
目次
こんにちわ、本PJのマーケティングチームのYu Ohtaです。この記事を通じて、「Data Learning Bibliographyはどこをターゲットにしているか?」「使ってもらうためにどのような工夫をしているか?」「プロジェクトを継続するための資金をどのように確保するか」などを理解してもらいたいと思っております。
2020年ごろにデータサイエンスに興味を持ち、スクールや書籍でいろんな内容を学びましたが、その時に思ったのはデータサイエンスに必要な知識は膨大なものであり、それに比例して膨大な書籍やコンテンツがあるという気づきでした。もちろんその中には「初心者」「初学者」用として謳われているものも多くあったため、いろいろ読んでみました。しかし、読んでも「これ明らか初心者用違うやん。。。」という書籍に何度も出会い、かなり回り道をした経験がありました。
このプロジェクトの話をいただいた時、この経験から「効率良く学べる環境づくりをして、データ分析・活用をしたい初学者のハードルを下げたい」という思いを抱き、プロジェクトに関わることとなりました。
ちなみに普段は製造業向けのデータサイエンティストとして仕事をしているので、本業でマーケティング領域に関わったことがありません。しかし、以前からマーケティングには興味があったため、今回は今後の学びのためにプロジェクトのマーケティングに関わらせて頂いております。
Data Learning Bibliographyのマーケティング施策を考えるにあたり、以下の視点を基に考えてきました。
上記に挙げた3つの視点を基に実際に取り組んでいること、これからやろうとしていることを説明していきます。
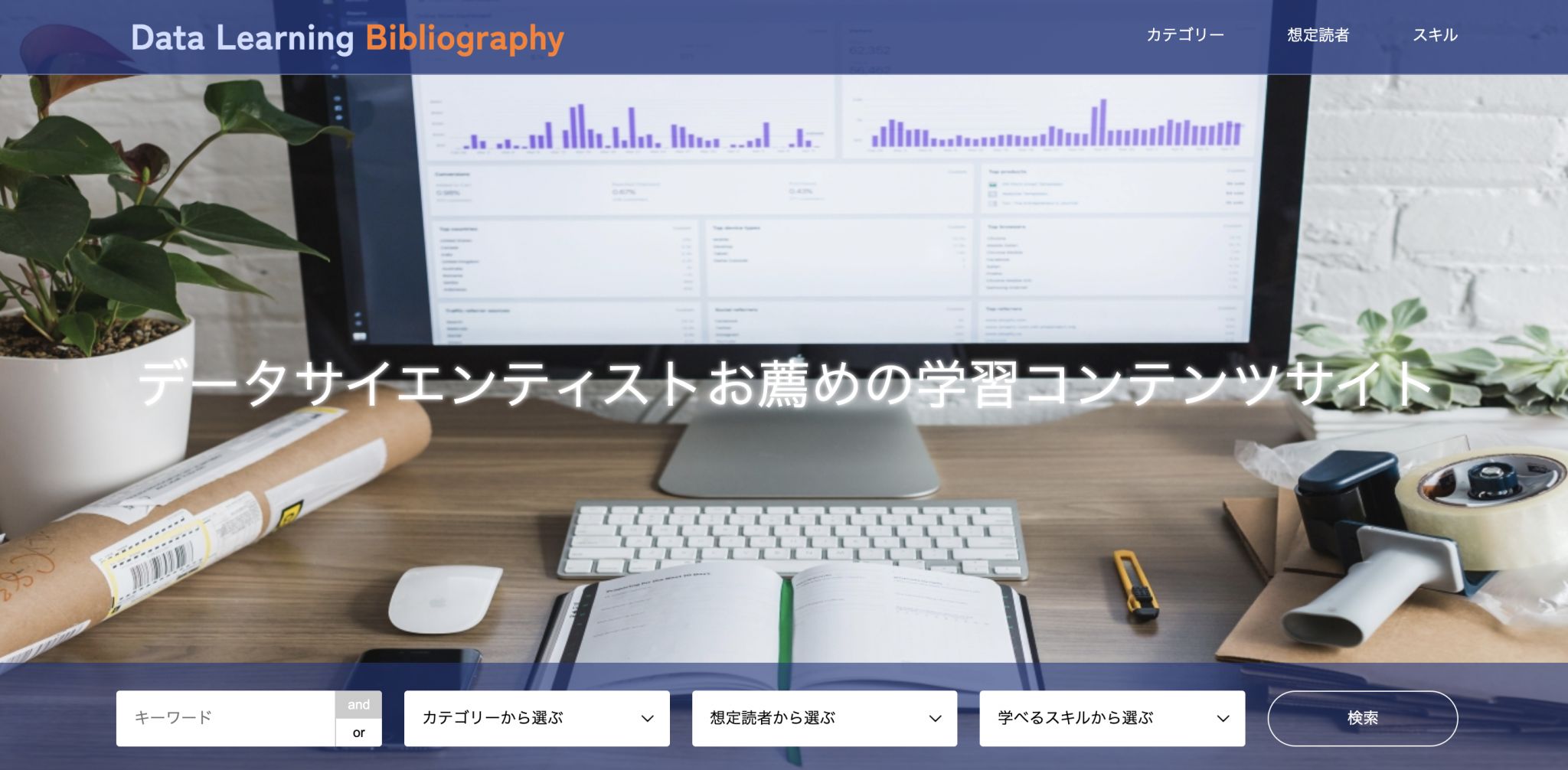
データ領域のWikipediaを目指すData Learning Bibliography
私たちが考えているData Learning Bibliographyが狙うターゲットは、データ分析の初学者の方からデータ関連の仕事を既にしているベテランまで幅広いです。そのため、幅広くいろんな媒体を使って、今までサイトを知らない人が接点を持ったり、見つけてもらう取り組みをこれからやっていこうと考えています。例えば、データ分析の初学者やデータ関連の仕事をしているベテランに対して考えている取り組みを挙げます。
書籍探しの際、amazonや楽天、出版社のWebサイト、本屋などいろんな手段を想起すると思います。
このような状況の中で書籍探しをする際に「これでしょ!!」と想起されるのに必要なものはなんでしょうか?私たちは検索性と網羅性だと思っております。
まず検索性についてですが、データサイエンスの領域では、マーケティングや医療系などカテゴリーも様々ですし、数学やプログラミング、資料作成やマネージングなどスキルも様々なため、コンテンツを検索する際は複数の単語で検索をかける等が必要なため、検索のキーワード選びに苦労します。
そこで、Data Learning Bibliographyでは、スキルタグを設けたり、カテゴリー別にコンテンツ一覧を設けております。
これを設けることによって、幅広い人に検索しやすく、次も使いやすいサイトを目指して作っております。

「Pythonの基本」から「事業への実装」などまで知識から活用するまでの網羅的なスキル軸からコンテンツを検索できる
次に網羅性についてですが、今回データ分析の初学者の方からデータ関連の仕事を既にしているベテランまで幅広いターゲットにしているため、それぞれのターゲットに「これだ!」と思えるコンテンツを検索してもらうには、カテゴリーや必要スキルも多種多様にあることを考えてもかなりのコンテンツ数を揃える必要があります。
しかしながら、立ち上げたばかりのData Learning Bibliographyでいきなり全てを網羅できるようなコンテンツ数を揃えるのは厳しいです。そのため、私たちはまず扱う媒体を「書籍」に、扱うターゲットについては「初学者」に絞る形で最初のコンテンツ拡充を考えております。これは世の中にあるコンテンツボリュームが「初学者用の書籍」が多いという傾向があるのと、まず最低限データサイエンス領域の学習ハードルが一番高い初学者やデータ分析初心者にとって扱いやすいサイトにすることで、効果的なコンテンツ拡充ができると考えております。
これら挙げた検索性や網羅性を兼ね備えたData Learning Bibliographyでは、例えばデータ分析初学者やデータ職種のベテランが以下のメリットを感じていただけると考えています。
一度使ってもらって終わりではなく、継続して使ってもらう取り組みも必要です。 そのためには以下の要素が必要だと考えております。
そのため、サイトやコンテンツを一度作って終わりではなく、今後もサイトをブラッシュアップしていきます。
※サイトのブラッシュアップのため、執筆者など今後も新たに協力していただける方を募集しております。
現在、Data Learning Bibliographyはクラウドファンディングで支援して頂いた資金を活用し、有志のコミュニティメンバーが中心でサービス開発を行なってきました。しかし、今後Data Learning Bibliographyを運営するのに、以下の要素が必要不可欠になります。
そのため、クラウドファンディングで支援いただいた資金だけでは足らないため、サイトのマネタイズも考えていく必要があります。 しかし、今後もデータに関わる幅広い層の人にこのサイトを使ってもらうために、あまりビジネス色を出さないようにしたいと考えています。 そこで、当分はコンテンツ化した書籍のアフィリエイトでマネタイズしていきますが、ゆくゆくは個人・法人スポンサーを募り、寄付形式で運用したいと考えております。そのためにはみなさまに継続してサイトを使っていただくとともに応援されるようなサイト運営をする必要があります。
今様々なところでデータ活用やAI導入が広がっている中で、データサイエンスの知識はデータ系職種の人だけでなく様々な業種で今後必要不可欠になると考えています。 その時、いろんな人が効率よく学ぶことができるプラットフォームが必要であると考え、このサイト作成に参画しております。 まずは認知を圧倒的に広め、データ分析の仕事を志す人からもう既にバリバリにデータ活用を推進している人まで幅広い層に使ってもらい、 役立ててもらいたいと考えております。 そして、ゆくゆくはデータに関わる人々に欠かせないツールになり、応援される存在にしていきたいので、コンテンツ作成だけでなく、マーケティング活動にも尽力していきます。

書き手:太田 雄(おおた・ゆう)氏
部品メーカーの生産技術開発職、半導体大手商社の技術営業職を経験。データ分析に興味を持ったことをきっかけに、2021年にデータサイエンティストにキャリアチェンジを果たす。現在は、製造業の顧客に対してデータ解析・可視化・予兆管理システム構築支援を実施。
Data Learning Bibliographyにコンテンツを充実させていくため、記事の執筆者を募集しています。執筆にささやかではありますが、謝礼として書籍の金額分のAmazonギフトカードを提供させて頂きます。データ関連の書籍であれば、どのような書籍でも大丈夫ですので、執筆にご興味がある方は代表の村上までご連絡ください。
メルマガ登録をしていただくと、記事やイベントなどの最新情報をお届けいたします。
学びをシェアする




30秒で理解!インフォグラフィックや動画で解説!フォローして『1日1記事』インプットしよう!

 データのじかんをもっと詳しく データのじかんフィーチャーズ
データのじかんをもっと詳しく データのじかんフィーチャーズ 

 データで越境するあなたへおすすめの 『ブックレビュー』
データで越境するあなたへおすすめの 『ブックレビュー』  BIツールユーザーによる、BIツールユーザーのための、BIツールのトリセツ
BIツールユーザーによる、BIツールユーザーのための、BIツールのトリセツ  CIOの履歴書 by 一般社団法人CIOシェアリング協議会
CIOの履歴書 by 一般社団法人CIOシェアリング協議会  なぜ、日本企業のIT化が進まないのか――日本のSI構造から考える
なぜ、日本企業のIT化が進まないのか――日本のSI構造から考える  日本ビジネスの血流である帳票のトレンドを徹底解説
日本ビジネスの血流である帳票のトレンドを徹底解説  データを武器にした課題解決家「柏木吉基」のあなたの組織がデータを活かせていないワケ
データを武器にした課題解決家「柏木吉基」のあなたの組織がデータを活かせていないワケ  BI(ビジネスインテリジェンス)のトリセツ
BI(ビジネスインテリジェンス)のトリセツ  入社1年目に知っておきたい 差が付くKPIマネジメント
入社1年目に知っておきたい 差が付くKPIマネジメント  CIOLounge矢島氏が紐解く トップランナーたちのDXの“ホンネ”
CIOLounge矢島氏が紐解く トップランナーたちのDXの“ホンネ”  データのじかん Resources 越境者のためのお役立ち資料集 AI実装の現在地点-トップITベンダーの捉え方
データのじかん Resources 越境者のためのお役立ち資料集 AI実装の現在地点-トップITベンダーの捉え方  データでビジネス、ライフを変える、 面白くするDATA LOVERS
データでビジネス、ライフを変える、 面白くするDATA LOVERS  データマネジメント・ラジオ by データ横丁 データのじかんNews
データマネジメント・ラジオ by データ横丁 データのじかんNews  データ・情報は生もの! 『DX Namamono information』 ちょびっとラビット耳よりラピッドニュース
データ・情報は生もの! 『DX Namamono information』 ちょびっとラビット耳よりラピッドニュース  AI事務員宮西さん(データ組織立ち上げ編) 藤谷先生と一緒に学ぶ、DXリーダーのための危機管理入門
AI事務員宮西さん(データ組織立ち上げ編) 藤谷先生と一緒に学ぶ、DXリーダーのための危機管理入門  生情報取材班AI時代に逆行?ヒトが体感した「生情報」のみをお届け!
生情報取材班AI時代に逆行?ヒトが体感した「生情報」のみをお届け!  データはともだち 〜怖くないよ!by UpdataTV Original
データはともだち 〜怖くないよ!by UpdataTV Original  データ飯店〜データに携わるモノたちの2.5thプレイス by UpdataTV〜
データ飯店〜データに携わるモノたちの2.5thプレイス by UpdataTV〜  インサイトーク〜データで世界を覗いてみたら〜by WingArc1st + IDEATECH
インサイトーク〜データで世界を覗いてみたら〜by WingArc1st + IDEATECH  データの壁を越え、文化で繋ぐ。データ界隈100人カイギ
データの壁を越え、文化で繋ぐ。データ界隈100人カイギ データ越境者に寄り添うメデイア「データのじかん」が提供する便利ツールです。
本ツールは、JavaScriptを用いてお客様のブラウザ上で処理を行います。サーバーとの通信は行われず、入力データはお客様のみの端末内で処理されます。















