


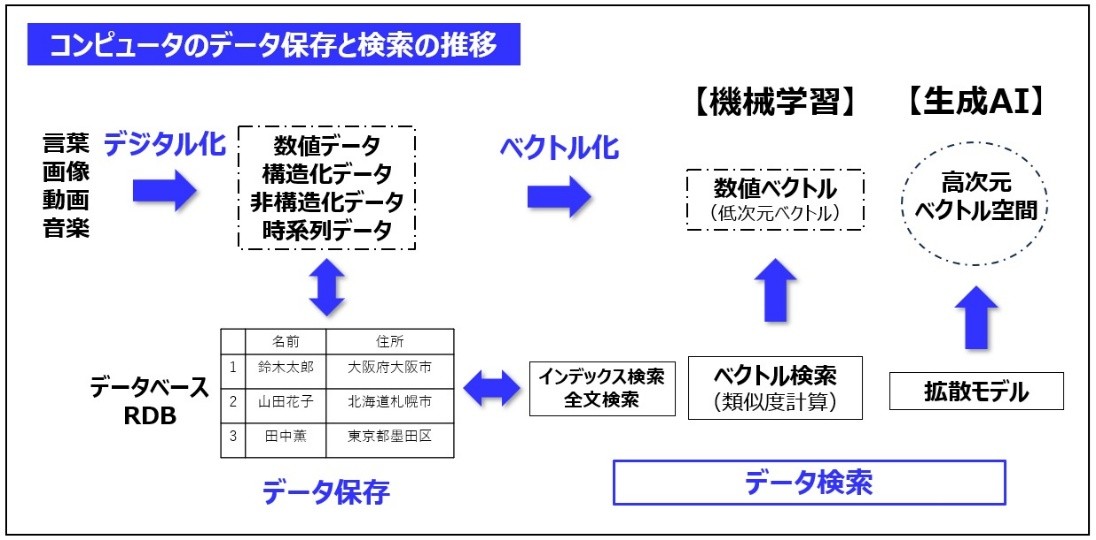
※図版:筆者作成「コンピュータのデータ保存と検索の推移」
![]()
この図は、コンピュータがどのように情報を保存して利用しているかを模式化したものだ。IT系なら常識のはずだが、人間が扱う言葉・画像・音楽・動画などの情報は、コンピュータでも扱えるようにデジタル化してデータとする。そしてコンピュータに、そのデータ保存するのだが、その際に後から利用できるように各々のデータに索引(インデックス)を付けたリスト形式にしておく。
![]()
最も原始的なのが図にあるような、名前から住所を調べる住所録ですね。そういえば昔は紙の分厚い電話帳が配られてたな。個人情報なんてダダ洩れだったですよ。
![]()
それどころか、市販の年賀状ソフトには、NTTの全国電話帳がCDとして付属していたから、電話帳に名前を掲載している人の住所なら簡単に調べられたんだぞ。これはなかなか便利だった。
![]()
それも個人情報保護法が施行された2005年までです。話を戻してください。
![]()
とにかく、誰でもExcelなら使ったことがあるはずなので、データにはインデックスがないと検索できないことぐらい分かるだろう。そういえば日本で最初の表計算ソフトは1980年に発表された「PIPS」で、アメリカの「VISICALC」とほぼ同時期だった。Excelなんぞは1985年発売で、しかもしばらくMac専用だったんだぞ。
![]()
Windowsは、1995年のWindows95まで使いものになりませんでしたからね。テックジー先生、すぐに脇道逸れないでください。
![]()
そうだった。コンピュータが情報を扱うためには、まずデータを格納し、一定期間保持し、さらに必要なデータを検索して取り出せる機能が必要だ。そのために開発されたのがRDB(リレーショナルDB)だ。当初は構造化データだけだったので検索はインデックス検索だったが、自然言語のような非構造化データが出てきたので全文検索もできるようになった。
![]()
情報処理入門のような話ですね。
![]()
まぁ待ちなさい。データが自然言語の場合、従来のような検索方法では、完全一致や部分一致がないと検索できなかった。そこでデータをベクトル化して似たデータを検索できる類似度検索にしたのがベクトル検索だ。
![]()
それが連想記憶なんだ。
![]()
まだだ。莫大な数の高次元ベクトルデータがあると、そこから特定の画像データなどを探そうとしても、計算量が膨れ上がり長時間かかってしまう。そこでGoogleは高速な画像検索サービスを実現するため、高速近似近傍検索(aNN)を開発した。これはベクトル空間をテーマごとに分類してクラスタを構築し、そのクラスタを代表するベクトルをインデックスにして高速検索を実現した。
![]()
でもそれじゃ、ベクトル検索といってもインデックス検索みたいですよ。
![]()
しかし、あらかじめ似たベクトルを近くに置いておけば、高速検索できることが実証できた。
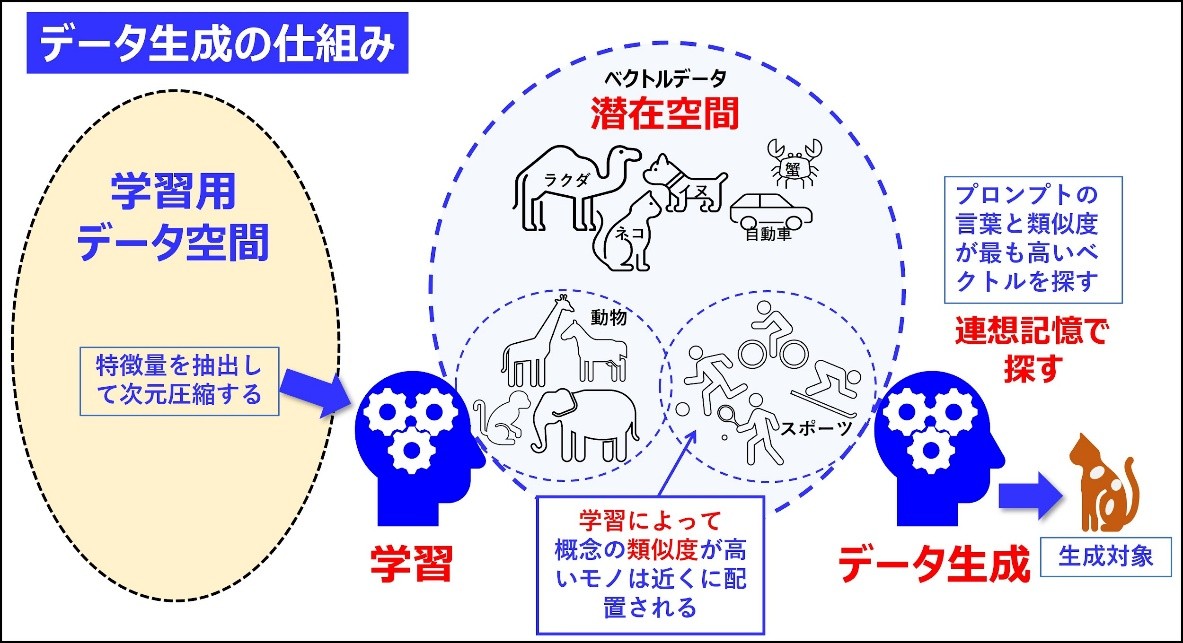
図版:筆者作成「データ生成の仕組み」
![]()
この図のように、拡散モデルによるデータ生成は、学習用の高次元データの特徴量を抽出することで、大幅に次元圧縮する。そしてその低次元ベクトルデータを内部に保存する際、類似しているベクトルを近くに配置している。この操作を「学習」と呼び、集約された低次元ベクトル群のことを「潜在空間」というのだ。
![]()
なるほど。似たベクトルを高速に探せるから連想記憶が実現できたんだ。
![]()
そしてデータ生成とは、プロンプトの言葉をベクトルに変換して、そのベクトルと最も類似度の高いベクトルデータを潜在空間から探し出すことだ。マルチモーダルの生成AIなら、言葉によるプロンプトではなく画像を検索キーにして似たベクトルを探すことになる。もっとも、潜在空間には特徴量しかないから、元のデータそのままを再現することは困難なのだが。
![]()
なんでこの連想記憶方式のモデルを、拡散モデルと言っているんですか?
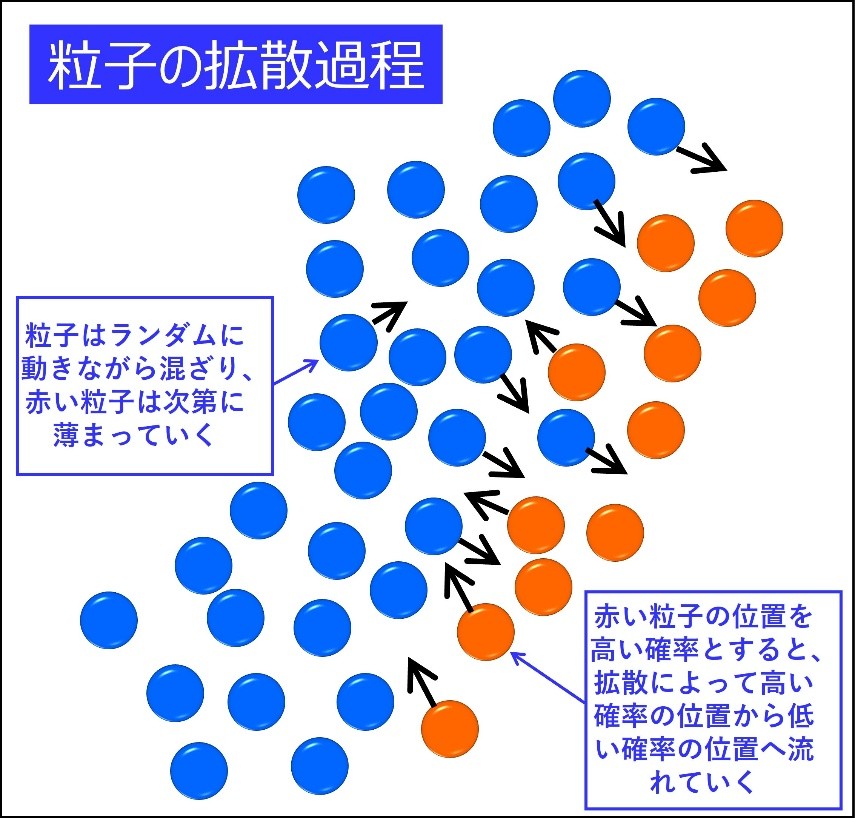
※図版:筆者作成「粒子の拡散過程」
![]()
前回インクの文字を例にして説明したはずだ。もう少し説明を加えると、水面上にインクで文字を書くと、時間が経つにつれてインクの文字が崩れていく。水やインクの分子は、図のようにブラウン運動によってランダムに激しく動いているので、インクは時間とともに水中に拡散していく。これを拡散現象と呼ぶが、秩序をもった対象にノイズが加えられて徐々に破壊され、無秩序な状態になることだな。この過程を逆向きにたどれば、無秩序から秩序を生み出せる。つまり生成ができることになる。これが基本的なアイデアで、拡散現象を利用するので拡散モデルなのだ。
![]()
しかしそんなに上手くいきますか?
![]()
むろん簡単なことではなく、長い間研究されてきた。インクの初めの秩序を持った状態をデータ分布と呼ぶと、正規分布に従ったノイズの強度を強めながらデータ分布に加えていくことで、最終的にすべて正規分布のノイズになる。つまり拡散過程とはデータ分布を正規分布に変化させることで、生成過程とは正規分布をデータ分布に変化させることになる。このインク分子の集団が平均的にどのような速度でどの方向に流れるかだが、拡散過程が生み出す平均的な流れの方向と大きさのベクトルは、各時刻・各位置で推定できる。この流れをつかんでおけば、生成時に時刻を巻き戻すことで元の位置に戻る方向を推定できるようになる。
![]()
ここまでにしましょう。やはり専門書1冊分の内容があるので、簡単には説明はできませんから。
![]()
まぁそうだな。誰でも直観的に理解できるような拡散モデルの説明は、やはり無理がありそうだ。詳細は専門書を読んでくれ。
![]()
では本題の生成AIに創造力はあるかをお願いします。

![]()
そうだったな。生成AIに創造力があるのかを検討するために、人間の創造力の源である連想記憶と、生成AIへの連想記憶の実装を説明してきた。
![]()
ちょっと待ってください。人間の創造力の「源」が連想記憶だと言い切れますか?
![]()
疑り深いな。まぁ確かに人間は思い出す方法として、連想記憶を利用しているとだけしか話さなかったか。では創造性(creativity)について、少しだけ深堀してみよう。「創造性とは何か?」というテーマは昔から様々な哲学者たちが議論してきているが、ここではイギリスの認知科学者マーガレット・ボーデン(Margaret A. Boden)が提唱した創造性三類型で説明してみる。ボーデンは、創造性には次の三種類があるとしている。
・組み合わせ創造性(Combinational Creativity):既存の知識やスタイルを斬新で意外性のあるかたちで組み合わせ、新規性を生み出すタイプの創造性。
・探索的創造性(Exploratory Creativity):既存のルールや枠組みの中を徹底的に探究し、その範囲内で新たな可能性を見いだすタイプの創造性。
・変形的創造性(Transformational Creativity):変革的創造性ともいうが、既存の枠組みやルールを根本から覆し、当初は不可能と考えられていたアイデアまでも生み出すタイプの創造性。
![]()
組み合わせタイプならたくさんありますね。あんぱん+ヒーローでアンパンマンとか、カレー+うどんでカレーうどんとか。でも探索的とか変形的創造性とは?
![]()
囲碁や将棋は膨大な数の指し手があるが、前例のない指し手を指したら探索的創造性だな。変形的創造性は、天地をひっくり返した「地動説」ほどの画期的なアイデアのことだ。ピカソのキュビズムを例に挙げる人もいるが、キュビズムはセザンヌのアイデアを、ピカソとブラックが共同で発展させたものだぞ。
![]()
アートに詳しくなければキュビズムは知られていないので、アインシュタインのE=mc2の方が例としては適切だと思います。
![]()
どっちもどっちだ。話を逸らしたらダメだぞ。言いたかったのは、創造性を発揮するのには連想記憶が有利だという事だ。
![]()
え?アンパンとヒーローだと、かけ離れていますよ。アンパンマン登場以前の日本人ならまったく連想できないモノ同士です。
![]()
いや日中戦争で死にかけた、やなせたかしにとって、飢え死にしそうな状況下では食べ物は命を救うヒーローなのだよ。だから子供時代に大好きだったアンパンを顔にしたアンパンマンが生まれたのだ。だれでも思いつくようなことだと創造性があるとは言わない。カレーうどんは、食べ物という範疇内での組み合わせだから、探索的創造性だな。
![]()
人間の連想記憶は、似たようなものを思い出すことだけではないです。時系列的に連なっていることを、芋づる式に思い出すこともあります。それどころか、時系列に沿った物語形式の方が、人間にははるかに記憶しやすいです。以前の「ナラティブが世界を廻す」の講義で説明しています。
![]()
そうだったな。歴史学者ノア・ハラリは「NEXUS情報の人類史」の中で「物語(ナラティブ)は簡単に覚えることができるのに、リストを覚えるのは難しい。ヒンドゥー教徒の神話ラーマーヤナは1700ページあるが、ヒンドゥー教徒たちはこれをすべて記憶し幾世代にもわたって暗唱してきた」と書いている。さらにハラリは「物語は人類が初めて発明した情報テクノロジーだ」とまで言っている。人間の記憶方法でナラティブが最も効率よいのは、時系列で覚える連想記憶だからなのだろう。
![]()
申し訳ないですが、話がそれ過ぎたので時間切れです。生成AIの創造性については、次回してください。
・コンピュータでのデータ検索方法は、データをリスト化したインデックス検索から、データをベクトル化して類似検索できるベクトル検索へと進化してきた。
・拡散モデルのデータ生成とは、潜在空間にある低次元のベクトルに圧縮された特徴量の中から、プロンプトに類似したベクトルを探し出すことである。
・創造性は、組み合わせ創造性、探索的創造性、変形的創造性の3類型があるとされ、人間の持つ連想記憶がその源と考えられる。
著者:谷田部卓
AIセミナー講師、著述業、CGイラストレーターなど、主な著書に、MdN社「アフターコロナのITソリューション」「これからのAIビジネス」、日経メディカル「医療AI概論」他、美術展の入賞実績もある。
(TEXT:谷田部卓 編集:藤冨啓之)
メルマガ登録をしていただくと、記事やイベントなどの最新情報をお届けいたします。
学びをシェアする



30秒で理解!インフォグラフィックや動画で解説!フォローして『1日1記事』インプットしよう!























データ越境者に寄り添うメデイア「データのじかん」が提供する便利ツールです。
本ツールは、JavaScriptを用いてお客様のブラウザ上で処理を行います。サーバーとの通信は行われず、入力データはお客様のみの端末内で処理されます。






































前回は、生成AIがデータ生成できる秘密は、人間の記憶方法である連想記憶を実現したことにある、まででした。今回も引き続き、この連想記憶についてテックジー先生に解説してもらいます。
前回、この連想記憶に関して尻切れトンボだったので、補足説明をしておく。