


以前は一部の凄腕エンジニアしか実現できなかったビッグデータの分散処理。それを誰でも可能にしたのがApache Hadoop、Apache Sparkに代表される分散処理フレームワークです。ビッグデータ活用に取り組むなら、それらについて概要だけでも知っておくべきでしょう。
この記事では、そもそもの役割からHadoopとSparkの違いまで、分散処理フレームワークについて初心者でも簡単に理解できるよう解説します!

データを管理・活用するためのシステムとして代表的なのがMySQL、OracleなどのRDBMS(リレーショナルデータベース管理システム)です。RDBMSは複雑なデータをリアルタイムで取り扱える半面、大量のデータ処理に際して能力が低下してしまうという弱点があります。
そこでDBでの処理では追いつかないデータ量を高速処理するために導入された概念が“分散処理”です。分散処理では、複数のサーバーもしくはCPUでデータを分割し、大量のデータを高速で処理できるようにします。たくさんのパソコンが作業を分けあって処理している様子を思い浮かべるとわかりやすいでしょう。
分散処理は気象・災害予測や遺伝子解析、SNSのリアルタイム解析、サイトのユーザー行動分析など大量のデータ処理を必要とする作業に用いられます。ビッグデータの取り扱いにおいて分散処理は欠かせない要素であり、昨今その需要は高まり続けています。

システム開発において、フレームワークは「システムに機能を組み込む際に使えるひな形」を指します。フレームワークを用いることでシステム開発者は、高度な技術を学習する時間や一から開発する手間を抑えられます。
分散処理の機能を組み込む際に使えるフレームワークの代表格がHadoopとSpark。Apacheソフトウェア財団の下で開発されたオープンソースのフレームワークで、2018年に発表されたデータサイエンティストに求められる技術的なスキルのランキングでは、Hadoopが4位、Sparkが5位にランクインしました。データサイエンティストを目指す方は特に理解を深めるべきキーワードだといえるでしょう。
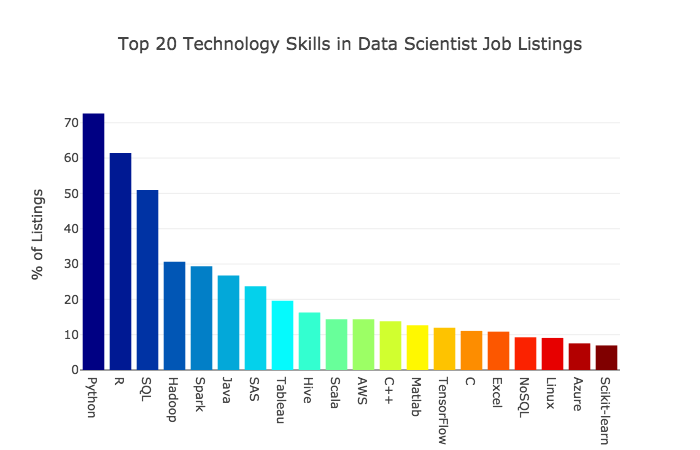
出典:The Most in Demand Skills for Data Scientists┃Jeff Hale(Medium)
ここからはHadoop、Sparkについてより詳しく見ていきます。
1 2 ![]()
メルマガ登録をしていただくと、記事やイベントなどの最新情報をお届けいたします。
学びをシェアする



30秒で理解!インフォグラフィックや動画で解説!フォローして『1日1記事』インプットしよう!























データ越境者に寄り添うメデイア「データのじかん」が提供する便利ツールです。
本ツールは、JavaScriptを用いてお客様のブラウザ上で処理を行います。サーバーとの通信は行われず、入力データはお客様のみの端末内で処理されます。




































