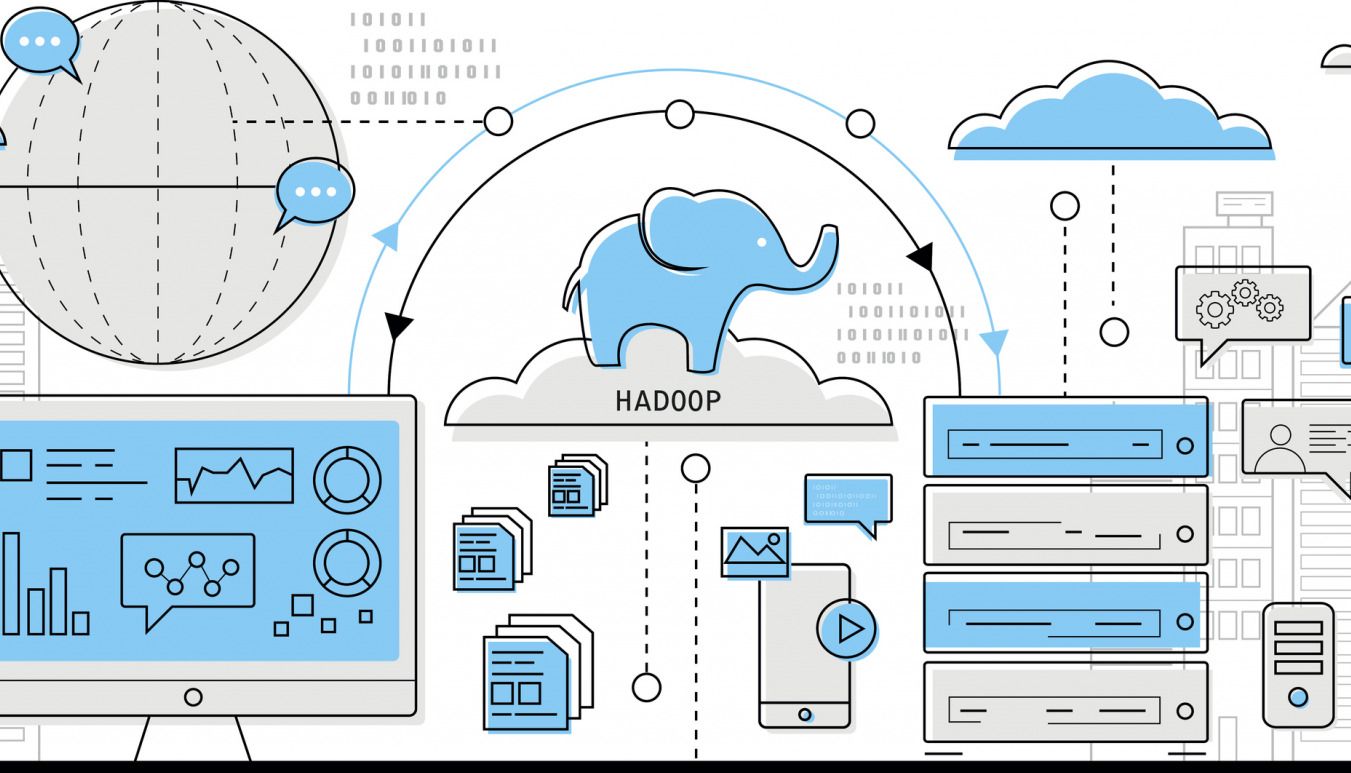
分散ファイルシステムであり、構造化データ・非構造化データに関係なくあらゆるデータを蓄積できます。「どのファイルをどのように分割したか」や「どの装置にどのように格納したか」については「ネームノード(name node)」と呼ばれるサーバで一元管理され、他のサーバはデータ自体を保存する「データノード(data node)」として利用されます。HDFSにファイルを保存する場合は、そのファイルは一定のサイズに分割され、それぞれブロック単位でデータノードに保存されるという仕組みです。
ちなみに、あるデータノードが故障し、それに保存されているブロックが消失する可能性を防ぐために、複数のデータノードにレプリカのブロックが保存されています。これにより、1つのデータノードが壊れた場合でも、他のデータノードの同じブロックを参照することができ、データの欠損を回避できるようになっています。
大規模なデータを分散処理するためのプログラミングモデルのこと。HDFS上にあり、データの分散処理を行うことができる汎用的なフレームワークであり、データの集計や検索、データクレンジングを行えます。
データの処理をmap処理とreduce処理の2段階に分けて行う点が特徴です。map処理は入力データを読み込んでフィルタリングするもので、reduce処理はmapで抽出されたデータをまとめて結果を出力する役割を果たします。
なお、最近ではSparkなどほかの処理エンジンの台頭によって、その役割が縮小しています。

クラウドの台頭や、上の章でも触れたようにMapReduceからほかの処理エンジンに移りつつあるなど、Hadoopをめぐる状況も変わりつつあります。
しかしながら、現在でも大規模のデータ処理ツールとして多くの場面で導入されており、初期に比べれば大幅に進化しています。2017年12月にはHadoop 3.0がリリースされました。Hadoopは今もなお、重要なインフラなのです。
【参考記事】 ※1 分散処理技術「Hadoop」とは:NTTデータのHadoopソリューション ※2 ストレージ Hadoopとは - Fujitsu Japan ※3 HDFS(Hadoop Distributed File System)とは - IT用語辞典 ※4 MapReduceとは - IT用語辞典 ※5 Hadoopの特徴と低コスト、高速性の秘密を知る _ Hadoop Times ※6 Hadoopで、かんたん分散処理 - Yahoo! JAPAN Tech Blog ※7 「Hadoopの時代は終わった」の意味を正しく理解する - 科学と非科学の迷宮 ※8 各Hadoop製品の特徴について - クリエーションライン株式会社
(安齋慎平)
![]()
メルマガ登録をしていただくと、記事やイベントなどの最新情報をお届けいたします。
学びをシェアする



30秒で理解!インフォグラフィックや動画で解説!フォローして『1日1記事』インプットしよう!























データ越境者に寄り添うメデイア「データのじかん」が提供する便利ツールです。
本ツールは、JavaScriptを用いてお客様のブラウザ上で処理を行います。サーバーとの通信は行われず、入力データはお客様のみの端末内で処理されます。