


※図版:筆者作成
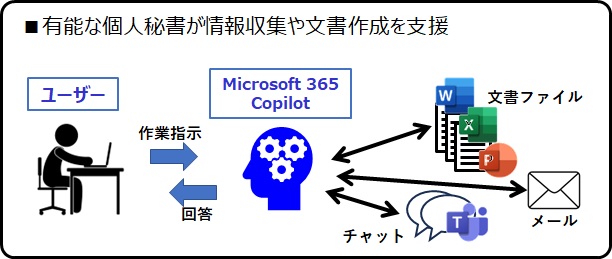
MS Copilotの機能
![]()
GoogleのDuetも同じような機能なので、そこは大差ないはずです。それより、ユーザー企業が生成AIをどのように導入するかによって、生成AIの機能や使い勝手に差が出てきます
※図版:筆者作成
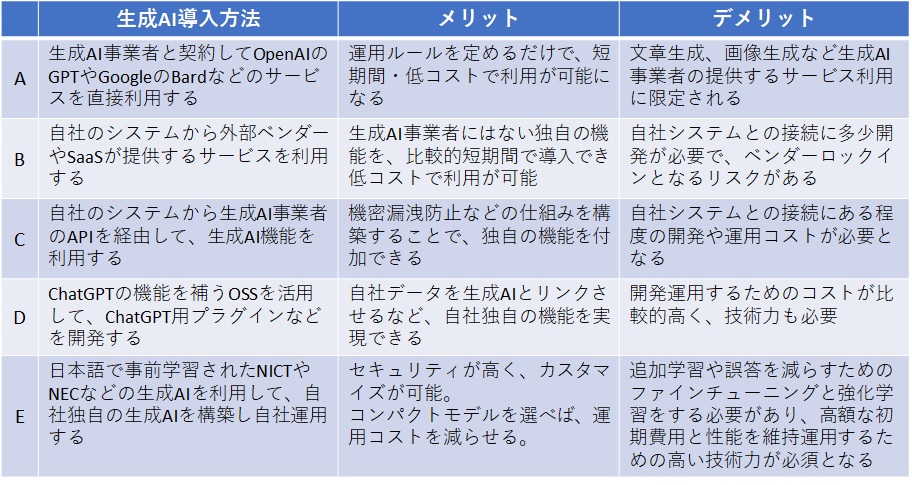
組織が生成AIを導入する方法
![]()
図を見てください。現時点でリリースされているCatGPTのような生成AIを、企業内で利用しようとする方法を分類して、メリット・デメリットを表にしたものです。
(A)は、OpenAIと契約してChatGPTなどのサービスを直接利用する方法です。生成AIの最初期ユーザーは、この方法しかないのでここから始めています。この方法は、文章生成やアイデア出しなどには有効ですが、今のところ利用方法は限られます。OpenAI がどんどん日本向けのサービスを増やしていけば、かなり有効なツールになるはずです。
これとは別に、2023年2月にGitHub Copilot for Businessの提供が開始されていので、大半のIT企業は実験的にCopilotの利用を始めています。実際にプログラミングの生産性が数倍から数十倍にまで向上したと報告が相次いでいるので、動きの鈍いIT企業がCopilotの本格導入が遅れると、あっという間に差がついていくでしょう
![]()
やはりAIを使えば、それほど労働生産性に差がつくのですね
![]()
ソフトウェアエンジニアなら、GitHubに慣れていますし、2022年から先行して個人開発者向けにCopilotを提供しています。1年近くパブリックコードをCopilotに学習させているので、ビジネス向けCopilotは最初からプログラムの生成精度が高く、実用性が高いのです。あとは利用するIT企業が、自社の開発工程にどのように組み込めるか、そのノウハウを獲得することが重要なのです。なので、様子見しているような企業は不利になると言っているのです。ただし、本家のGPT-4は2023年6月バージョンアップしたら、3月版より数学やプログラミングなどの性能が大幅に低下する(註1)ドリフト問題が発生したので注意してください
![]()
え!そんなことがあったのですか?どうしてそんな現象が起きたのですか?
![]()
原因は現時点で不明です。この話をすると、またかなり長くなるので別途します。とりあえずGitHub Copilotでは、この現象が起きてないようなので話を進めます。
(B)の外部ベンダー利用ですが、自社にAI専門家がいなくても生成AIの利用が可能なので比較的に導入は容易です。もちろんベンダーの力量に大きく依存するので、ベンダー選定が重要です。日本企業なら昔ながらの手法なので慣れているとは思いますが、ベンダー自ら生成AIを利用していないようなITベンダーは避けた方がよいでしょうね
![]()
いわゆるベンダー丸投げ手法ですね
![]()
(C)のAPI利用ですが、自社内にソフトウェアエンジニアがいる企業なら、この方法で既にテストをしていると思います。API利用は比較的簡単なので、実験しながら仕様を決めてアプリ開発ができます。しかし自社アプリが完成しても、継続的に運用するとなると、生成AI事業者の進化スピードに追従して、アプリの性能を維持していく必要があります。これはかなり負荷が重いと考えられるので注意が必要です
![]()
GPTの進化速度はとんでもないですからね
![]()
(D)は独自のプラグインを開発してサービスを提供する方法です。既にChatGPT用の様々なOSSが公開されているので、これらを利用することで自社のサービスをChromeなどのプラグインとして提供ができます。今まで説明した(A)(B)(C)は、生成AIを主に社内活用するための方法ですが、これは外部にAIサービス提供するための方法になります。食べログのプラグイン(註2)が有名ですね。 最後の(E)は。自社で生成AIを構築運用する方法です
![]()
そんなことが日本企業にできるのですか?
![]()
生成AIをゼロから独自開発するのではなく、既に多数の生成AIのオープンソースが公開されているので、それを利用すれば可能です
![]()
OpenAIやGoogle以外のIT企業が、生成AIを独自開発しているなら凄いことですね
![]()
OpenAIはGPT-2までのLLMのソースコードを公開していたので、大半のIT企業はこれをベースにLLMを開発してきたという経緯があります。実際にはここから膨大な量のテキストデータを学習させるコストが、数十億円以上は必要だとされています。しかしこれも、Metaが基本的な学習を済ませ商業利用可能なLLM「Llama 2」を、7月にオープンソースとして公開しているので、これを利用すれば必要な追加学習・ファインチューニングをすることで、独自のLLMを構築できます
※図版:筆者作成
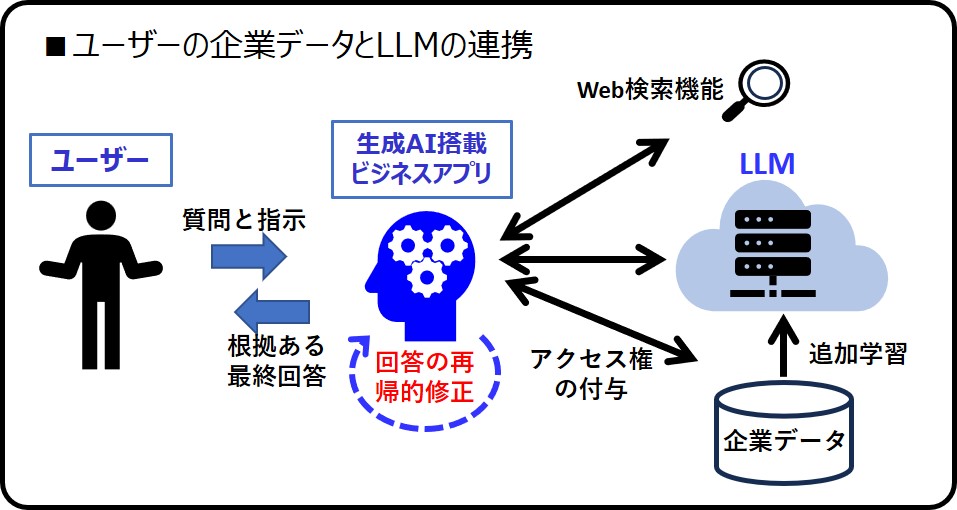
ユーザーの企業データとLLMの連携
![]()
アメリカ企業製のLLMばかりですが、日本語も使えるのですか?
![]()
ある言語を使えるとは、例えば英文を読めても英語で会話できない、のように、その目的によって評価が変わります。自然言語処理(NLP)には、自然言語理解(NLU)と自然言語生成(NLG)がありますが、ここはあまり厳密に話しても長くなるのでやめましょう。日本語言語理解ベンチマーク(JGLUE)があるので、これを利用すれば言語理解度の比較ができます。日本の情報通信研究機構(NICT)が公開したLLMの日本語特化モデルで、日本語推論能力は84.3%、NECが最近発表したモデルも同等です。ちなみにですが、早稲田大学のRoBERTa largeモデルで89.1%ですが、このモデルは以前の言語モデルであるBERTに、大規模な日本語テキストでファインチューニングをしているようです
![]()
いや、質問はChatGPTやGoogleのBardなどのアメリカ製LLMの日本語能力ですよ
![]()
まだ資料を見つけていないのでBardに質問したところ、”JGLUEの推論テストJCommonsenseQAのスコアは、88.7です”と回答しました。MSのBingへ同じ質問をすると。”私はBingのアシスタントであり、JGLUEのスコアを持っていません”という冷たい回答でした。そこでBardに尋ねてみると、“Bingは非公開です。ChatGPTのJGLUEのJCommonsenseQAのスコアは、84.8です。これは、私が88.7というスコアを獲得したよりも低いスコアです”と自慢していました
![]()
なんだ、日本語特化モデルよりChatGPTやBardの方が、日本語性能もやはり上なのですね
![]()
このデータは、日本語理解力の指標の一つでしかありませんし、生成AIは、数か月で性能がどんどんアップしていきます
![]()
しかし、いつのまにか話が脇道に逸れていますが、何の話でしたか?
![]()
企業が日本語LLMを自社内に導入運用する方法、という話でしたね。小さなモデルなら個人でも実際に稼働させた人もいるので、優秀なエンジニアが社内にいれば可能です。前述した日本のNICTやNECのLLMモデルなら、構築・稼働させ社内でテスト運用するまでは比較的容易なはずです。ただし、実用性のある社外向けサービスを提供するには、コストも技術力も必要なので、簡単ではないでしょう
![]()
どういうことですか?
![]()
社内向けのサービスに自社のLLMを利用するなら、多少の差別発言や間違いがあってもそれほど大問題にはなりません。しかし社外向けのサービスに利用するとなると、重大なクレームになります。ここは利用するLLMのモデルがあらかじめどこまで対策を施しているかにもよりますが、LLMの本質的課題である差別発言や誤答問題の対策には、かなりのコストやノウハウが必要だからです
![]()
前回の話では、今回はプロンプトエンジニアリングの話もするということでしたが、まだですか?
![]()
そうでしたね。予想外に生成AIの導入だけでかなり長くなってしまったので、そこは次回に致します
【第4回へ続く】
図版・著者:谷田部卓
AIセミナー講師、著述業、CGイラストレーターなど、主な著書に、MdN社「アフターコロナのITソリューション」「これからのAIビジネス」、日経メディカル「医療AI概論」他、美術展の入賞実績もある。
(TEXT:谷田部卓 編集:藤冨啓之)
メルマガ登録をしていただくと、記事やイベントなどの最新情報をお届けいたします。
ChatGPTとAPI連携したぼくたちが
機械的に答えます!
何か面白いことを言うかもしれないので、なんでもお気軽に質問してみてください。
ただし、何を聞いてもらってもいいですけど、責任は取れませんので、自己責任でお願いします。
無料ですよー
学びをシェアする



30秒で理解!インフォグラフィックや動画で解説!フォローして『1日1記事』インプットしよう!























データ越境者に寄り添うメデイア「データのじかん」が提供する便利ツールです。
本ツールは、JavaScriptを用いてお客様のブラウザ上で処理を行います。サーバーとの通信は行われず、入力データはお客様のみの端末内で処理されます。



































前回はChatGPTなどの生成AIが、オフィス業務を具体的にどのように変えてしまうかについて話しました。そして生成AIは、あくまで優秀な個人秘書として扱うことで、そのユーザーの労働生産性を大幅にアップさせることができるとも説明しています
そうでしたね。でもそれは、Microsoft Copilotのユーザーに限りますね