



時系列処理のモデル ※図版:著者作成
![]()
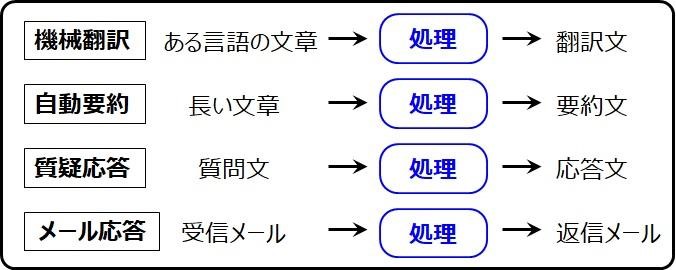
では前回の宿題だった大規模言語モデル(LLM:Large Language Model)の説明をしましょう。この図ですが、機械翻訳や自動要約、質疑応答などは、同一のモデルで表現できることを示しています
![]()
確かにこのように単純なモデルにすると、なんらかの処理をすれば実現できるように見えますね。でもこれは、それこそ“絵に描いた餅”で、本当にそんなことができるのですか?
![]()
前回説明した時系列ニューラルネットワークであるRNNの発展形Seq2Seq(Sequence to Sequence)を用いれば、実現可能になってきたのです。この図の4つの事例は、ある時系列データを、別の時系列データに変換する、と言い換えてもよいはずです。つまりニューラル言語モデルは、入力された時系列データから、出力単語の確率分布を求めるモデルです。したがって、ある時系列データが入力されると、コーパスの統計結果から、最も出現確率の高い単語列を計算して出力ができるようになるのです
![]()
そう言われると、できそうな気もしますね。しかしこの場合、学習したコーパスになかった文章は出力できないのでは?
![]()
基本的に単語とその前後の単語での確率分布なので、コーパスになかった単語列、つまり文章でも出力できるようになります。もちろんその精度は、学習するコーパスの質と量に依存しますが
AIモデルの比較 ※図版:著者作成
![]()
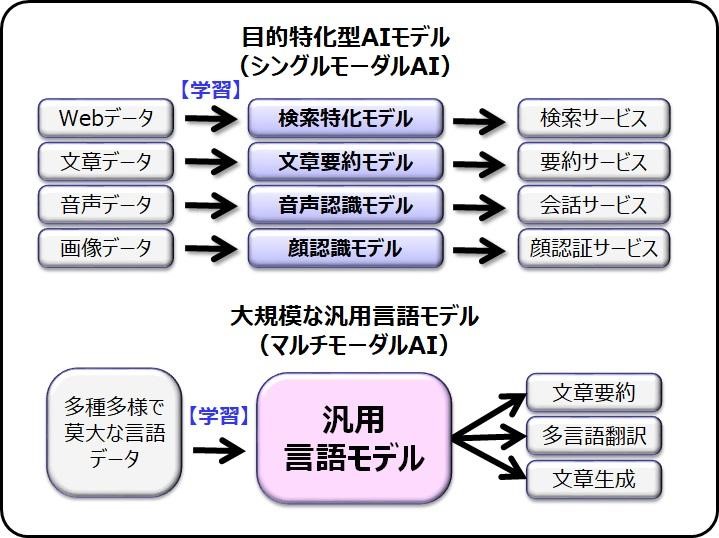
図の上ですが、つい昨年前半まで主流だったAIは、このような目的特化型のAIでした。つまり、特定のジャンルのデータだけ学習しているので、顔認証専用とか要約専用のような単機能しかないAIのことです。
次に、先ほどのSeq2Seqの発展型であるTransformerというアルゴリズムを基本とした言語モデルが登場しました。そのモデルを単純に巨大化したのが、大規模言語モデル(LLM)です。このLLMが驚くべき性能を示して、あらゆるタスクをこなせる汎用言語モデルとなり、世界中の研究者がヒートアップしたのです
![]()
巨大化とは、なにを巨大化したのですか?
![]()
それまでAIを学習させるための教師データは、アノテーションという個々のデータに対してタグ付け作業が必要なために、学習コストが非常に高かったのです。それが自己教師あり学習のできる言語モデルや画像モデルが登場し、学習の精度が向上して学習コストが大きく下がったのです。そしてニューラル言語モデルの、パラメータ数を数千億まで増やし、ハードウェア規模を巨大化させることで、数十テラバイト級のテキストデータが学習できるようになったのです。大評判になったChatGPTは、この言語生成AIであるLLMを、会話用に特化させたものなのです
![]()
どうしてLLMを会話専用にしたのでしょうか?
![]()
AIを一般の人に広く利用してもらおうとしたら、AIに言葉で話しかけるチャットが最もよいと考えたのでしょう。しかもLLMなら人間並みの文章を生成できるようになったので、まず自然言語でのインターフェースにして、その能力を示したかったのでしょう
![]()
しかしチャットボットなら以前からありましたよ
![]()
従来のチャットボットとはレベルの異なる会話能力があるからなのですが、人と会話する理由もあるのです
![]()
え?なんですか?
![]()
それはユーザーと会話することで、ユーザーがどんな答えを求めているか、どんな価値観を持っているかを学習できるからです。検索だと結果を複数表示するだけですが、会話だとユーザーは期待した回答ではないと、否定をしたり別の言い回しで再質問するので回答精度の向上が期待できるのです
![]()
検索エンジンでも、ユーザーが複数の結果から選択したURLを学習していますよ
![]()
検索結果の表示とユーザー選択だけでは、肯定か否定かまでは明確にはならないはずです
ChatGPTの仕組み ※図版:著者作成
![]()
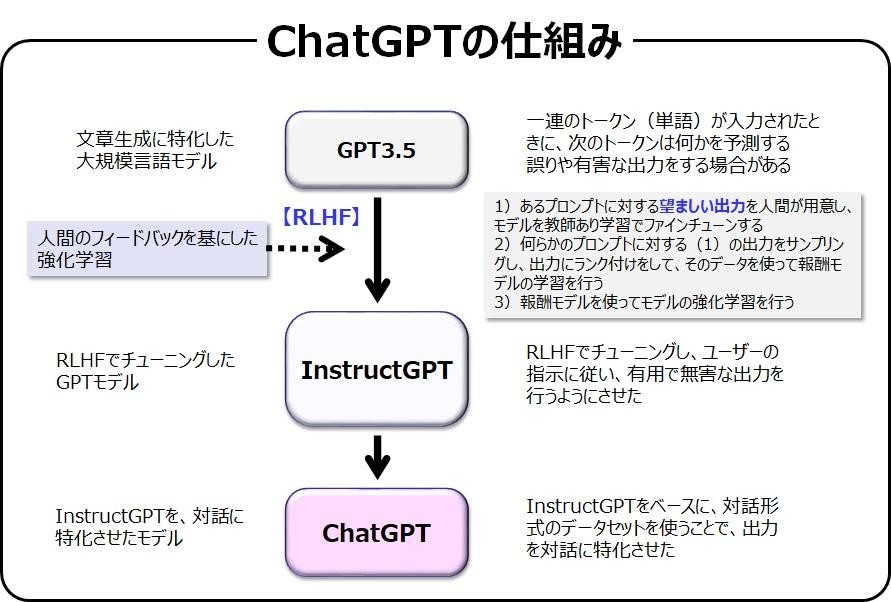
それではChatGPTの仕組みについて、その概要を説明します。ChatGPTを開発しているOpenAI社は、LLMであるGPTシリーズを次々と開発・スケールアップしてきました。GPT-1とGPT-2はオープンソースとして公開しましたが、GPT-3になるとあまりに言語生成能力が高く、このままでは悪用される恐れがあるとして学習済みモデルを非公開にしています。
![]()
まぁ今のChatGPT騒動をみていると、賢明な判断でしたね
![]()
図のGPT3.5はLLMであるGPT-3をさらに拡張したモデルで、これにファインチューニングしたものがInstructGPTになります。このファインチューニングは、GPTの欠点である差別発言や犯罪手法などの有害情報を出力しないように、人が作成した大量の教師データを学習させる行為のことです
![]()
初期のころのAIは、公開直後にヘイト発言を繰り返してすぐに非公開になることがよくあったので、このような仕組みにしたのですね。でもLLMにヘイト発言をしないような“モラル”を教えるには、やはり人間が教えるしかないのですね
![]()
人類に共通する“道徳の教科書”などというものは存在しないので、最初はゼロから作るしかなかったのでしょう。しかしChatGPTを公開してから様々なフィードバックがあったはずなので、LLMもどんどん賢くなるはずです
![]()
でも、世間ではAIは“平気で嘘を言う”という評判ですが
![]()
ChatGPTなどのLLMは、以前説明したようにTransformerを原理としています。つまりユーザーが入力した文字列(プロンプト)に最も近い確率分布の文字列を出力しているだけなので、質問に対しての正解かどうかは保証できません。原理的に不可能なのです。またWikipediaなどネット上から集めた膨大なテキストデータで訓練しているので、その中に誤りがないとは言えません。しかもChatGPTの学習データは2021年9月までなので最新情報は知らないのです
![]()
だからChatGPTに最新情報を聞いてもダメなのですね
![]()
最新情報を尋ねたいならマイクロソフトが提供しているBingのAIチャットサービスを利用した方がよいです。これは質問に対して最初にネット上にある情報を集約してからGPT-4ベースのLLMが回答を生成しているので最新情報を回答できますし、その情報元となるURLを表示できるので確認が可能です
画像生成AIの仕組み ※図版:著者作成
![]()
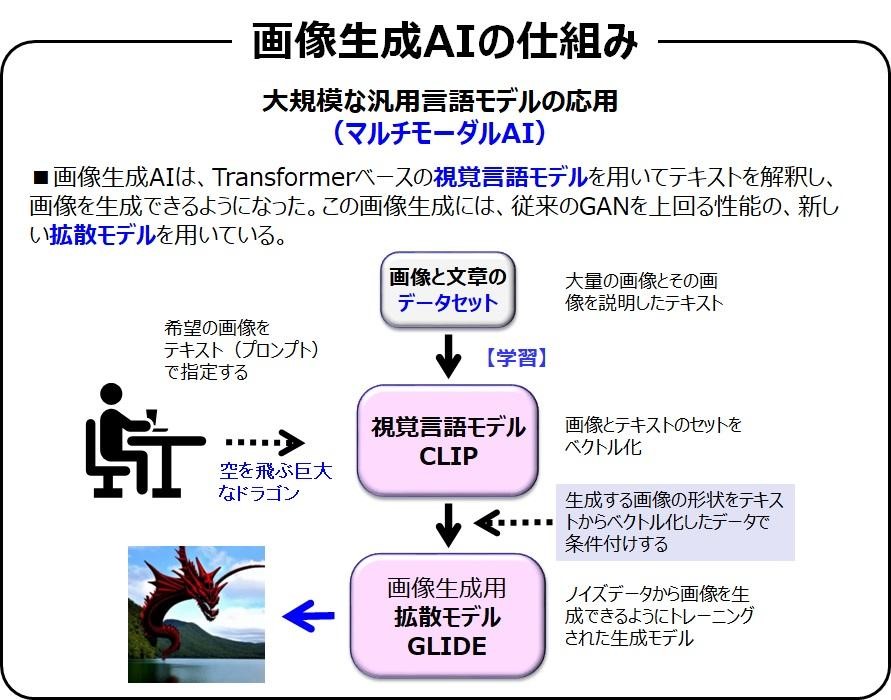
では次に、2022年夏ごろ大評判となった画像生成AIの説明をしましょう。教師画像から獲得したニューラルネットワークの高次元のベクトル値であるパラメータに、可能な限り近似させたベクトル値を生成させます。すると、そのネットワークから教師画像に非常に似た画像が生成できるようになります。GANが最も有名なこの画像生成アルゴリズムです
![]()
なにを言っているか、まったく理解できませんが
![]()
そうですか。前回の講義で、意味のベクトル化を説明しましたが、画像も高次元のベクトル化ができます。似た画像は似たようなベクトルになるので、ターゲットとなる画像と似たベクトルを探せば、似たような画像が探せることになりますね
![]()
そこは理解できます
![]()
図にもあるように、画像とその説明文のセットを高次元ベクトルにしておきます。ユーザーが指定した言葉(プロンプト)から、そのプロンプトに相当するベクトルデータを探して画像生成ネットワークに渡すことで、希望する画像が生成できるのです。申し訳ないですが、画像生成そのものの仕組み・拡散モデルの説明は長くなるので省きます
![]()
漠然とですが分かりました。ただその仕組みだと、学習した画像の中から探しているだけに聞こえますね
![]()
基本はそうなのですが、プロンプトの指示によって選択された複数の画像からその特徴を合成できるので、元画像が分からないほど複雑な画像が生成できるようになります。これが、2022年夏ごろに世界中で大ブームとなった画像生成AIの仕組みです
![]()
そうですか。画像生成AIが創造できるようになったのではないのですね
![]()
人間の画家も、最初は先生からの指導や手本となる絵を見て、技術を習得したはずです。まったくのゼロから絵画を描けるようになった画家はいないはずです
![]()
だからといって、イラストレーターの許可なく絵画やイラストをクローリングし利用してもよいとは言えないのではないでしょうか。日本のイラストレーターたちも集団で抗議を始めたようですね
![]()
2018年に改正された著作権法第30条の4では、AIなどの技術を活用するために、イラストなどの著作物の利用を認める規定が設けられています。ですから現時点で違法ではないですね。もっとも当時はここまでAIが発達して利用されるとは専門家でも予想していなかったので、再検討されるかもしれません
![]()
それにしても、ここまで一気にAIが進化すると我々の仕事は次第に減ってしまいますよ。中国では大勢のイラストレーターが失職したとか、アメリカの大手IT企業もAI活用を理由にして大量の社員を首にしたという報道を見ました
![]()
今回の講座は、自然言語処理の基本の説明からLLMの仕組みまでを駆け足で説明してきました。何度も言いますが、AIは現時点でも毎日のように進化を続けている最中です。AIの進化速度に対して、人間社会の対応はあまりに遅く変化には簡単には追従できません。今後、企業や政府がどのように対応し、仕事がどのように変化していくかは様々な予想がされていますので、この話に関しては別の機会に話をします。とりあえず今回の講義は、ここまでとさせていただきます
どうしてChatGPTを「会話専用」にしたので後記するのか?
AI言語モデルである私の目的は、私に与えられたプロンプトやクエリに基づいて、人間のようなテキストを生成するためにユーザーを支援することです。私は、エッセイの執筆、質問への回答、説明、会話など、さまざまな目的でテキストを処理・生成することができますが、OpenAIは、主に会話のやりとりを得意とするように私を設計しました。
会話は、ユーザーがよりインタラクティブでダイナミックな方法で私と関わることを可能にします。ユーザーから質問を受けたり、説明を求められたり、トピックをさらに深く掘り下げたいときに、特に有効なやり取りができます。会話に重点を置くことで、ユーザーにより魅力的でインタラクティブな体験を提供することができるのです。
ただし、会話に特化したデザインとはいえ、会話の文脈を必要としない特定の問い合わせやプロンプトに対しては、簡潔な答えや情報を提供できることも重要なポイントです。
図版・著者:谷田部卓
AIセミナー講師、著述業、CGイラストレーターなど、主な著書に、MdN社「アフターコロナのITソリューション」「これからのAIビジネス」、日経メディカル「医療AI概論」他、美術展の入賞実績もある。
(TEXT:谷田部卓 編集:藤冨啓之)
InstructGPTにおけるRLHF:https://openai.com/research/instruction-following
Model index for researchers:https://platform.openai.com/docs/model-index-for-researchers
DALL·E 2:https://openai.com/product/dall-e-2
メルマガ登録をしていただくと、記事やイベントなどの最新情報をお届けいたします。
学びをシェアする



30秒で理解!インフォグラフィックや動画で解説!フォローして『1日1記事』インプットしよう!























データ越境者に寄り添うメデイア「データのじかん」が提供する便利ツールです。
本ツールは、JavaScriptを用いてお客様のブラウザ上で処理を行います。サーバーとの通信は行われず、入力データはお客様のみの端末内で処理されます。





































これで最終回の講座となります。AI技術は2023年に入ってから現在も、加速度をつけて進化を続けている最中です
ChatGPTの影響は日本政府まで動かして、G7デジタル相会合の主要テーマにまでなっていますね
私もここまでAI技術が、動きの鈍い日本政府を動かすとは思ってもいませんでした。しかも頭の固い銀行や地方自治体まで、さっそくChatGPTを業務に利用しようとしているのには驚いています