「このデータベースから月次の売上を集計したいけど、SQLを組み立てるのが手間…」
「JOINやGROUP BYが絡むと、毎回ググりながら書いている……」
そんなときこそ、ChatGPTの出番です。
ChatGPTは、SQLの構文を知らなくても、「やりたいこと」をそのまま自然文で伝えるだけで、目的に合ったSQLクエリを自動生成してくれます。
このようにデータの構造と目的を簡潔に伝えるだけで、ChatGPTは次の通り、解説付きでSQL文を記述してくれます。

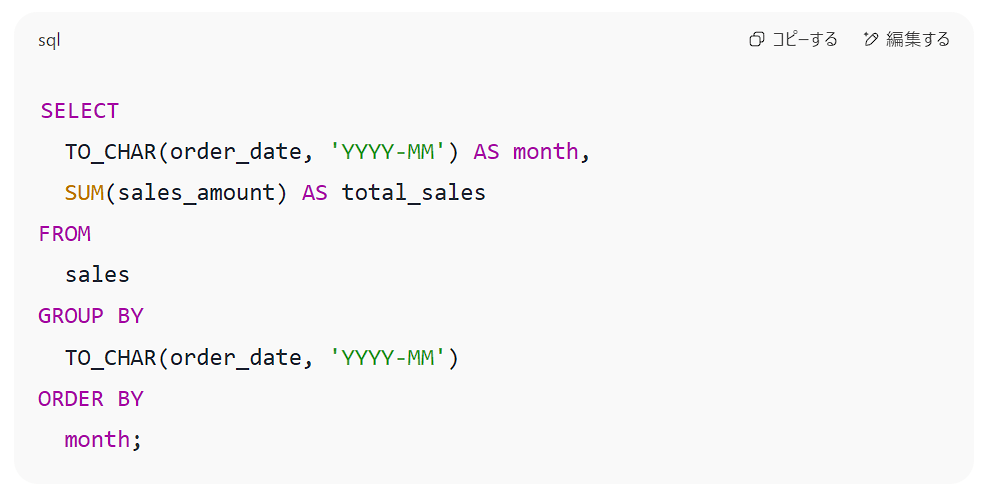
ChatGPTは、PostgreSQL、BigQuery、MySQL、SQL Serverなど、主要なデータベースのSQL構文(方言)に対応したクエリを生成することができます。プロンプトの中で「BigQuery」や「MySQL」などと指定するだけで、SQLの方言にも自動で対応してくれるのは大きな利点です。
ただし、生成されたSQLをそのまま本番環境で使うのは避けた方がよいでしょう。
ChatGPTは非常に高精度とはいえ、実際のテーブル構造を把握しているわけではありません。そのため、存在しないカラム名を使っていたり、NULL処理やデータ型の扱いに誤りがあったりするケースもあります。また、パフォーマンスやインデックスへの配慮が不足している場合もあるため、出力されたSQLはあくまで「たたき台」として捉え、自分の環境で必ずテスト・検証を行うことが大前提です。
より正確なSQLを得たいなら、テーブル構造をあらかじめ伝えておくと効果的です。たとえば、以下のように指示してみてください。
欠損値の処理・文字列の整形・不要な列の削除など、分析に取りかかる前の“前処理”に一番手間がかかっていると感じる方は少なくないでしょう。
そうした前処理作業でも、ChatGPTは大いに機能します。CSVやExcelファイルの内容をコピーして貼り付ける、あるいはファイルそのものをアップロードしたうえで、「この列の欠損値を平均で埋めて」「文字列になっている日付をdatetime型に変換して」「使っていない列は削除して」といったように、やりたいことをそのまま伝えるだけで、pandasなどを使ったPythonコードを即座に提案してくれます。
ChatGPTが返してくれるコードは以下のようなものです。

このように、自然な日本語で指示を出すだけで、実務でそのまま使えるコードが自動的に生成されます。特に、「関数が思い出せない」といった初心者にありがちな悩みも、ChatGPTを活用すれば大きく軽減できます。さらに前処理の過程では、「こんな処理も必要だったのか」と気づかされることも少なくありません。たとえば、数値なのに文字列として読み込まれていた列に対して自動で型変換を提案してくれたり、カテゴリ変数の扱い方について補足してくれることもあります。
ただし、ChatGPTはデータの“意味”そのものを完全に理解しているわけではないため、提案されたコードを人間が試し、確認するフェーズは必要ということも押さえておきましょう。
「手元にデータはあるけど、どんな切り口で分析すればいいかわからない」
「どの項目に着目すべきか、誰かに相談したい……」
そんなとき、ChatGPTは非常に強力な壁打ち相手になります。アップロードしたデータの内容や、自分の業務背景を伝えるだけで、分析の切り口や有効な視点を提供してくれます。
このような指示を出すと、ChatGPTは以下のようなアイディアを返してくれました。
| 分析対象 | グラフ形式 | 備考 |
| 部署ごとの平均満足度 | 棒グラフ | 水平方向に並べて見やすく |
| 職位別満足度 | 棒グラフまたは箱ひげ図 | 分布を見る場合は箱ひげ図も有効 |
| 部署×職位ごとの平均 | ヒートマップ | 一目で“どこに課題が集中しているか”が分かる |
| 全体の満足度分布 | ヒストグラム | スコアの偏りを把握 |
| 部署別満足度のばらつき | エラーバー付き棒グラフ | 平均+標準偏差で“安定性”も視覚化 |
このように、自分では思いつかなかった視点や比較軸を次々と提案してくれ、必要とあらば具体的な可視化コードも用意してくれるChatGPT。続けて「KPIに使えそうな指標は?」「なぜこの数値が高いのかを調べるにはどうしたらいい?」と聞けば、さらに役立つ視点や具体的な比較方法を提案してくれるため、ただの“道具”としてではなく、“相談相手”として活用できます。
もちろん、提案された内容すべてが正しいとは限りませんが、「とりあえず聞いてみる」ことで思考が進むのは大きなメリットです。
データとにらめっこする時間が長くなったら、まずはChatGPTに相談してみましょう。
集計したデータの可視化にはデータの集計や分析とまた違った技術が必要とされるため、苦手な方も少なくありません。とはいえ、データの中にある特徴や傾向を“視覚的に伝える”ことは、意思決定や共有の場面では非常に重要です。そこでもやはりChatGPTは役立ちます。
最近では、Python、Excel、Googleスプレッドシート、BIツールと、可視化の選択肢は豊富にあります。重要なのは、「どんな目的で誰に何を伝えたいのか」そして「自分が使いたい・使えるツールは何か」を明確にした上で、最適な手段を選ぶことです。
たとえば、Pythonを使う場合は、ChatGPTに次のような指示を出すだけで、グラフを描くためのコードを生成してくれます。
すると、ChatGPTは次のようなPythonコードを返してくれます:
sales.csvのファイルをアップロードしたうえで上記のコードをGoogle Colab上で実行させたところ、以下のように、月別の売上合計が表として描画されました。
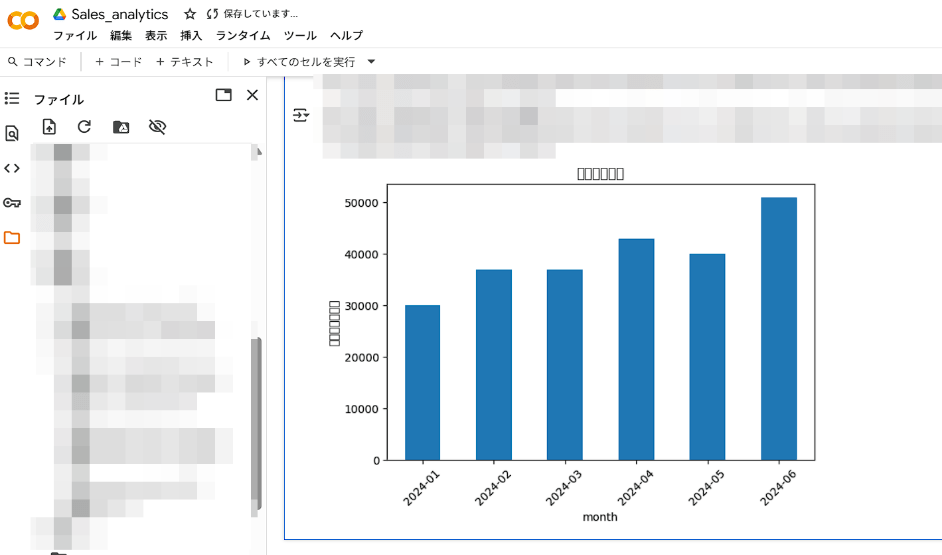
グラフ作成は、Python初心者にとってハードルが高く見えがちですが、ChatGPTに頼れば、ライブラリの使い方を覚えなくても、目的の図を生成することが容易になります。たとえば、以下のようにさらに細かく指示を出すことで、データの表現方法はより多様かつ高度になるはずです。
・折れ線グラフや円グラフなどの種類変更
・色やフォント、軸ラベルなどのデザイン調整
・データの一部フィルタ(例:特定の月だけ抽出)
・インタラクティブなグラフにしたい場合はplotlyを使うよう依頼
ChatGPTを使っていて、「あれ、計算結果が間違っている?」「値が合っていない?」と感じたことがある方もいるかもしれません。
実際、ChatGPTは“言語モデル”であり、数学的な演算処理そのものを内部で正確に行っているわけではありません。とくに長い数値や小数点以下の精密な計算、統計的な推定値などでは誤差が生じることがよくあります。
これらに対し、どう対策すればよいのでしょうか?
考え得る方法は、「コードで出させて、そのコードを実行する」というプロセスを徹底することです。
たとえば、月次売上データ(sales.csv)の平均値を出したい場合は、「このデータの平均を教えて」ではなく、以下のように指示を行います。
このように、計算結果そのものはGoogle ColabやローカルのPython環境で実行して得るというスタイルであれば、ChatGPTの特性を生かしながら正確な数値を出すことができます。その際、データ型や前提条件を事前に共有する、一つずつ指示を行う(ステップバイステップ)といったポイントを押さえることも有効な工夫となるでしょう。
ChatGPTなどの生成AIは「データ分析をともに進めるパートナー」として十分に活用できる段階に来ています。
もちろん、数字の精度や実行環境への反映など、人間の目で確認すべきポイントもありますが、データ分析の速度・質を大きく変えてくれるのは間違いありません。
まずは、あなたの業務で繰り返している作業や、アイディアが煮詰まっている場面からGPTに自然な言葉で相談を持ち掛けてみることをおすすめします。
(宮田文机)
メルマガ登録をしていただくと、記事やイベントなどの最新情報をお届けいたします。
学びをシェアする



30秒で理解!インフォグラフィックや動画で解説!フォローして『1日1記事』インプットしよう!