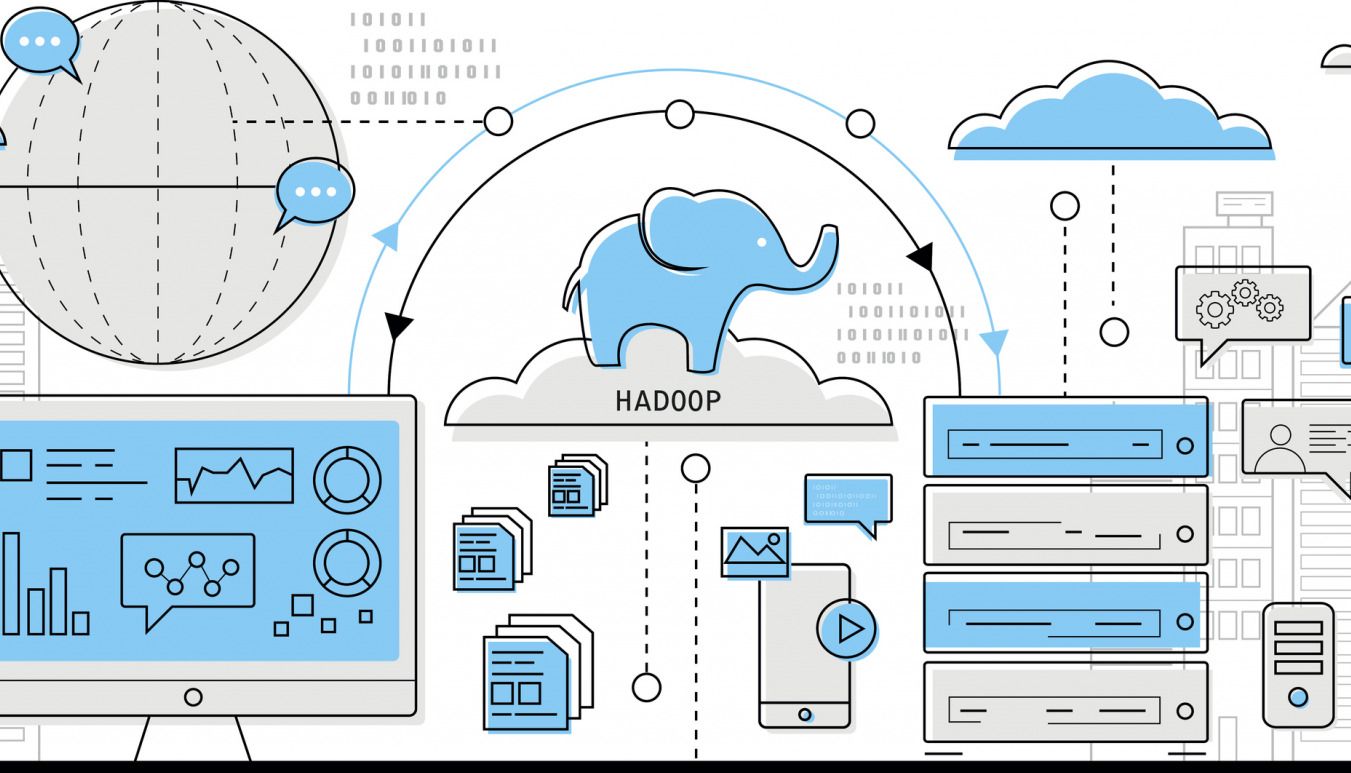
SEなら知っているであろうHadoopですが、そのほかの職種の人だと、IT企業に勤めていてもなかなかその意味を知る機会がないと思います。
そこでこの記事では、Hadoopについて見ていくことにしましょう。

まずはHadoopの説明から。以前、「そもそもビッグデータとは? ビッグデータの定義から活用例までご紹介」という記事でHadoopについて取り上げました。この記事では以下のように説明しています。
「大量のデータを手軽に複数のマシンに分散して処理できるオープンソースのプラットフォーム」のこと
いまさら聞けないHadoopとテキストマイニング入門 (1_3):テキストマイニングで始める実践Hadoop活用(1)|@IT
Hadoopにより、ペタバイト(1ペタバイトは1テラバイトの1000倍)レベルの非構造化データ(メールや画像、動画などのデータ)の超高速処理が可能になりました。そして大量の情報を低コストで分析できるようになったのです。
HadoopはApacheソフトウェア財団のプロジェクトの1つであり、「Apache Hadoop」とも言われます。Java言語のフレームワークであり、ホートンワークス、米ヤフー、クラウデラといった企業のほか、インテル、マイクロソフトなども開発に携わっています。

ネット上に日々蓄積されている情報、たとえばテキストデータや音声、動画データなどはビッグデータとなりえますが、データ量はペタバイトに及びます。この大容量のデータを高速処理するために、新技術が必要となりました。
従来は、データを1つのサーバに蓄積させて計算処理をする、という方法を取っていましたが、これでは重いデータの高速処理に限界があります。そこで、データを複数のサーバに分散させ、各々のサーバで計算処理をさせることで、大容量データの処理を可能にしたのです。
しかしながら、サーバを複数に分散させるには、各サーバをネットワークでつないだり1カ所のサーバが止まった時に対処できるようにしたりする必要があり、複雑なシステムの構築が求められます。そこで、それらを解決する手法であるHadoopが使われるようになったのです。

Hadoopは、大きく分けて次の2つの要素から成り立っています。
1 2 ![]()
メルマガ登録をしていただくと、記事やイベントなどの最新情報をお届けいたします。
学びをシェアする



30秒で理解!インフォグラフィックや動画で解説!フォローして『1日1記事』インプットしよう!























データ越境者に寄り添うメデイア「データのじかん」が提供する便利ツールです。
本ツールは、JavaScriptを用いてお客様のブラウザ上で処理を行います。サーバーとの通信は行われず、入力データはお客様のみの端末内で処理されます。