AIの進歩は日進月歩。そのトップを走る企業の一角が『ChatGPT』を開発したOpenAIとパートナーシップを組み、AI搭載の検索エンジン『Bing』『Microsoft Edge』を運営する米マイクロソフトであることに間違いはありません。
そんな同社は2023年7月にも、「LongNet」「RetNet」という、大規模言語モデルやその基礎アーキテクチャとなる深層学習モデルについての論文を発表し、話題を呼びました。本記事ではそれらを中心に、AI開発研究の最前線についてリポートします。

2023年7月6日に発表された「LongNet」は、現在の深層学習モデルのデファクトスタンダードである「Transformer」の発展型の一つです。2017年にGoogleの研究チームらによって発表された論文『Attention is All You Need』にて提案されたTransformer。
論文のタイトルでも示されている通り、深層学習モデルの構築において、それまで組み合わせられていた「リカレント」「畳み込み」ネットワークを排除し、「Attention」機構のみに基づくことで、並列処理やトレーニングにかかる時間、精度の大幅向上を達成したのがTransformerであり、今ではGoogleの『BERT』や、ChatGPTに用いられている『GPT』など、代表的な自然言語モデルのベースとなっています。
自然言語処理において大きな成果を達成した「Transformer」ですが、学習元となる文章の長さ(シーケンス長)に対し、2次関数的に計算量が増加するため、処理できるテキストの長さに限界がある、という課題が存在します。その解決にあたって、2019年発表のSparse Transformersなど、計算を効率化する手法が考案されてきました。
「LongNet」はその一種であり、「dilated attention」というシーケンス長の長さに合わせて指数関数的に注意のフィールドを分散させることで、下図の通り大幅な扱えるシーケンス長の飛躍を達成したということです。
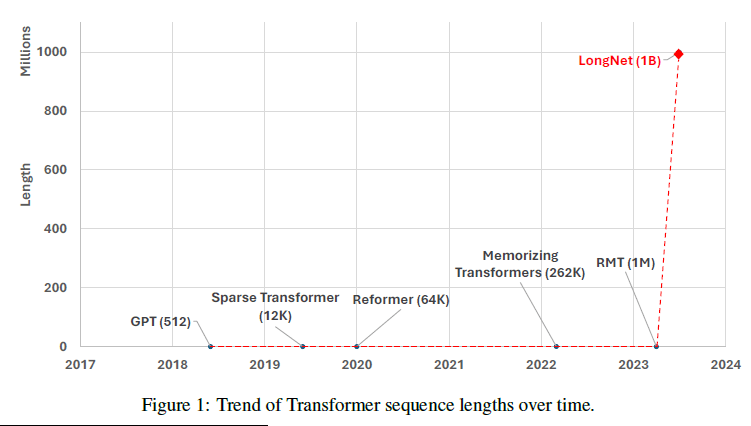
※引用元:Jiayu Ding, Shuming Ma, Li Dong, Xingxing Zhang, Shaohan Huang, Wenhui Wang, Nanning Zheng, Furu Wei『LongNet: Scaling Transformers to 1,000,000,000 Tokens』┃arXiv
ご覧の通り、それまでの自然言語処理モデルが扱えるトークン数(自然言語処理におけるテキストの最小単位)が~数百万以内に収まっているのに対し、「LongNet」が扱えるトークン数は10億以上と、まさに桁外れです。
2023年7月18日に発表された「RetNet(Retentive Network)」は、「Transformer」の後継モデルとして提案された深層学習モデルです。論文『Retentive Network: A Successor to Transformer for Large Language Models』では、GPUメモリの消費、スループット、レイテンシーといった指標で精度を犠牲にすることなく「Transformer」を上回ることが示されており、「LongNet」と同様に、扱えるシーケンス長の拡大や処理効率の向上を実現することが予想されます。
さて、「LongNet」や「RetNet」による大規模言語処理の発展は何を我々にもたらすのでしょうか?
そのイメージとして挙げられるのが、コーパス(構造化された自然言語の大規模データベース)やインターネット全体を一度に学習できるようになるということです。これにより、チャットボットAIが質問に答えるために使える情報の量は大きく高まり、資料数十冊を一瞬で取り込ませるなど目的に合わせたAIのチューニングも容易になります。その範囲は言語処理に留まらず、画像処理など他の分野にも及ぶことが予想され、人工知能全体の革新を推し進めることが予想されるのです。

もちろん、AIを研究する企業はマイクロソフト社だけではありません。大規模言語モデルや深層学習モデルの発展は日々進んでいます。
たとえば、2023年7月18日に発表されたMetaの『Llama2』は、GPT-3.5の3月1日時点に匹敵する性能を持ちながら一部を除いて研究/商用が許諾されているオープンソース性の高さが魅力です。
また、TransformerをベースとするGoogleの『Bard』も2023年3月22日に一般公開され、対応言語を広げるとともに(日本語はすでに対応済み)、Google レンズと連携し画像も参照できるようになる、音声での対応を開始するなど、アップデートを重ねています。
2023年初頭より『ChatGPT』をきっかけににわかに盛り上がった「生成AIブーム」。そろそろAI疲れを感じている方もいるかもしれません。しかし、日々新たな進展が報じられるこの状況。まだまだ目が離せないといえるでしょう。
2023年7月末時点における、AI開発の最新ニュースをマイクロソフトの大規模言語モデル「LongNet」を中心に取り上げてきました。
2023年7月27日にはマイクロソフトから日本政府へChatGPT技術が提供されることが報じられました。機械学習へのデータ利用における自由度の高さから「機械学習パラダイス」と称されることのある日本に対する、AI開発企業の注目度は少なくないと考えられます。我々自身もこの環境を活用できるよう、AI開発・活用の最前線に目を向けていきましょう。
(宮田文机)
・Jiayu Ding, Shuming Ma, Li Dong, Xingxing Zhang, Shaohan Huang, Wenhui Wang, Nanning Zheng, Furu Wei『LongNet: Scaling Transformers to 1,000,000,000 Tokens』┃arXiv ・Yutao Sun, Li Dong, Shaohan Huang, Shuming Ma, Yuqing Xia, Jilong Xue, Jianyong Wang, Furu Wei『Retentive Network: A Successor to Transformer for Large Language Models』┃arXiv ・Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin『Attention Is All You Need』┃arXiv ・山下裕毅(Seamless)『10億トークンを処理できるマイクロソフトの言語生成AI「LongNet」、喉のMRIからAI音声合成など5つの重要論文を解説(生成AIウィークリー)』┃TECHNOEDGE ・Introducing Llama 2┃MetaAI ・Sparse Attentionについて分かりやすく解説!┃AGIRobots ・大規模言語モデル┃NRI ・Advancing AI for humanity ・Ignacio de Gregorio『Microsoft Just Showed us the Future of ChatGPT with LongNet』┃Medium ・サイトウケンジ,ITmedia『ChatGPT(3.5)に匹敵する「Llama 2」をローカルPCで動かしてみた』┃AI+ by ITmedia NEWS ・Google Bard ・樽井 秀人『GoogleのAIチャット「Bard」もしゃべるように ~比較的大規模なアップデートを実施』┃窓の杜 ・Microsoft、日本政府にChatGPT技術提供 答弁案に活用┃日本経済新聞 ・「日本は機械学習パラダイス」 その理由は著作権法にあり┃AI+ by ITmedia NEWS
メルマガ登録をしていただくと、記事やイベントなどの最新情報をお届けいたします。
学びをシェアする



30秒で理解!インフォグラフィックや動画で解説!フォローして『1日1記事』インプットしよう!























データ越境者に寄り添うメデイア「データのじかん」が提供する便利ツールです。
本ツールは、JavaScriptを用いてお客様のブラウザ上で処理を行います。サーバーとの通信は行われず、入力データはお客様のみの端末内で処理されます。