDeepSeekが公開した大規模言語モデル「DeepSeek-R1」の3つの大きな特徴を確認しましょう。
特徴①オープンソースとして公開した
特徴②コーディングやSTEM分野に対してOpenAI並みの強力な推論能力がある
特徴③低コストで開発し低コストのAPIでサービスを提供している
![]()
うーん、箇条書きにするとアメリカによくあるAIスタートアップの宣伝文句としか思えませんね。
![]()
そうでもないですよ。似たような性能のAIの発表だけなら他にもいくつかありますが「実際にAPIを公開して誰でも無料で試せる推論AIのサービス」はほとんどありません。今回株価が過剰ともいえる反応を示したのは、AIテクノロジーに疎い大勢の人たちが、スマホで数回使っただけで騒いだからだと思っています。DeepSeek-R1のキーとなる技術は、2024年8月の論文で発表されていますが、AI技術者の間でしか評判になっていません。また2024年12月に公開されたDeepSeek-V3テクニカルレポートで、トレーニングコストの低さや推論性能が「o1」より高いことを示していましたが、株式市場では無視されています。
![]()
そうなんだ。まぁ研究者が書いた論文なんか、専門家以外は読みたくもないですからね。
![]()
ではまず、オープンソースという特徴ですが、ご存じのようにAI業界ではよくあります。なぜこれを「特徴」として取り上げたかというと、中国のAIスタートアップとしてはおそらく初めてだからです。中国のAI企業のほとんどがMetaのオープンソースLlamaをそのままコピーして使用しています。しかしDeepSeekの梁CEO はインタビューで以下のように語っています。
中国は過去30年以上にわたるITブームの中で、技術革新にただ乗りしてきた。しかし我々は技術革新の貢献者になるべきだと考えている。このためにAIモデルのアーキテクチャをイノベーションする取り組みに挑戦し、成功させる側に回る
![]()
上記の発言を踏まえると、オープンソースにしたのは、ゼロからソースコードを書いているという表明と受け取れますね。
![]()
でもオープンソースにしたら、あっという間にコピーされますよ。
![]()
OpenAIのGPTなど最近のAIは、オープンソースにしていませんが、それでも他社との技術的優位差はせいぜい数か月から半年程度です。DeepSeekみたいな名もない中国企業の場合、まず注目されることを最優先にしたからでしょう。この戦略は見事に成功しました。それでは次の特徴②「強力な推論(reasoning)能力」についてです。
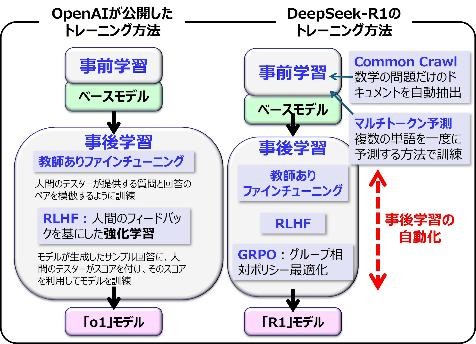
※図版:筆者作成「LLMトレーニング方法の違い」
![]()
ただ、この特徴②と特徴③低コスト開発はセットなので、この図を用いて説明します。なお図では、LLMに基本的な学習(事前学習)を済ませたAIモデル(ベースモデル)に、事後学習つまりAIアライメント(トレーニング)をメインに描いています。
![]()
あれ?この事前学習が最も時間と費用がかかって、LLMとしての能力が決まるんじゃないんですか。
![]()
その通りです。OpenAIの創業者Karpathyは、2024年のMicrosoft Buildで「AIモデルの事前学習は作業全体の99%、そしてコストの大部分を占めている」と発言しています。今までNVIDIAの株価が急上昇してきた理由もそこです。しかしMetaの高性能なオープンソースLLMであるLlamaシリーズは、事前学習済みで小規模モデルから大規模までモデルまであります。つまりベースモデルならだれでも簡単に入手できるので、ここでは省略しました。
![]()
さっきDeepSeekのCEOはLlamaを使っていない、と説明したじゃないですか。
![]()
あの発言は、Llamaが開発したLLMネットワークのことだと思います。莫大な費用と時間のかかる「学習済みデータ(知識)」は、(まだ推測ですが)どこかのLLMから「蒸留(Distillation)」によって移行したものだと考えています。
![]()
だからOpenAIは、DeepSeekを疑って調査しているのか。
![]()
話を進めますが、図の左側はOpenAIのトレーニング方法と書いていますが、今では多くのAI企業で標準的に用いられているLLMのトレーニング手法です。以前、この講義でもChatGPTの学習方法として説明しています。右側は「DeepSeek-V3 Technical Report」などで公開している情報を基に、私が模式化したDeepSeekのトレーニング手法です。
![]()
なるほど。こうやって比較すると、DeepSeekがトレーニングの自動化によって、開発費用を削減したことが一目で分かりますね。でもAI業界で最先端のはずのOpenAIが、いまだに人海戦術でトレーニングしているんですかね。
![]()
図ではOpenAI の手法と書きましたが、現在OpenAI はオープンソース化を止めて、論文や具体的手法などは非公開です。ですから左の図はChatGPT発表時の情報を基に模式化したものなので、数年前の情報になります。つまり、毎週のように画期的AIテクノロジーを発表しているOpenAIなら、DeepSeek が公開しているトレーニングの自動化手法は、(※憶測ですが)既に研究開発済みだと思っています。
![]()
ちょっと待ってください! じゃあ、DeepSeekはOpenAIのAI開発費用より十分の一以下とか喧伝してましたが、DeepSeekは最も費用と時間のかかる事前学習はコピーですまして、トレーニングの自動化はOpenAIと同程度だったら、AI開発費用の実態はほとんど同じじゃないですか。
![]()
そうかもしれませんね。あくまで憶測と推測に過ぎませんが。
![]()
本当ですかね。にわかには信じがたいですが、でもNVIDIAの株価は下落したままですよ。
![]()
高額なNVIDIAの最新GPUを大量に必要なのは、主に事前学習だからです。事前学習がコピーで済むなら、当初の予測ほどのGPUは不要になるかもしれないと市場が考えているからでしょうね。
![]()
しかしOpenAIはトレーニングの自動化みたいな画期的手法を、なんで公表しないんですか?
![]()
AIテクノロジーはあまりに競争が激しいので、AI企業は詳しい手法を公開しなくなりました。OpenAIの推論AI「o1」の仕組みを、以前この講義で説明しましたが、あの情報はOpenAIの公式情報からではなく、研究者へのインタビュー記事を基に書いたものです。それでも「o1」の発表後わずか数か月で中国企業が同程度の性能の推論AIを発表しています。OpenAIはDeepSeek-R1の発表後わずか10日で、より高度な推論AI「o3-mini」をリリースしています。もちろんこれはOpenAIの優位性を誇示して、市場のDeepSeekショックを抑えるためです。
![]()
まさにレッドオーシャンの世界なんですね。それで、DeepSeekの推論方法は「o1」と同じなんですか?
![]()
申し訳ないですが、今回の講義が当初の想定より長くなったので、DeepSeekの話は次回に持ち越します。
【後編に続く】
・低コストの開発費で高性能なAIサービスを始めた中国のDeepSeekの登場は、AI開発に必須の高性能GPUのメーカーNVIDIAの株価を大暴落させ、DeepSeekショックと呼ばれている。
・特徴は、OpenAI並みの強力な推論AIをオープンソースにし、低コストのAPIサービスと無料のスマホアプリで提供したことにある。
・技術的特徴は、トレーニングに手間と時間がかかる事後学習を、自動化させたところにある。ただ最も費用のかかる事前学習は、OpenAIの知識データをコピーしたと疑われている。
著者:谷田部卓
AIセミナー講師、著述業、CGイラストレーターなど、主な著書に、MdN社「アフターコロナのITソリューション」「これからのAIビジネス」、日経メディカル「医療AI概論」他、美術展の入賞実績もある。
(TEXT:谷田部卓 編集:藤冨啓之)
メルマガ登録をしていただくと、記事やイベントなどの最新情報をお届けいたします。
学びをシェアする



30秒で理解!インフォグラフィックや動画で解説!フォローして『1日1記事』インプットしよう!























データ越境者に寄り添うメデイア「データのじかん」が提供する便利ツールです。
本ツールは、JavaScriptを用いてお客様のブラウザ上で処理を行います。サーバーとの通信は行われず、入力データはお客様のみの端末内で処理されます。




































先生!DeepSeekとかいうAI企業のせいで、アメリカの株価が大暴落しましたが、どこがそんなに凄い企業なんですか?
おや、やっぱりそこが気になりましたか。2025年になりソフトバンク孫会長がトランプ大統領の隣でStargateプロジェクトを発表したり、日本や韓国でサム・アルトマンCEOと一緒にクリスタル・インテリジェンスやStargateを発表したりと大忙しです。昨年までAI界隈だけの騒動だったのが、今や怒涛のように世界全体のビジネスを巻き込んでいます
前回、「2024年はお祭り騒ぎ!」って振り返ったばかりなのに。2025年は後夜祭どころの騒ぎではなくなりましたね
本当ならばこの講義では世界のAI規制について説明するつもりでしたが、世界的に関心を集めたDeepSeekについて現段階で分かっている範囲になりますが説明しましょう。
しかしDeepSeekショック直後と、その1週間後では、かなりDeepSeekに対する評判が変わりましたね。
まず、なぜ飛ぶ鳥を落とす勢いだったエヌビディア(NVIDIA)の株価が、一夜にして17%も大暴落した理由を、サルくんは知っていますか?
いろんなメディアによると、OpenAIなんかのAIを使うには大量のNVIDIAのGPUが必要なのに、DeepSeekのAIだとほとんど不要になるから、と書いてましたよ。それにしてもSoftbankなんかは、AIのインフラに80兆円もの大金をアメリカで投資するとか言ってますが大丈夫なんですかね。
孫会長は今までにも大言壮語を繰り返してきましたが、結果として大半は成功したので、今でも生き残っています。それにしても$500Billion つまり5000億ドルとは、いかにバブリーなアメリカでもさすがに驚いていますね。とりあえずAI投資の評価に関しては株式市場に任せて、ここではDeepSeekのテクノロジーのどこが優れているのかを説明しましょう。1月20日に発表されたのは、推論AIであるDeepSeek-R1ファミリーです。最初にその特徴をまとめます。