2024年7月5日に発表された『令和6年版情報通信白書』(総務省)では「コンテンツの要約・翻訳」「調べ物をする」など8つの用途における生成AIの利用可能性が紹介されていました。しかし実際に利用するかどうかについて尋ねてみると、調べた項目すべてで「条件によっては利用を検討する」の割合が最も大きかったというデータです。
非常に日本人らしい曖昧な回答のようにも感じますが、もっともな点もあり、その条件として筆頭に上がるのが、‟生成コンテンツの内容や精度を制御できること”ではないでしょうか。
そこで注目したい技術が「RAG(Retrieval-Augmented Generation:検索拡張生成)」です。
この記事ではRAGとは何か、どの様に実践すべきなのかなど、RAGの内実について、多角的な視点から解説いたします!

RAG(Retrieval-Augmented Generation:検索拡張生成)とは、AIがテキストなどの生成を行う前に検索(Retrieval)のプロセスを組み込む手法のことです。
RAGを実行することは、以下のようなメリットをもたらします。
・AIのハルシネーションを軽減する
・コンテンツから倫理的・道徳的に問題のある内容を排除できる
・コンテンツの内容・精度をコントロールできる
AIのハルシネーションとは、生成AIがもっともらしい偽情報を出力してしまう現象を指します。詳しく知りたい方は以下の記事もご一読ください。
『企業IT利活用動向調査2024┃JIPDEC/ITR』によると、企業が各自で契約・登録した生成AIを利用する際に懸念される問題として最も多く回答されたのは「生成AIが出力した偽情報を従業員が信じて業務で使用してしまう」(46.3%)で、それに「生成AIが出力した情報に倫理的や道徳的な問題が含まれている」(39.9%)がつづきました。
通常の生成モデルは大量のデータから事前学習済みの情報をもとに、命令文に対してコンテンツを生成します。その学習データの範囲はAIモデル構築時に規定されており、内容を更新するには開発者によるアップデートが必要となります。既存のAIモデルに特定のデータセットを追加することで特定の業界や目的に合わせてAIモデルを最適化するファインチューニングという手法も、再学習の一部に該当します。
一方、RAGは、生成の際にリアルタイムで検索エンジンを利用して関連する情報を取得し、その情報をもとにテキストを生成します。

RAGを実践するにはどうすればいいのか?
RAGはしばしばカンニングペーパーや教科書持ち込み可能な試験にたとえられます。そのため、RAGの実践は簡素化すれば以下の2つの要素に分解されます。
・カンニングペーパー(データソース)の準備
・RAG機能の実装
前者に関しては設定した目的に合わせてデータベースを用意し、それらをクエリに合わせて適切に検索できるように前処理することになります。そこで、対象のテキストの内容をLangChainやEmbedding API等を用いてベクトル化したり、自然言語で書かれたPDFからテキストを抽出してマークダウン化したりといった処理が行われます。
後者に関しては、GPTsやAzure AI Studio、Amazon Bedrockなどの主要なAIサービスですでに用意されているRAG環境を利用するのが最も手っ取り早い手法です。また、たとえば『ChatGPT + Enterprise data with Azure OpenAI and Cognitive Search』のように、RAGのデモや手順はQiitaやGithubなどで数多くの記事やプラットフォームにて公開されており参照することができます。
ガートナー社が2024年8月7日に発表した『日本における未来志向型インフラ・テクノロジのハイプ・サイクル:2024年』において、RAGは‟「過度な期待」のピーク期”に該当しています。
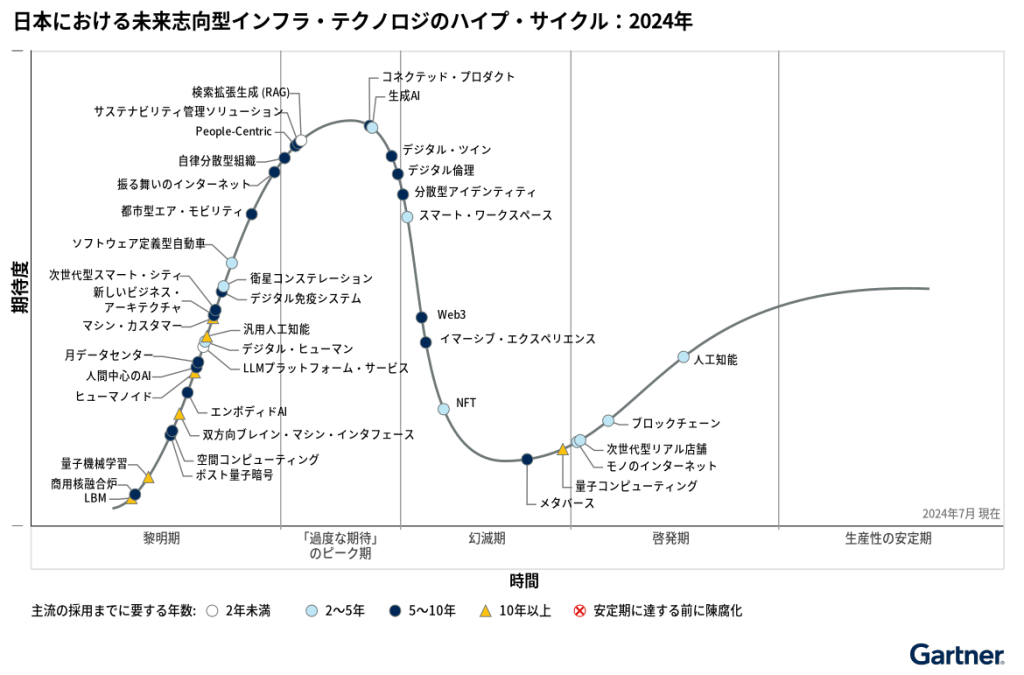
ご覧の通り生成AIがその先に位置し、生成AIブームに追従して注目の集まったRAGという技術はこれからピークを迎えたのち、幻滅期を迎えることが予想されます。
マイクロソフトの研究チームがファインチューニングとRAGを比較した『Fine-Tuning or Retrieval? Comparing Knowledge Injection in LLMs』という論文では、MMLUなどLLMを評価するための複数のベンチマークでRAGを用いた場合のスコアが高かったことが報告されましたが、そもそもRAGとファインチューニングは性質が異なり、また急速な生成AI技術の進歩によりゲームチェンジが起こる可能性が大いにあることには注意が求められます。
生成AIを目的に合わせて最適化するための技術として注目を集めるRAGについてご紹介しました。検索対象として機密情報や他社の著作物を用意することで、情報漏えいや権利侵害といった問題が起こるのではないかなど、RAGに懸念を覚える声もありますが、それはLLMによる生成全般について回る問題でもあります。RAGだけでなく、AI周辺に関しては、今後も多種多様な新しい技術がもてはやされては捨て去られる、というサイクルが激しく繰り返されることが予測されますので、どのような技術であれ、ユーザーがそれぞれの長所短所をある程度把握し、エビデンスを持った上で対策を考えることが重要だと思われます。いきなりAIを全面的に信頼する、というのではなく、補助的な役割としてお試し的にまずは使ってみることが現段階ではよい塩梅なのかも知れません。
・情報通信白書令和6年版┃総務省 ・生成AI、ビジネス継続利用者はわずか7.8%、活用障壁は使い勝手や信頼性に関する項目が上位を占め、サービス導入時はセキュリティを最重視┃AI inside ・RAGとは?仕組みと導入メリット、使用の注意点をわかりやすく解説┃NTT東日本 ・柿沼太一『LLMを利用したRAG(Retrieval Augmented Generation)と著作権侵害』┃STORIA法律事務所 ・企業IT利活用動向調査2024┃JIPDEC/ITR ・【考察】RAGはマニュアル人間で、ファインチューニングは新卒育成?┃LeapWell ・Oded Ovadia, Menachem Brief, Moshik Mishaeli, Oren Elisha『Fine-Tuning or Retrieval? Comparing Knowledge Injection in LLMs』arxiv
メルマガ登録をしていただくと、記事やイベントなどの最新情報をお届けいたします。
学びをシェアする



30秒で理解!インフォグラフィックや動画で解説!フォローして『1日1記事』インプットしよう!























データ越境者に寄り添うメデイア「データのじかん」が提供する便利ツールです。
本ツールは、JavaScriptを用いてお客様のブラウザ上で処理を行います。サーバーとの通信は行われず、入力データはお客様のみの端末内で処理されます。