




![]()
雑談はさておいて、今回はAGIからASIまでOpenAIの思惑通りにAIが進化を続けられるのかを、改めて考えてみましょう
![]()
なるほど。最近のOpenAIは、華々しい成果を立て続けに発表していますが、次第にその技術内容を公表しなくなりましたね。組織が急激に膨れ上がってくると、かつてオープンだったGoogleが次第に隠ぺい体質になった道を、OpenAIが同じようにたどっているからな
![]()
7月にOpenAIの従業員たちが、過度に制限的で違法な秘密保持契約を締結させていると、内部告発騒動を起こしています。(註2)営利企業に移行し莫大な資金を調達してから、内部情報の公開に神経質になっていることは明らかですね。
しかもごく最近、主要研究者まで退職するようになっています。これは噂ですが、AGIが出現すると核兵器並みの世界的重要技術になるので、アメリカ政府がAGI技術を厳格な機密扱いにさせているからだ、という話までありますね
![]()
え!AGIを核兵器並みに扱わなければならないのか。まぁもし中国が先にAGIを開発したら、世界を征服できてしまうとアメリカ政府は考えているんだな
![]()
また話が逸れたので戻します。さて、OpenAIばかり注視していたのですが、ここ数か月の間だけでもライバル企業からOpenAIに対抗する技術発表が複数ありました。共通するキーワードは、SLM(Smaller Language Model)小規模言語モデルです
![]()
OpenAIのAIは、基本的に大規模言語モデル(LLM:Large Language Model)から、さらに極端な巨大化を続けていますね
![]()
その通りです。前回説明したスケーリング則に則って、ひたすら巨額投資を続けることでAI性能を向上させようという物量作戦です。他社は、そんな国家予算並みの巨額投資が不要な、SLMに活路を見出そうとしているのです。
SLM個別の説明をすると長くなるので、LLMとの比較でまとめてみました
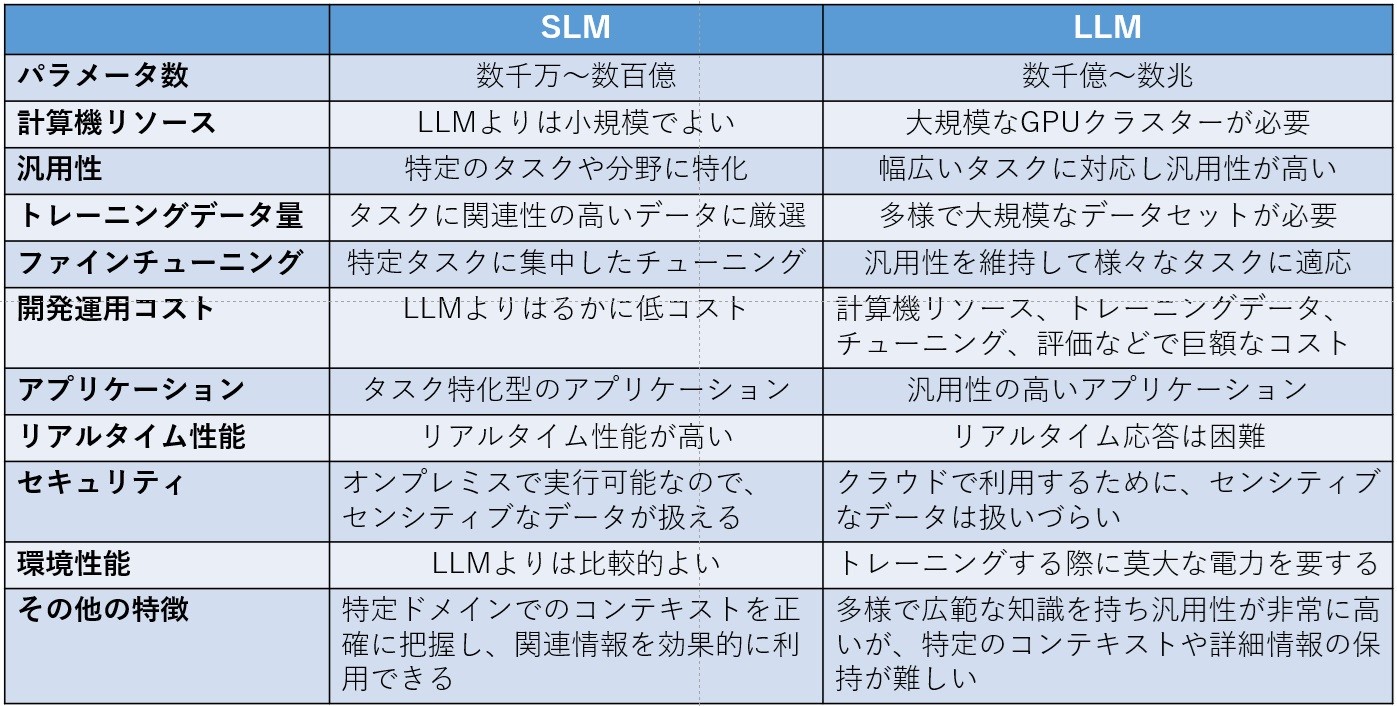
※図表:筆者作成「SLMとLLMの比較」
![]()
これだけみると、SLMの方にメリットがあるように思えますね
![]()
ただ注意が必要なのは、この比較はAI開発側の立場の方を重視しています。ユーザー視点での比較になると、サービス提供価格の比重が大きくなりますが、今のところユーザー提供価格が流動的なので判断は難しいですね。
というかユーザーがAIの機能に対して、どんな使い方を考えているかで決まります。何でも教えてほしいのならGPTのようなLLMで。専門領域とかリアルタイム性能ならSLMになります。
日本のAI企業のほとんどは、大量の日本語データや画像を学習させ、LLMより自然な日本語文章や日本文化をきちんと反映した回答や画像を出力することで、LLMとの差別化を図っています
![]()
ボクも画像生成AIに”日本女性が散歩している画像”を出力させると、芸者のような和装の女性たちが古民家の並ぶ狭い路地を歩いている画像ばかり出力しますからね。AIは、日本女性全員が和服を着ていると習ったんですかね
![]()
アメリカで開発されたLLMは、学習データの大半が英語圏のものなので世界のローカルな文化は不得意なのです。もっともLLMは学習データさえ入手できればなんでも飲み込んでしまうので、進化の著しいLLMに対してSLMの差別化がいつまでできるかは分かりませんが
![]()
しかし社会実装するには、安定したテクノロジーでなければ企業は使えない、とか先生は以前言ってましたよ。このAIテクノロジーは、ここ数年だけでも毎月のように技術革新があるので、安定したテクノロジーになることは期待できませんが
![]()
その判断は難しいところで、クライアント企業が決断しなければなりません。技術力で先行するベンチャー企業の画期的な新サービスが登場すると、営業力のある大企業がその弱点などを改良して似たようなサービスを始める場合がよくあります。
日本の大企業は昔から”前例主義”なので、実例のないスタートアップの新技術はあまりにリスクが高いとして選ばず、大企業の後発サービスを選ぶ企業が大半でした。
![]()
いわゆる”後出しジャンケン体質”ですよね
![]()
その通り。技術のスピードが緩やかだった時代では、このような企業も渡り合えていましたが、進化速度が著しい現在のIT技術では通用しなくなっています
![]()
でも先進技術をビジネスに取り入れるのにもリスクはありますよね?
![]()
確かにスタートアップのサービスは、社会実装するにはあまりにも不安定なのです。ただ、そのリスクを受け入れた先行企業だけが、マーケット独占を狙えるのです。
しかも大企業は特に日本の大企業は総じて決断が遅いので、先行する技術になかなか追いつけません。というのが、現在のAIテクノロジーを取り巻く状況なのです
![]()
そういえば日本の大企業に新サービスを売り込もうとしても、”実際に導入した実績はありますか?”と絶対聞かれると嘆いていた営業がいましたね

![]()
また脇道に逸れているのでLLMの話に戻します。LLMの概要は比較表までとして、個別のSLM技術をいくつか紹介しましょう。まず2024年5月に発表されたGoogle DeepMindの”Gemma 2”(註2)です。6月から一般提供が開始されたオープンソースの軽量言語モデルで、90億と270億パラメータの2種類のモデルがあります
![]()
GPT-3は、たしか1750億パラメータ程度だからずいぶん少ないですね。これで本当に性能が高いのですか?
![]()
270億パラメータ版は、同クラスで最高の性能を発揮し、2倍以上の規模のモデルに匹敵する性能を実現。90億パラメータ版でも、MetaのLlama 3の80億パラメータ版などを上回る性能を発揮する、とベンチマーク結果を示して発表しています。しかも小型軽量のオープンソースなので、誰でも実際にゲーミングPCクラスがあれば、その性能を確認できます
![]()
LLMを単純に小型化しただけでは、当然性能は悪くなりますよね。どうやって性能を向上させているんですか?
![]()
いくつかテクニックがあるのですが、ひとつだけ紹介すると、知識蒸留があります。ニューラルネットワークのモデルは、大きいほど汎化性能が高く、学習効率も高いことはわかっています。説明したスケーリング則ですね。
しかし大きなモデルは、推論時(実際の利用時)の計算コストが大きいという問題があるため、使用可能なハードウエアリソースに制約がある場合は使えません。
そこで事前学習時には大きなモデルを利用し、個別のタスクで使う場合には、小さなモデルに学習結果を移すことが考えられました。これが知識蒸留です
![]()
巨大なネットワークのLLMで学習したら、莫大なパラメータ数があるはずですよ。それをパラメータ数がはるかに少ないSLMに移すと、実際に利用する性能が悪くなるはずですが
![]()
当然の疑問ですね。汎化性能を保ったまま蒸留できる理由はいくつかあり、まだ未解明の部分もあるのですが、ここも単純化して説明します。
LLMで学習が終わって汎化性能が高いパラメータが決定すれば、学習時の最適化に必要だったパラメータは、推論時は冗長となるので消去ができます。そのため推論時のモデルを大幅に小さくすることができるようになるのです。
SLMの説明途中ですが、講義が長くなったので今回はここで終わります。次回も引き続きSLMの説明になります
・テクノ信奉者が大半のAI開発者によって、AI開発は先鋭化していっている。
・LLMに対抗する小規模言語モデルSLMも技術革新が続き、安価で高性能かつ扱いやすいモデルが続々と登場している。
・SLMはパラメータ数を大幅に減らしてモデルサイズを小さくしているが、性能は下がらないように様々なテクニックが用いられている。
著者:谷田部卓
AIセミナー講師、著述業、CGイラストレーターなど、主な著書に、MdN社「アフターコロナのITソリューション」「これからのAIビジネス」、日経メディカル「医療AI概論」他、美術展の入賞実績もある。
メルマガ登録をしていただくと、記事やイベントなどの最新情報をお届けいたします。
学びをシェアする



30秒で理解!インフォグラフィックや動画で解説!フォローして『1日1記事』インプットしよう!























データ越境者に寄り添うメデイア「データのじかん」が提供する便利ツールです。
本ツールは、JavaScriptを用いてお客様のブラウザ上で処理を行います。サーバーとの通信は行われず、入力データはお客様のみの端末内で処理されます。






































前回の講義の最後に、先生はASI(超知能)が誕生すると人類を滅ぼすとか言ってましたね
そこまでは言っていません。ASIを生み出すために大量のAGIを利用するアイデアは面白いと言っただけです。実現性があるかどうかは別の話ですよ
しかしOpenAIは、人類を絶滅させる可能性があるASI開発を、どうして強力に進めようとしているのですかね。そもそもそれ以前に、どんな仕事もできるAGIができて普及したら、世界で大量の失業者がでるのは明らかじゃないですか
OpenAIだけではなく、今シリコンバレーではAI規制に反対する“e/acc(効果的加速主義)”と呼ばれるAI推進者が多いからです。この人たちの思想は、そもそも現生人類がこのまま存続することを前提にしていないのです。
人類も他の生物同様に、進化していくことを期待しているのです。つまり”脱人間主義“なので、ASIを望んでいるのでしょうね。2900万部売れた劉慈欣『三体』の登場人物たちが人類に深く絶望する気持ちに共感しているのかもしれません。
私も意見の対立をいつまでたっても戦争や暴力でしか解決できないような人類は、さっさとバージョンアップすべきだと考えていますよ
なるほど……、などとは、とても同意できない極端なテクノロジー信奉者たちだな。このままいくと、ユヴァル・ノア・ハラリの『ホモ・デウス』にある”ホモ・デウス(神人)”と”無用者階級”に、世界は分断されてしまうじゃないですか
テクノロジーに自由を与えれば可能な限界まで進歩していく、これは”テクニウム”と言われています。テクニウムとは、いわばテクノロジーの生態系で、人間がテクノロジーを利用しているのではなく、自律的なある種の生命体であるテクノロジーが人間に寄生して増殖し、より高度にテクノロジーを進化させているのだ、という思想です
それにしてもAI研究者たちは、ハラリの言う”テクノ人間至上主義”だらけだ。先生、ボクのさっきの質問”このままだと世界が失業者だらけになる”にまだ答えていませんよ
少なくともOpenAIのサム・アルトマンは、2023年に”ワールドコイン財団」を設立して、全世界80億人にワールドコインを支給し、ベーシックインカム(BI)を実現しようと壮大なビジョンを描いています。すでにAGI研究者たちは、AGI時代に備えて様々な種類のあるBIの実現方法について、研究を始めています(註1)
ベーシックインカムか。そういえばそんなニュースがありましたね。一時期評判になりましたが、AGIが世界から仕事を奪ってしまうのを見越して、罪滅ぼしのためにベーシックインカムをやろうとしていたのか。さすが大金持ちのアルトマンは深謀遠慮ですね