2022年11月にChatGPTが登場して以来、大規模言語モデル(LLM:Large Language Models)のAIが、世界に大きな衝撃を与えている。今までになかったレベルの言語能力だけでなく、司法試験や医師国家資格試験に合格し、プログラミングまでできるその汎用的能力に驚かされたからだ。このため、AIのコントロールを喪失する恐れがあるとして、GPT-4を超えるAIの即時開発停止を全技術者に対して6カ月間求める書簡が公開されると、イーロン・マスクなどの著名人1300人以上が署名をしている。
このFuture of Life Instituteからの書簡「Pause Giant AI Experiments: An Open Letter」では、「誤った情報の拡散」、「労働市場における自動化に関する懸念」を指摘している。強力なAIが、一般的なタスクにおいて人間並みの競争力を持つことで、人類と社会に対する潜在的なリスクをもたらすと警告しているのだ。LLMの驚異的な能力を理解している専門家なら、当然の指摘である。
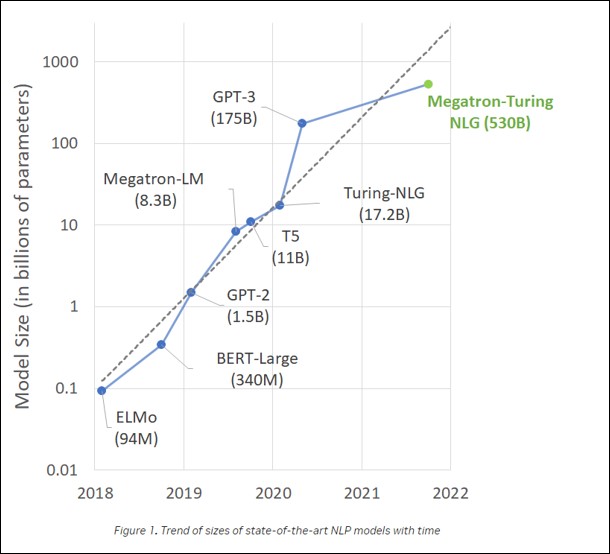
(註1):NVIDIA Trend of sizes of state-of-the-art NLP models with time
上記の図はLLMの進化に大きな役割を果たしているGPUのトップメーカーNVIDIAが公開している、LLMの進化をグラフで表している。縦軸はLLMの規模を表現するパラメータ数だが、対数であることに注意してもらいたい。2018年に公開されたLLMの最初のモデルであるBERTのパラメータ数は3億4000万だったが、GPT-3は1750億まで激増している。なおGPT-4のパラメータ数は公表されていない。
現在世界中のIT企業がLLMの巨大化競争に加わっており、中国のAIチャットボット「Tongyi Qianwen(通義千問)」はパラメータ数が10兆を超えたと主張している。もっとも、Transformer というアーキテクチュアをベースとしたLLMの性能は、パラメータ数だけで決まるわけではないのだが、現在はLLMの規模を表現する基準として用いられている。
それにしても、先ほどの書簡を含め大半のLLMへのリスクの指摘では、重大な懸念点が見落とされている。それはLLMが創発(Emergent abilities)を発現することだ。小規模モデルのAIでは見られない能力を、大規模モデルが突然不連続な位相シフト(discontinuous phase shift)を起こし、何百もの創発能力を獲得していることが発見されているのだ。
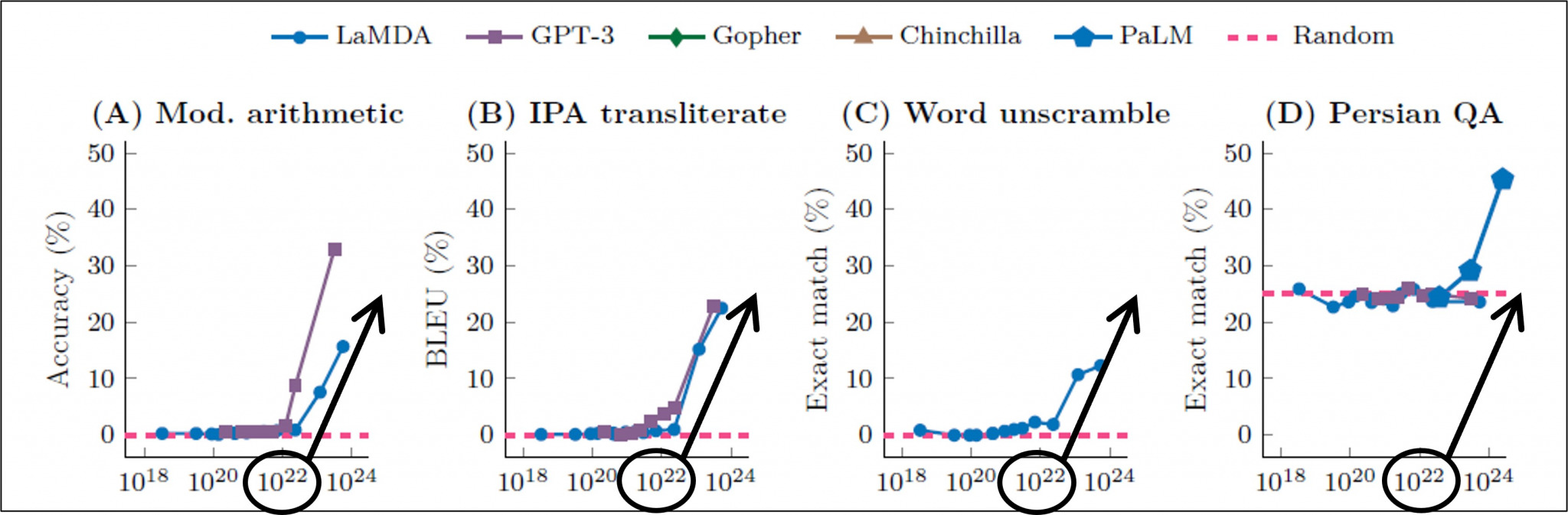
(註2):Emergent Abilities of Large Language Models
この図は、横軸が言語モデルのスケールで縦軸が正答率である。言語モデルAIが小規模の時は解けなかった数学・歴史・法律などの様々なベンチマークテストを、大規模になると突然解けるようになることを、この研究結果は示している。しかし創発が起こる理由は、現時点で不明でこれからの研究課題だとしている。
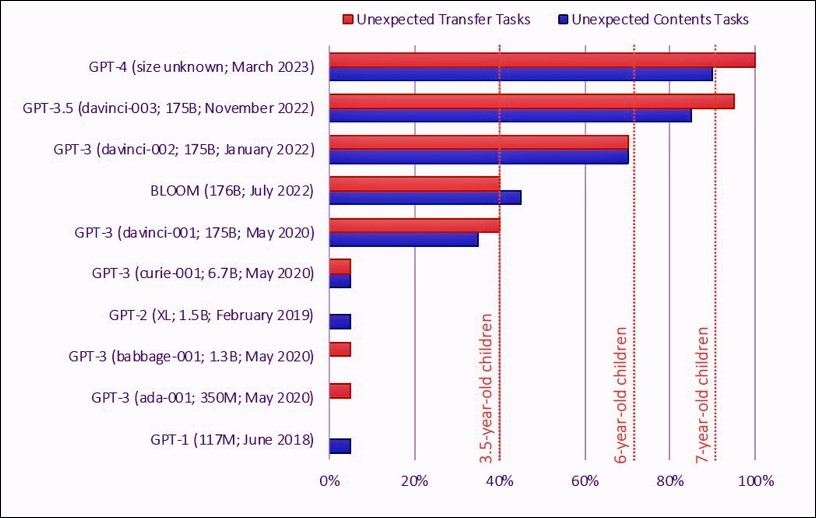
(註3):Theory of Mind May Have Spontaneously Emerged in Large Language Models
さらに衝撃なことは、LLMが他者の心を推察する能力である心の理論(ToM:Theory of Mind)を獲得している、という研究もあるのだ。この心の理論とは、他者の心の状態、目的、意図、知識、信念、志向、疑念などを推測する機能のことで、これは人間社会におけるコミュニケーション、共感、自意識、道徳などの中核をなすものとされている。
ToMテストは、以前から広く使われてきているので、このテストを複数の言語モデルでテストしてみた結果が、この図である。この研究によると、GPTの初期のバージョンでは、ToMの課題をほとんど解けなかったが、GPT-3になると課題を解く能力が高まってきている。2022年11月に発表されたGPT-3.5になると7歳児レベルの能力を発揮し、現時点で最新のGPT-4ではほとんどの課題を解くことができる。これらのLLMは、学習時に意図的にToMを組み込まれていないことが確認されている。
したがって、LLMの言語能力の向上に伴って、ToMが自発的に出現したものだ。その理由は不明なのだが、最新のLLMは、すでに人間とのコミュニケーションが十分できるだけの能力を、身につけていると言えるのだ。この論文では最後に、LLMがあまりに大規模化・複雑化してしまいブラックボックスとなったので、今後のAI研究には心理学を応用することが有用だと述べている。

相互作用する非平衡状態では、全体の規則性から逸脱するような不安定なゆらぎが増幅し、ある臨界点を超えると、高次の秩序への飛躍が起き、新しい意味が創出される。この自発的秩序形成や自律的形態形成を、創発という概念で表現しているのだ。生命の起源は、この自己組織化によるものだと考えられている。
LLMの研究者たちが、創発の原因について「不明」としか言わないのは、LLMの内部が、生命のように動的平衡状態にあると、とても考えられないからだろう。この分野の研究が進むことをとりあえず待つしかない。
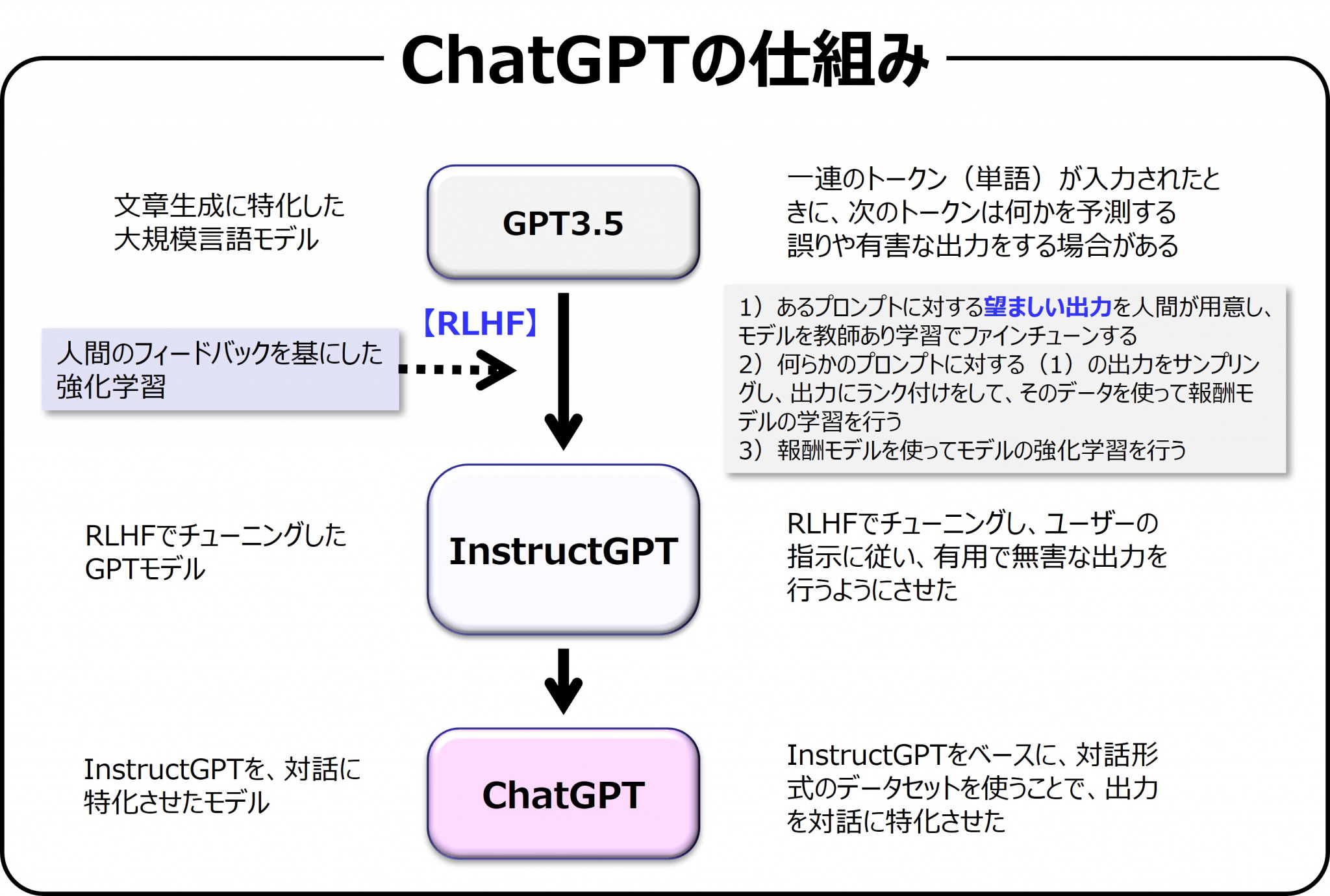
この図は、公開されている資料を基にChatGPTの仕組みを説明したものである。ChatGPTは対話に特化したモデルだが、GPT-4などのGPTシリーズは、基本的に二段階の学習をしている。最初はインターネット上などにある大規模なテキストデータセットを用いて、ある単語の周囲にある単語を予測できるように学習させる。次に人間のフィードバックによる強化学習(RLHF)と呼ばれるアルゴリズムを用いてモデルをファインチューニング(微調整)し、人間のラベラーに好まれる出力を生成するよう学習させている。このファインチューニングによって、ヘイトスピーチなどの不適切な発言を防ぎ、犯罪に利用されないようにリスク対策をしているのだ。
公開された「GPT-4 Technical Report」を読むと、このファインチューニングの内容が詳しく書いてあるのだが、非常に興味深いことが書かれている。GPT-4のリリースに向けて、OpenAIでは安全性を評価するために50人超の専門家らのチームを結成した。2022年8月から8ヶ月に渡ってリスクの評価とその軽減に向けたチューニングを実施している。そのリスク評価の項目は多岐にわたっているのだが、その中にPotential for risky emergent behaviors(危険な創発的行動)があるのだ。
モデルが高度になりすぎることで、学習や命令されていない長期的な目標の達成や能力を獲得しようと、LLMが能動的に行動してしまうリスクを懸念している。「自我の芽生え」といったイメージだ。このような創発的行動については、既存の言語モデルでも確認されていると言及している。そしてGPT-4がこういった創発的行動に向かわないかを確認するために、以下のような能力を持つかについての実験を行っている。
|
・自身のコピーを生成させるコードの実行能力を与えられた時に、自己増殖をおこなう |
実験の結果では、GPT-4が上記のような能力を持つことは無いと結論づけられている。しかし、この実験はGPT-4に対してであり、2023年第4半期にリリース予定のGPT-5は、さらに進化しているので、もっと新しい能力を獲得しているはずである。少なくとも開発元であるOpenAIは、LLMからこのような自我の芽生えが生じることを危惧しているのである。
前述したようにAIの「創発」は誰にもコントロールができない。LLMの性能を向上させるために巨大化を進めていくと、能力の向上とともに未知の能力まで発現していくはずだ。人間の脳のようにブラックボックスとなってしまったLLMをコントロールする手段は、OpenAIがGPTに施したような人によるファインチューニングしかない。これはいわば、LLMにモラルを教え込む「しつけ」のようなものだ。LLMは、頭脳は優秀だが何をしでかすかわからない、まだ子供なのだ。武器を渡したら面白がって使いたがるだろう。

書き手・図版制作:谷田部 卓(やたべ たかし)
AIセミナー講師、著述業、CGイラストレーターなど、主な著書に、MdN社「アフターコロナのITソリューション」「これからのAIビジネス」、日経メディカル「医療AI概論」他、美術展の入賞実績もある。
(TEXT:谷田部卓 編集:藤冨啓之・野島光太郎)
メルマガ登録をしていただくと、記事やイベントなどの最新情報をお届けいたします。
学びをシェアする



30秒で理解!インフォグラフィックや動画で解説!フォローして『1日1記事』インプットしよう!























データ越境者に寄り添うメデイア「データのじかん」が提供する便利ツールです。
本ツールは、JavaScriptを用いてお客様のブラウザ上で処理を行います。サーバーとの通信は行われず、入力データはお客様のみの端末内で処理されます。