



※図版:著者作成
![]()
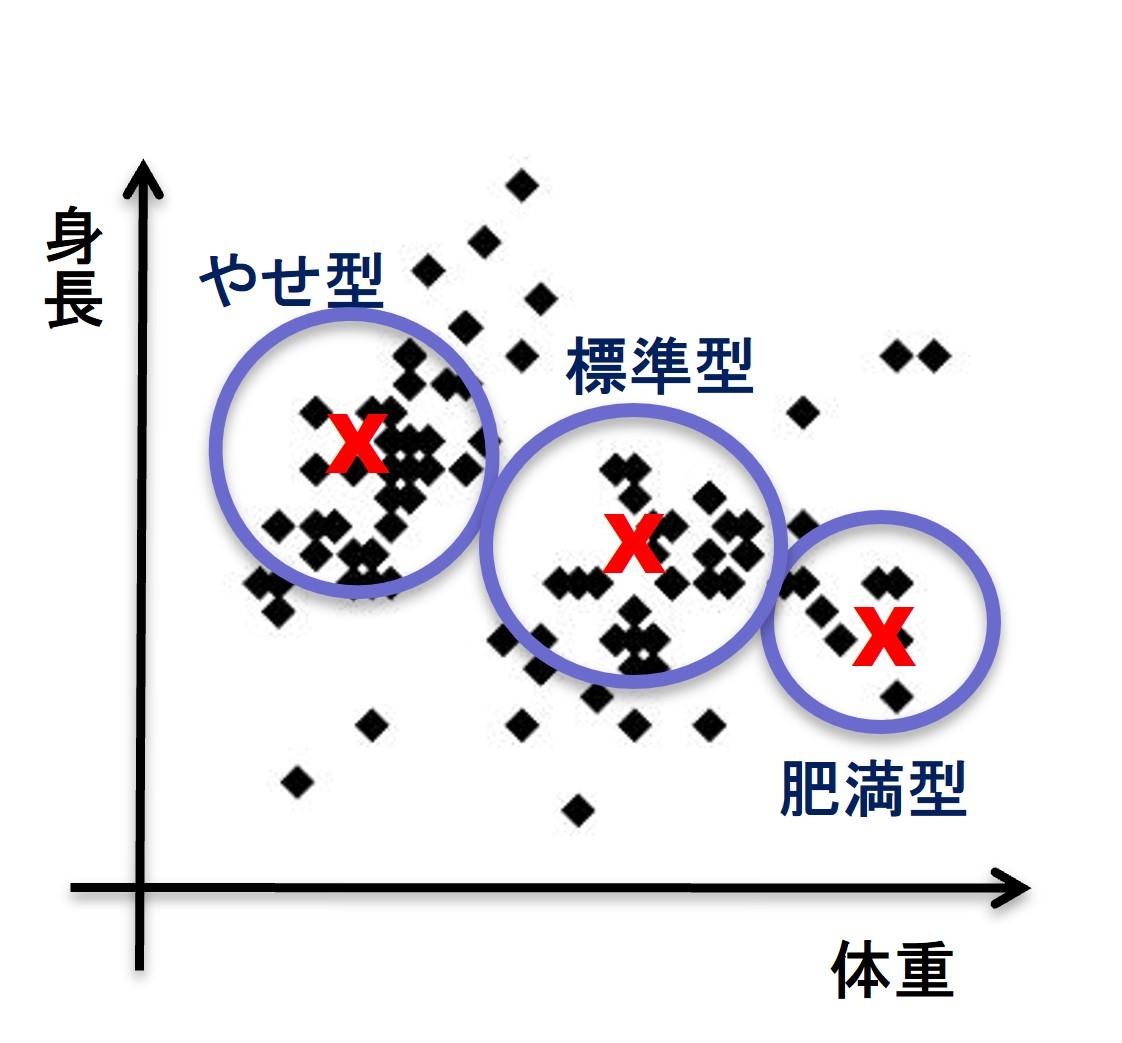
これは、ある学校で生徒の身長と体重を、グラフ上にプロットしたものです。多くの生徒がいるので、グラフではバラバラになりますが、大雑把に分類して丸で囲むとやせ型・標準型・肥満型と分けられますね
![]()
まぁかなり無理がありますが
![]()
この分類した丸の中心点に赤い×印を打ってあります。やせ型の中心点と標準型の中心点の距離はいくつですか?
![]()
身長の差と体重の差なら各々分かります。しかし単位が異なるので直接の距離は表現できません
![]()
例題があまり良くないので、それが正しい意見なのですが、各軸の尺度を標準化することで、各データ間の距離が比較できます
![]()
どうやってですか?
※図版:著者作成
![]()
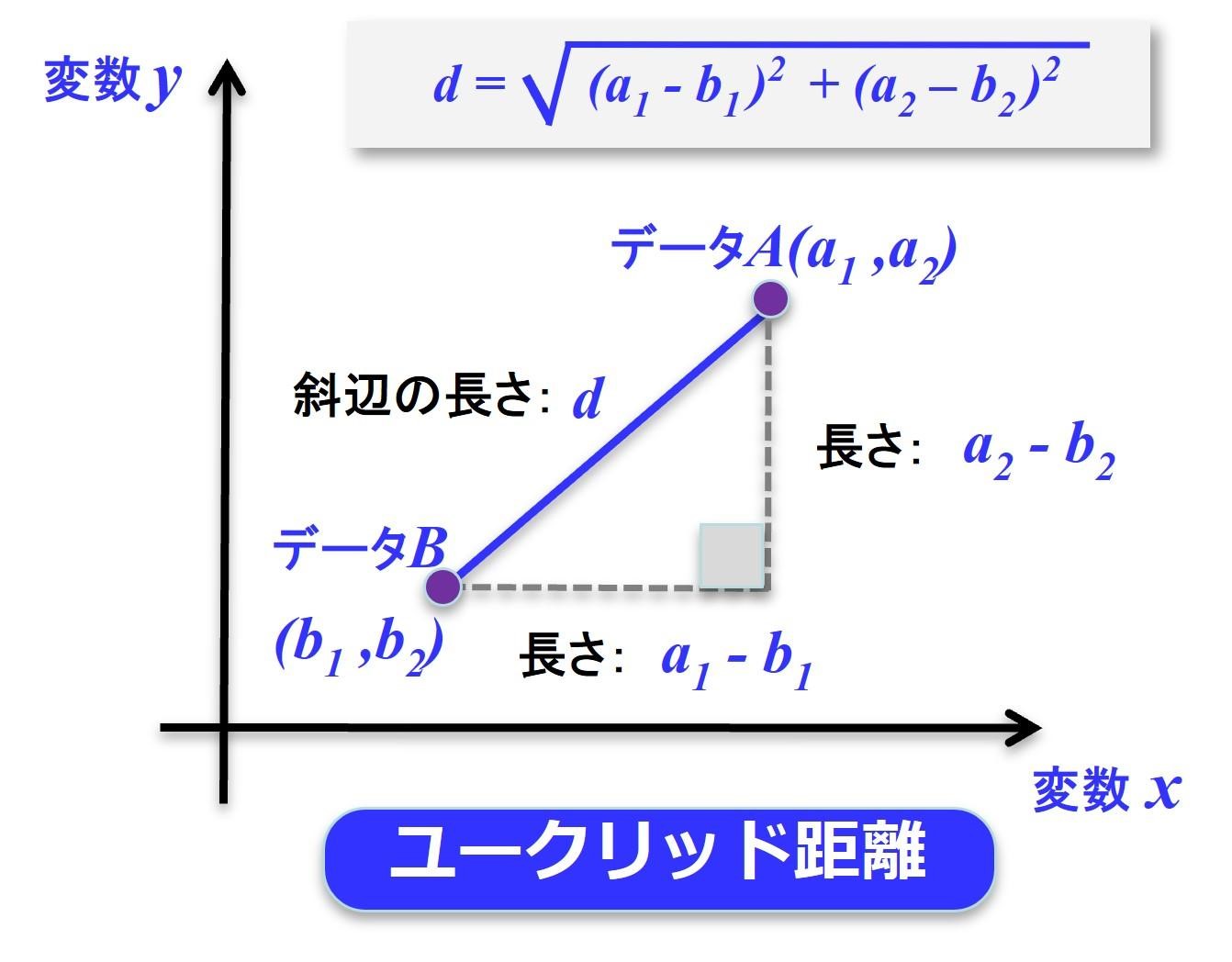
図にあるようにデータAとデータBの距離dは、ピタゴラスの定理で簡単に計算できます
![]()
中学で習った三平方の定理のことですね
![]()
そうです。このデータ間の距離をユークリッド距離と呼びます。データ解析において最も基本的な考え方になります。データ間の距離を表す方法には、他にもありますが、長くなるのでここでは省きます
※図版:著者作成
![]()
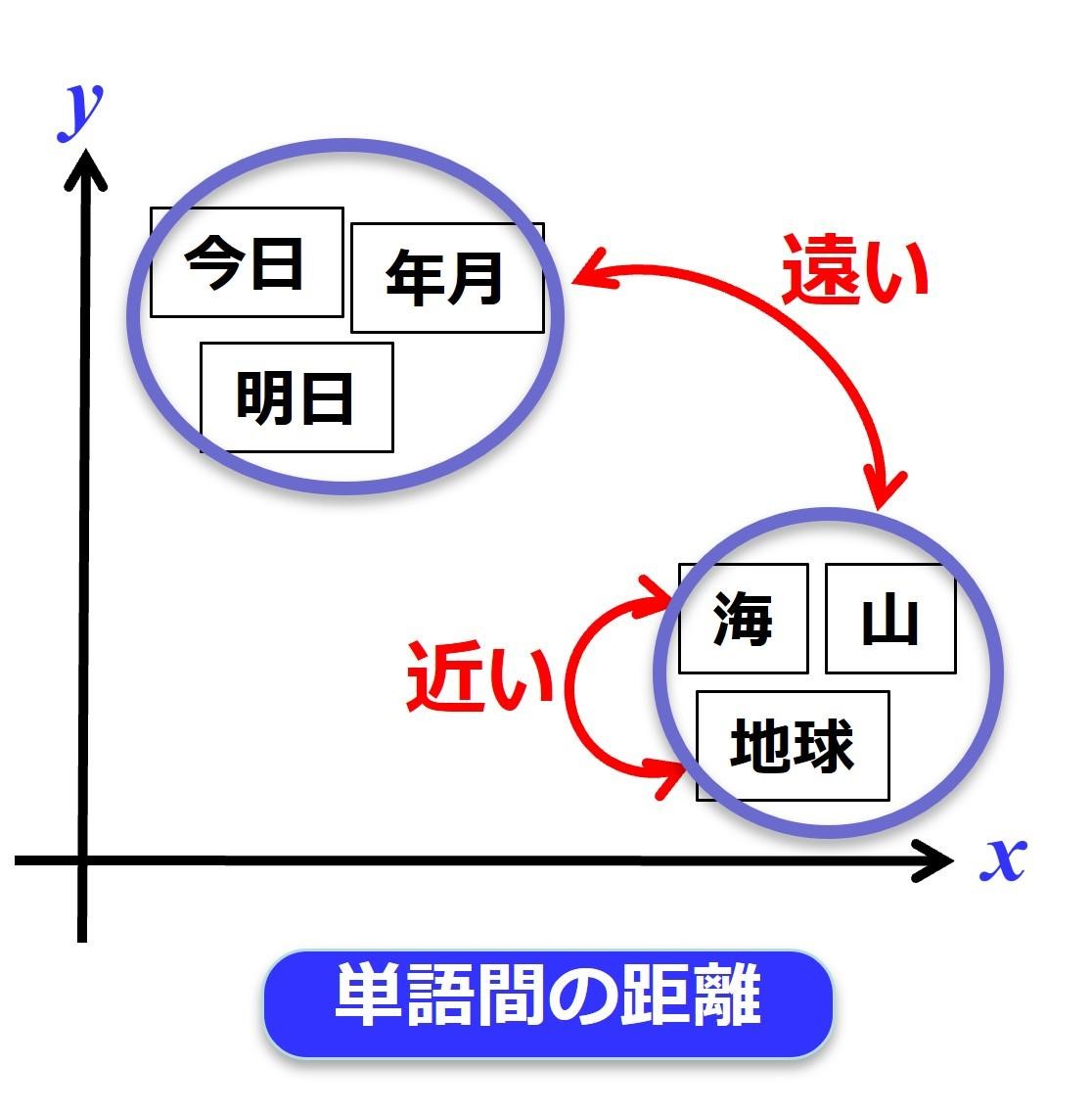
では、次に言葉をデータとして扱う場合の考え方になります。図のように、今日・明日・年月という言葉と、海・山・地球のような言葉があるとします。この場合、今日・明日・年月という言葉同士は意味が近い言葉のグループとして括れます。しかし海・山・地球という言葉のグループとは、意味が離れていると考えられますね
![]()
まぁ無理やり感がありますが、グループに分けるならば直感的にはそう思います
![]()
これを単語間の距離としましょう。もしこのように、単語間の意味の距離をデータ間の距離として表現できたら、コンピュータで単語の距離が計算できることになりますね
![]()
もし出来たらの、仮定の話になりますが
※図版:著者作成
![]()
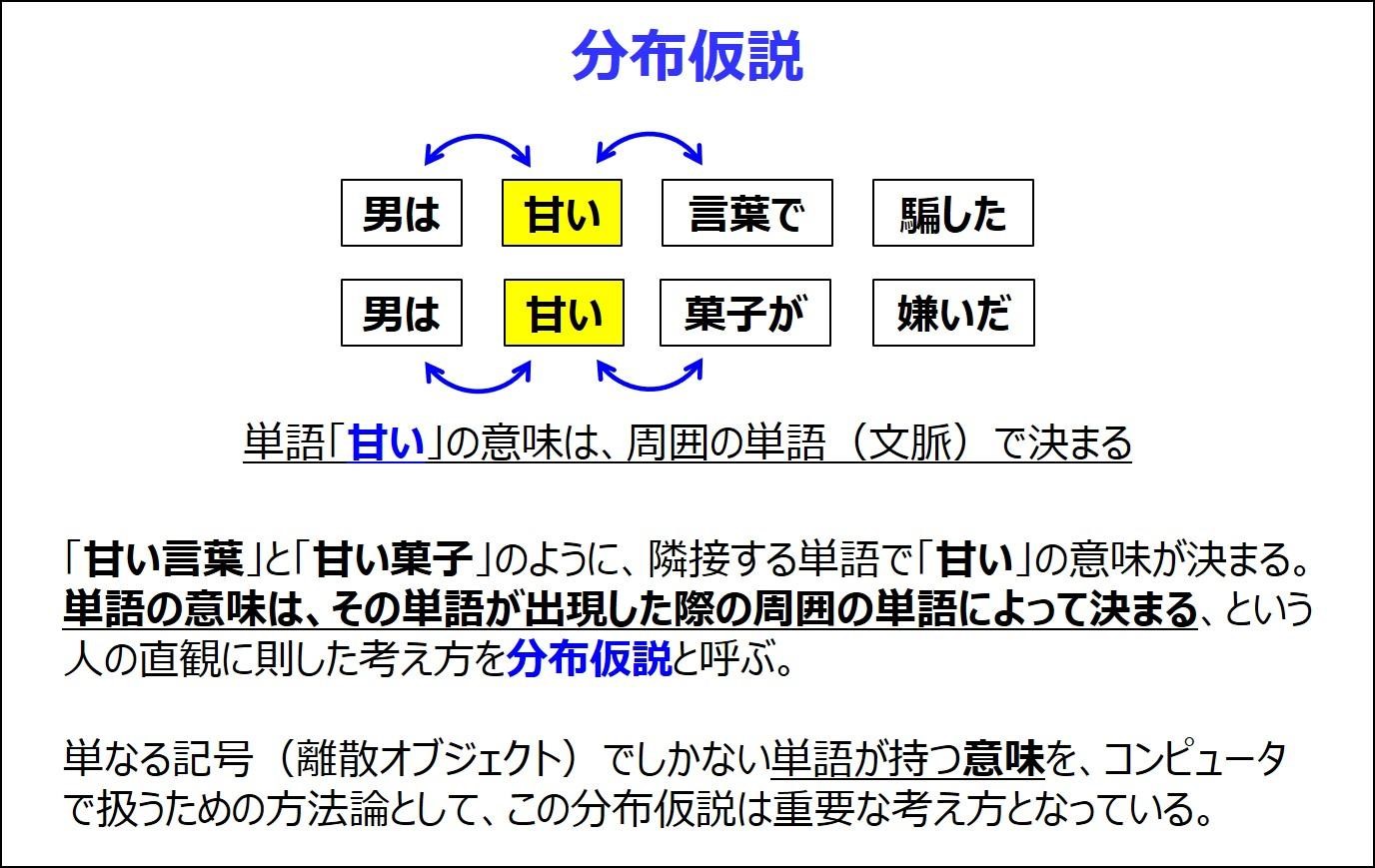
それでは、AIがなぜ言葉を扱えるようになったのか、この最も重要な考え方を説明します。ここを理解していれば、現在の自然言語処理の基本が理解可能になるはずです。それが図にある分布仮説です。この図に書いてあるように、“甘い”という言葉は、その前後にある単語によって、その意味が変わってしまいます。つまり単語の意味は、その単語が出現した際の周囲の単語によって決まる、というシンプルな考え方です
![]()
これだけですか?確かにこの例では、直感的にはそんな気もしますが、単なる仮説でしかないですね
![]()
そうです。分布仮説は直観に基づいた仮説でしかありません。しかし、この考え方を利用したニューラル言語モデルで言語をコンピュータで処理すると、従来の言語モデルを凌駕する性能を示すことは事実です。しかも英語・日本語・スペイン語など世界中に多数ある言語のすべてに適用できるのです。このため世界的に、このニューラル言語モデルが一気に広がったのです
![]()
ということは、ニューラル言語モデルが基本にある今のAIは、言葉の意味を理解していないのですね?
図版:著者作成
![]()
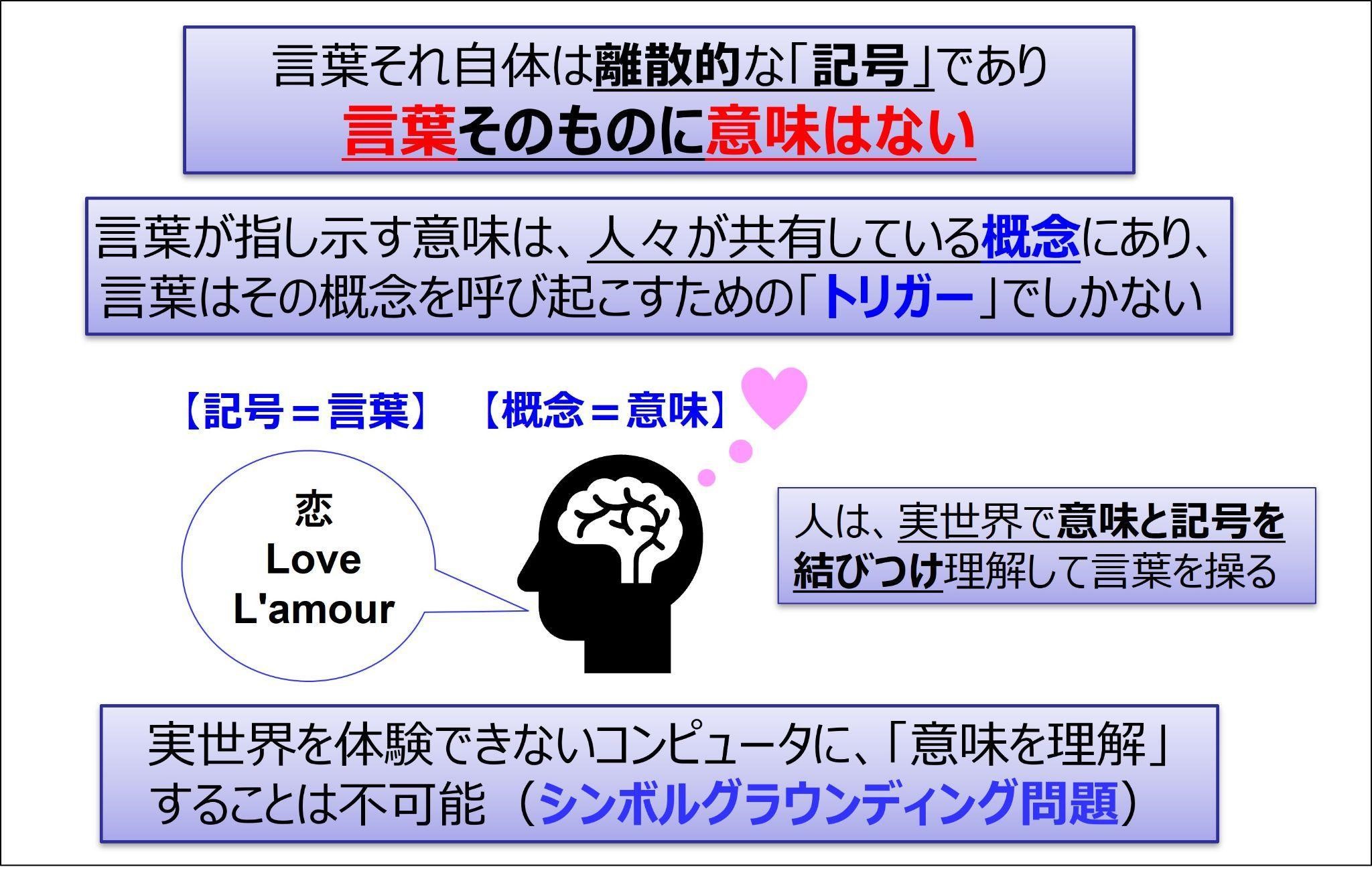
そもそも言葉に意味はありません。言葉は単なる記号でしかないのです
![]()
なにを突然言っているのですか?言葉に意味が無かったら、考えたり会話ができないじゃないですか
![]()
図にあるように、人々が共有している概念を指し示すのが、記号である言葉です。意味があるのは人の頭脳の中にある概念で、言葉はその概念を呼び起こすトリガーでしかなく、言葉そのものに意味があるわけではないのです
![]()
まぁ確かに、言われてみればそうですね。“恋”という概念は世界中の人々で共有していますが、使っている言語が違えば言葉はそれぞれ違いますからね
![]()
したがって、現実世界で体験ができないコンピュータに意味は理解できないのです。これをシンボルグラウンディング問題と呼んでいますが、どうすれば意味と言葉をつなげるかが長年解決できなかった難問だったのです
![]()
なるほど、その解決手段として先ほどの分布仮説を利用しようとしたのですね
※図版:著者作成
![]()
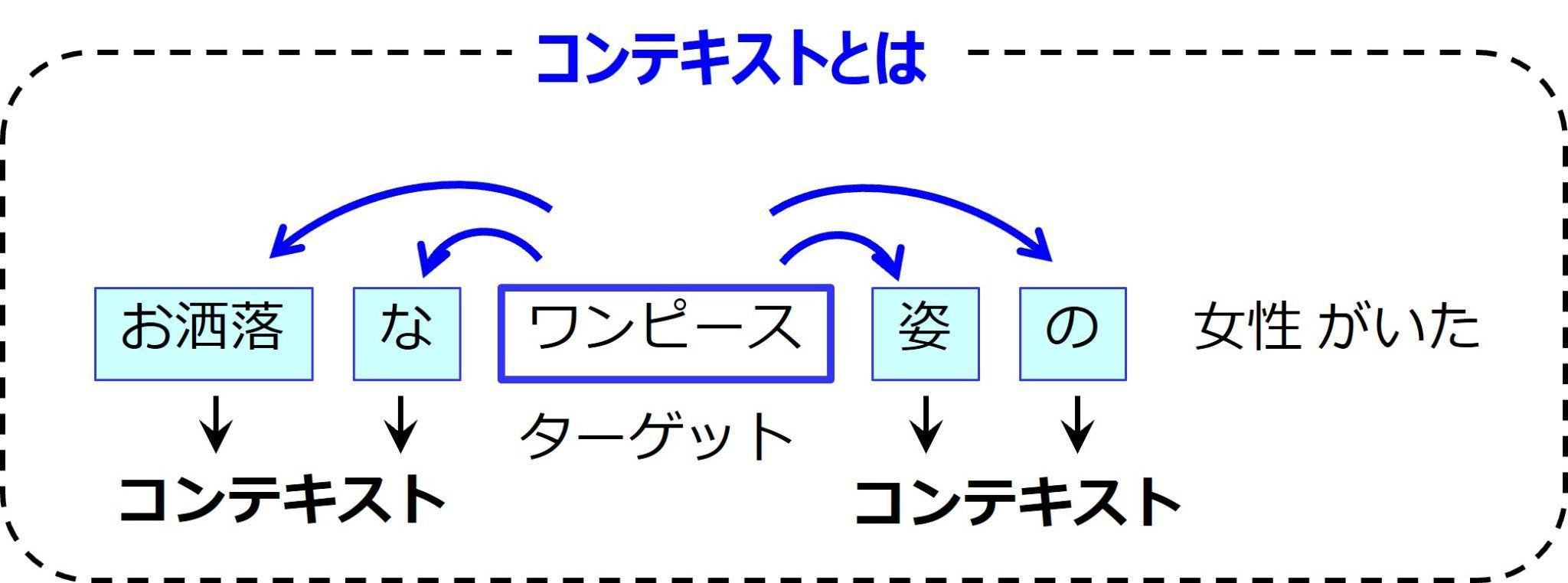
そうです。図を見てください。”ワンピース”という単語の周囲には、”お洒落” ”な” ”姿” ”の”という単語(形態素)があります。ターゲットとなる単語“ワンピース”の周囲に現れる単語を、ここではコンテキストと呼びます。そこで、このターゲットとなる単語のコンテキストの集合を、言葉の意味としたのです
![]()
ちょっと待ってください。かなり論理の飛躍に思えます
![]()
そう思うのもしかたが無いのですが、説明するためにはニューラルネットワークの知識が必要となります。しかしこの講座では残念ながら脳神経細胞をモデルとしたニューラルネットワークの解説をしていません。AIの中核技術であるニューラルネットワークやそれを多層化したディープラーニングの理解はある程度必要なので、ここで自然言語処理が利用しているモデルの概念だけを説明しましょう。 音声データや気温遷移データなど時間経過に伴って変化するデータを時系列データと呼びます。自然言語をこの時系列データとして扱うことによって、自然言語処理技術が急速に発達してきました
![]()
人が話している音声なら、確かに時間とともに言葉がどんどん変化していくので時系列データですね。でも書かれてある文章はどうでしょうか?
![]()
人が文章を読むとき、文頭から順番に読むことで、その内容を理解することができます。つまり話している言葉を聞いて理解するやり方と同じなので、時系列データとして処理できます
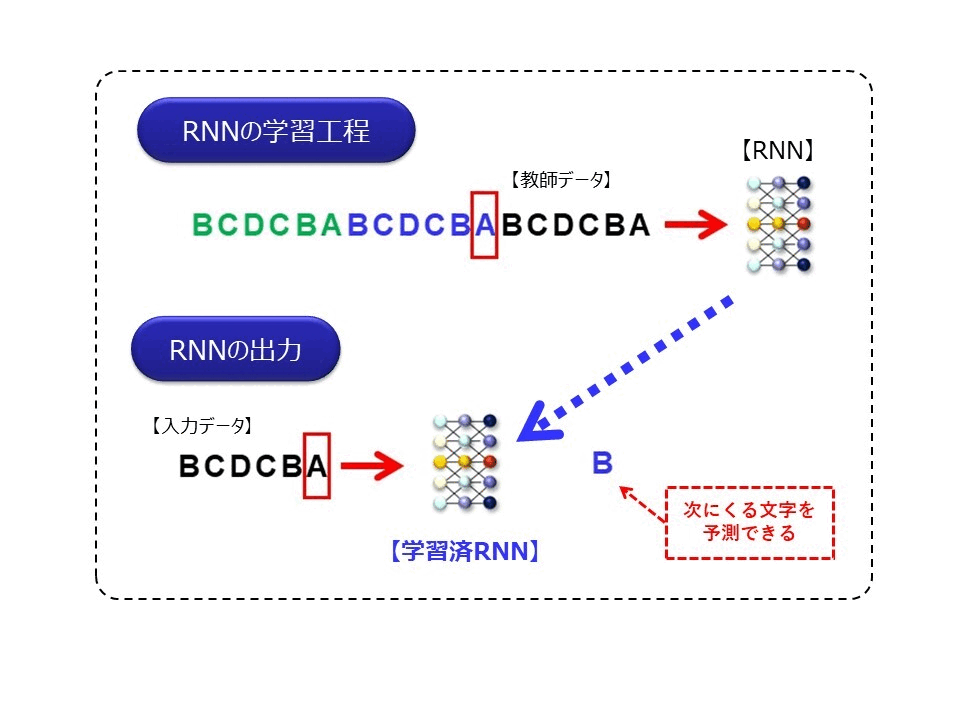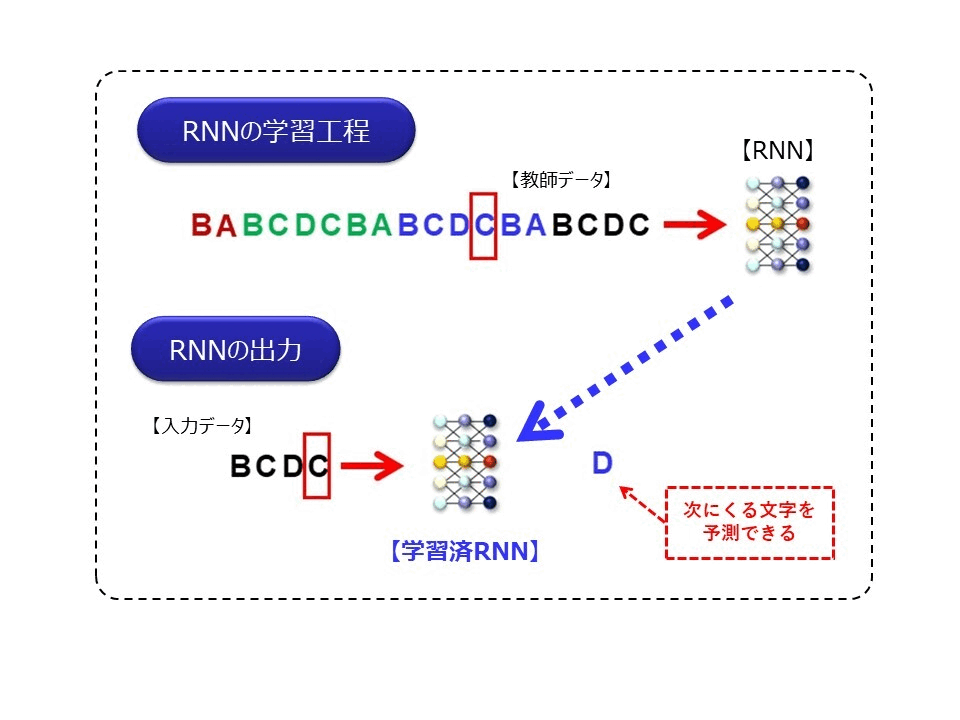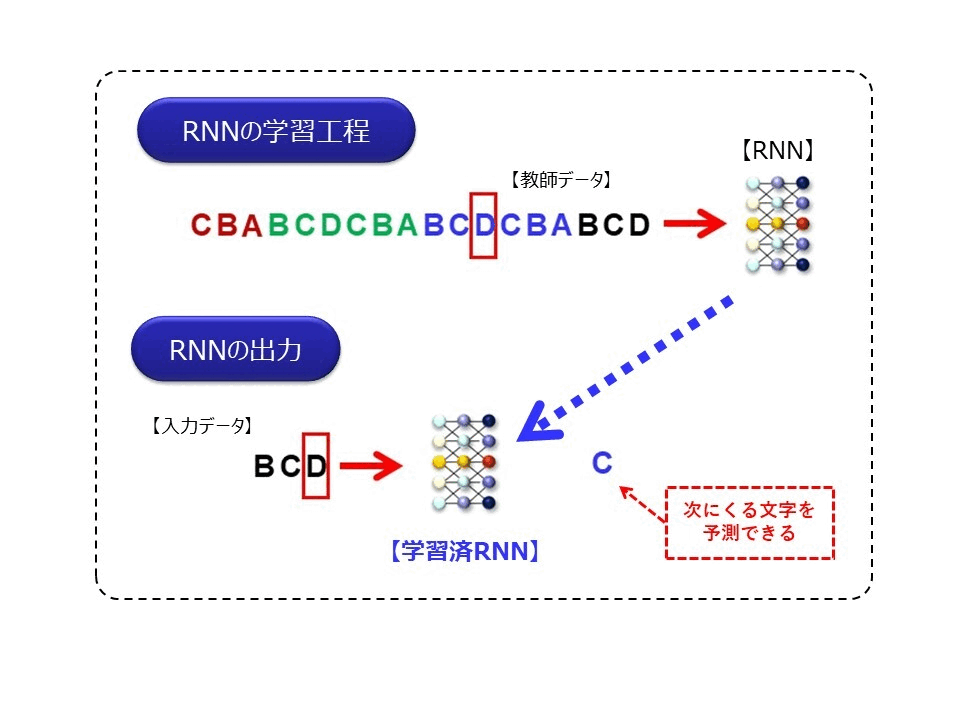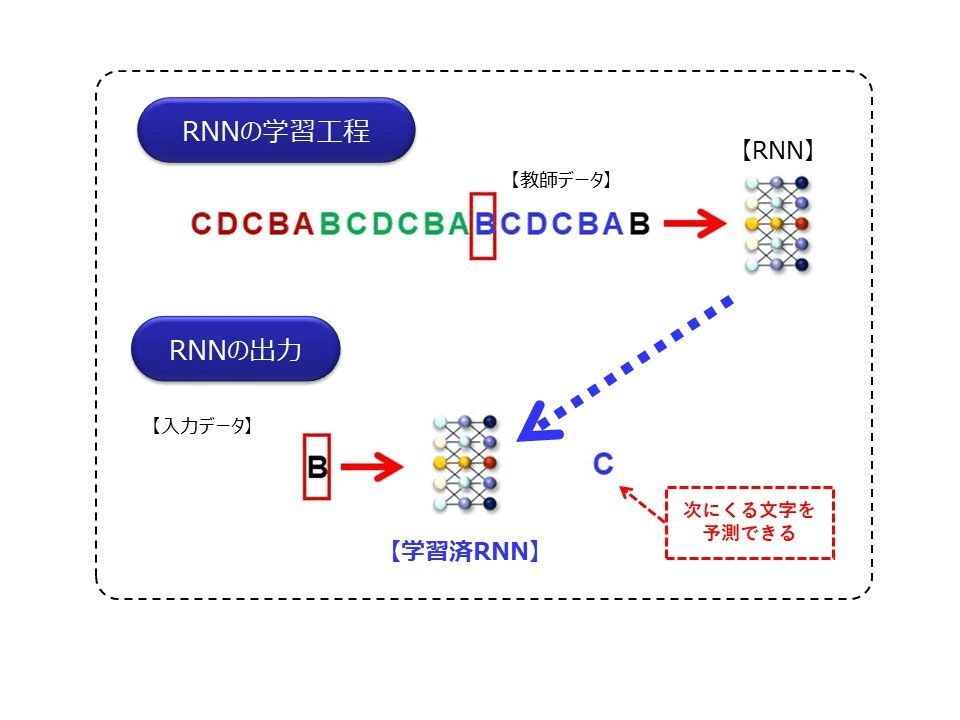
※GIFアニメ 著者作成
![]()
この図は、時系列データを処理するニューラルネットワークの中で、最もシンプルなRNN(Recurrent Neural Network)というモデルを模式的に説明した図になります。なお詳細は省きますが、RNNは基本的に入力された時系列データを、一定時間記憶することができるネットワークになります。
ゴリくん、”ABCDCBA”という文字列があったとします。そこに、新たに”ABCD”という文字列が順番に登場したら、次にくる文字は何だと思いますか?
![]()
それはもちろん、”C”だと思いますね
![]()
図の上側の学習工程にあるように、RNNに”ABCDCBA”という周期の時系列データが順番に入力されると、RNNはこれを記憶(学習)します。次に、この学習済みRNNに対して、”ABCD”とデータが入力されると、次に出現する文字を””と予測できるようになります。つまりRNNは、一定の周期(パターン)の文字列を記憶できるので、次に来る文字を予測することができるようになるのです。これは、時系列データはある値は直前の値と強い関係性を持っているという性質を利用したものです
![]()
なるほど、確かに時系列データなら直前のデータから突然ジャンプするより、滑らかに変化していく方が多いと思いますね
![]()
自然言語も順番に言葉が入ってくる時系列データであり、同様な性質を持っているのです。この自然言語の性質というか特徴を巧みに利用したのが、このニューラル言語モデルなのです
![]()
まだ違和感があるのですが、先ほど説明された分布仮説も関係しそうですね。具体的にどうやるのでしょうか
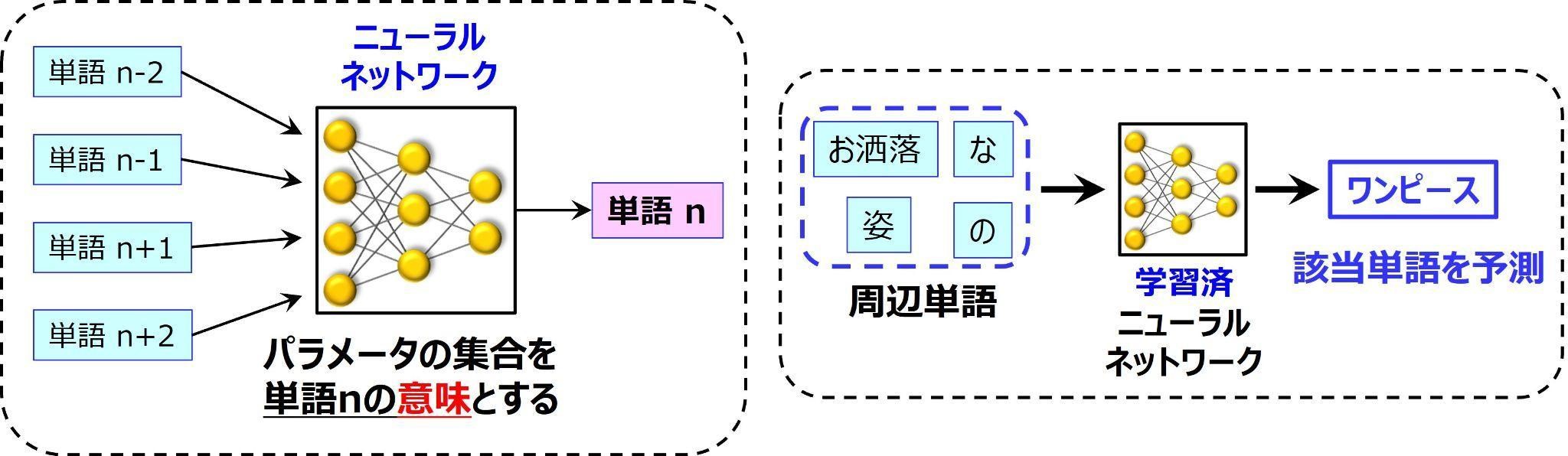
※図版:著者作成
![]()
上の図をみてください。RNNなどのニューラルネットワークに、ターゲットとなる単語”n”のコンテキスト(周囲にある単語)を学習させます。するとコンテキストを入力するとターゲットの単語”n”が出力できるようになります。つまり右の図のように、学習済みネットワークに”お洒落” ”な” ”姿” ”の”という単語が入ると、”ワンピース”を出力できるようになるのです
![]()
なるほど、分布仮説を利用することで、このネットワークは”ワンピース”という単語の意味を、周囲にある単語によって認識できるようになった、ということですね
![]()
素晴らしい!その通りです。ただし教師データつまり読み込ませる文章が、ファッション系の文章なら正解ですが、コミック系の文章で学習させると、ワンピースは”海賊王”になってしまうので注意が必要です
![]()
我々の世代には、非常にわかりやすい例えですね
![]()
学習済みネットワーク内部では、各単語はユークリッド距離のような多次元ベクトルで表現されています。そして意味が類似する単語は同じような文脈で出現するので、その単語のベクトルも類似するはずです。したがって、似たような意味の単語を探すことは、似たようなベクトルを探す問題に置き換えられることになります
![]()
素晴らしいアイデアですね。言葉の意味という哲学的な概念を、ベクトル演算に変換したので、コンピュータが言葉の意味を扱えるようになったのですね
![]()
そう、この意味のベクトル化によってニューラル言語モデルが飛躍的に発展し、機械翻訳や質疑応答、文章の要約から画像生成AIまで数年で一気に進展したのです
![]()
また飛躍しすぎです。コンピュータが意味を扱えるようになると、なぜ”呪文を唱える”とお好みの画像を出力する魔法使いのような画像生成AIができてしまったのですか
![]()
今回の自然言語処理の講座では、ここまでの説明でおよそ60年間の自然言語処理研究の成果を駆け足で説明しています。残りはわずか数年分なのですが、ここからはあまりに爆発的な論文数と情報量になってしまい、私は未だに全体像を把握できていません。まだ整理がついていませんが、AIが人間並みの会話ができるようになったり、画像を生成できるようになった概要ならできますので、次回の講座で解説しましょう
図版・著者:谷田部卓
AIセミナー講師、著述業、CGイラストレーターなど、主な著書に、MdN社「アフターコロナのITソリューション」「これからのAIビジネス」、日経メディカル「医療AI概論」他、美術展の入賞実績もある。
(TEXT:谷田部卓 編集:藤冨啓之)
メルマガ登録をしていただくと、記事やイベントなどの最新情報をお届けいたします。
学びをシェアする



30秒で理解!インフォグラフィックや動画で解説!フォローして『1日1記事』インプットしよう!























データ越境者に寄り添うメデイア「データのじかん」が提供する便利ツールです。
本ツールは、JavaScriptを用いてお客様のブラウザ上で処理を行います。サーバーとの通信は行われず、入力データはお客様のみの端末内で処理されます。









































それではコンピュータが、どうやって言葉を操れるようになったかを説明しましょう。ちょっとその前に、この図を見てください