
目次
「データレイクってなんだろう?」
「データレイクをわかりやすく解説して欲しい!」
データ活用を考えている方であれば、一度はこのように考えたことがあるのではないでしょうか。
データレイクは、2010年に米Pentaho社のCTOジェームズ・ディクソン氏によって発表されたデータリポジトリ(保管庫)であり、近年注目を集めています。
今後、生成AIやビッグデータなどの活用があたり前となることが予想されるなかで、データレイクの重要性も高まっていくでしょう。
しかし、データレイクの特徴や役割がいまいち把握できず困っている方も増えているはず。
本記事ではデータレイクの概要を、データベースやデータウェアハウスとの違いに触れながらわかりやすく解説していきます。
具体的な活用例も紹介しますので、ぜひ参考にしてみてください。

データレイクとは「あらゆるデータをそのままの形で保存しておくデータの格納庫」です。
データを素材のまま蓄積できるといった特徴があり、さまざまなデータを取り扱う機関でもすべてのデータを一元管理できるメリットがあります。
データレイクの概要について以下のポイントに絞りながらもう少し詳しく解説していきます。
それぞれ詳しくみていきましょう。
データレイクの必要性として、大きく以下の2つが挙げられます。
データ研究の第一線であるドイツのStatista GmbHによれば、世界で生成、取得、複製、消費されるデータは2025年時点で180ゼタバイト以上になると予想されています。(1ゼタバイト(ZB)は10^21バイト=10億テラバイト(TB)=1兆ギガバイト(GB))
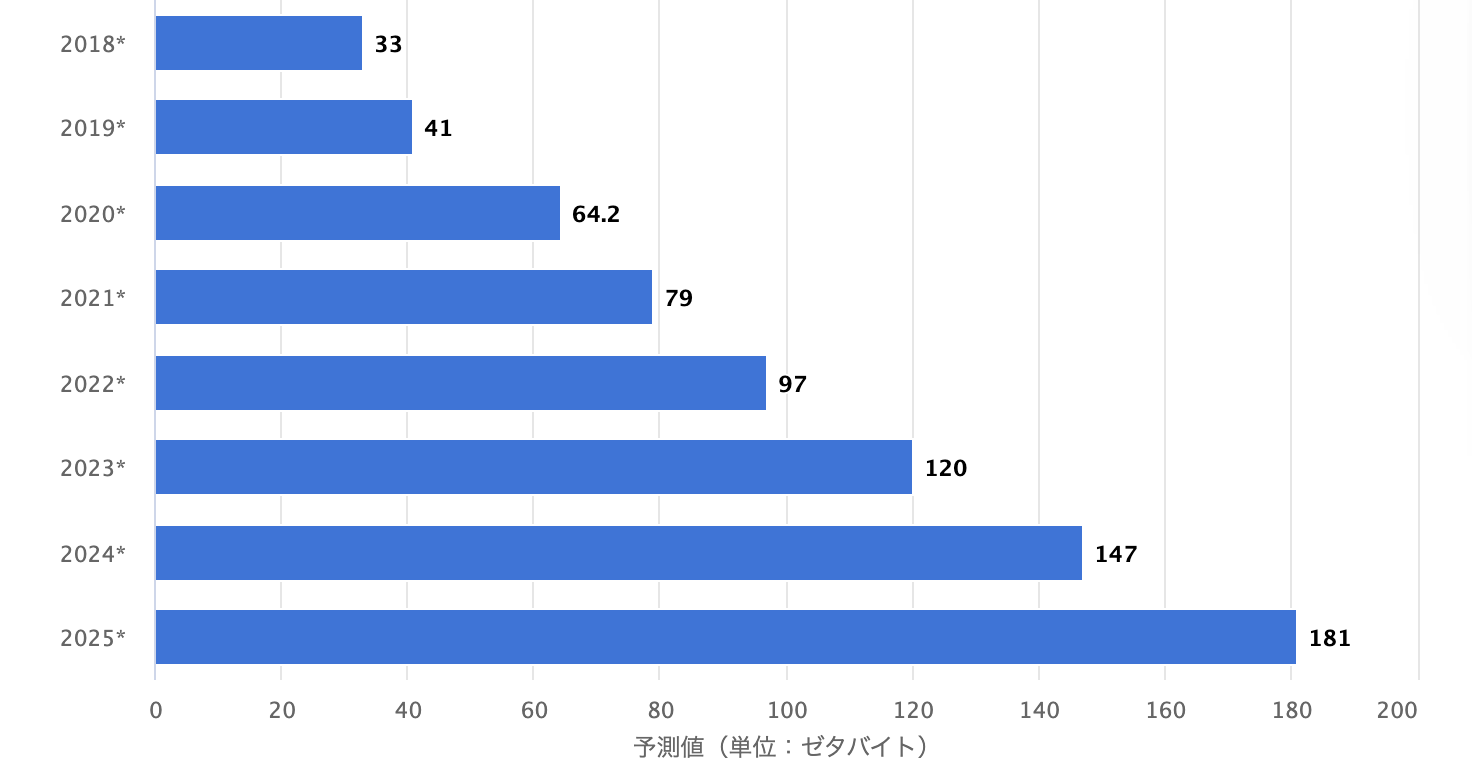
出典:2010年~2020年 世界で生成、取得、複製、消費されるデータ/情報の量および2021年~2025年までの予測値(単位:ゼタバイト)
コロナウイルスの拡大によりリモートワークを導入する機会が増えたことで、データの生成や消費量が急激に増加し、これにともなうデータの保存や保存場所からの抽出という工程も増え続けていきます。
データレイクはあらゆるデータをそのまま保存できるため、データが増え続ける時代に需要が高まっていくでしょう。
また、ビッグデータの活用には膨大なデータの収集が欠かせません。
データ格納庫からAIを利用して瞬時に必要なデータを抽出する工程においても、素材のままのデータを保存できるデータレイクは重要な役割を担うでしょう。
データレイクは以下のような構造化データ・非構造化データに関わらず、あらゆるデータを素材のまま格納できます。
構造化データと非構造化データの違いは以下のとおりです。
|
構造化データ |
非構造化データ |
|
|
データの構造 |
列や行を持つデータ |
構造化されていないデータ |
|
データの種類 |
エクセル、スプレッドシート、ソースコードなど |
メールやチャットなどのテキスト、画像、pdf、音声、動画、センサーログなど |
|
データの性質 |
定量的 |
定性的 |
|
データ分析 |
しやすい |
専門知識が必要 |
|
データ量 |
少ない |
多い |
|
検索性 |
高い |
低い |
|
保存場所 |
主にデータウェアハウス |
主にデーやレイク |
構造化データは構造が明確に定義されている一方で、非構造化データは定義がされていません。
そのため、構造化データは利用用途が明確な場合は活用しやすく、非構造化データは活用時にデータの変換や加工などが必要です。
構造化データと非構造化データについては、以下の記事でも解説していますので参考にしてみてください。
データレイクの構築手順は以下のとおりです。
|
STEP1:保管場所のセッティング |
収集するデータを保存するデータレクを事前にセッティングする。代表的なものとしてHadoopやAWS、Azureなどが挙げられる。 |
|
STEP2:データ収集 |
設定したデータレイクへデータを格納雨していく。手動でデータを保存するのは時間がかかるため、データソースと連携して自動でデータが格納される仕組みを利用する。 |
|
STEP3:データの変換・加工 |
データの利用用途に合わせて、データを加工・変換する。また、データの種類に合わせて整理するデータのカタログ化も利用する。 |
|
STEP4:データ分析 |
利用用途に合わせて、機械学習やソースコードを用いてデータの分析を行う。 |
データレイクはあらゆるデータを格納できるため、データが混在しやすいです。
そのため、構築の際にはどのようなデータを保存するか事前に整理し、データのカタログ化を利用したり利用しやすい形式へデータを変換したうえで格納するとよいでしょう。
なお、AWSではデータのカタログ化にAWS Glueを利用できます。
データレイクの種類には以下の4つが挙げられます。
順に紹介しますので、参考にしてください。
従来型のアプローチで、企業が自身のデータセンター内にデータレイクを構築する方法です。
企業はフルコントロールを持つことができますが、スケーリングと維持にはコストと専門知識が必要です。
AWS、Google Cloud、Azureなどのクラウドサービスプロバイダーを利用してデータレイクを構築するアプローチです。
スケーラビリティ、コスト効率性、そしてマネージドサービスによる運用の容易さが主な利点です。
一部のデータをオンプレミスに保持し、一部をクラウドに保存する方法です。これにより、セキュリティ、コンプライアンス、パフォーマンスの要件に基づいてデータの配置を最適化することができます。
複数のクラウドサービスプロバイダー間でデータを分散して管理するデータレイクの構築方法です。
特定のクラウドプロバイダーへの依存を回避し、各プロバイダーの特定のサービスを利用するために選択されます。

データレイクを理解するうえでは、データウェアハウスやデータマートとの違いを知る必要もあります。
ここからは以下の順でそれぞれの違いを解説していきます。
それぞれ詳しくみていきましょう。
データレイクとデータベースの違いは、“構造化が含まれるかどうか”です。
データレイクはあらゆるソースからデータを格納することができ、データを取り出す際には構造化が行われます。、
一方でデータベースは、スキーマ(構造、仕組み)が必要であり、半構造化データや非構造化データを格納できません。
データベースはデータを使いやすい形に階層化されているため、検索やレポートに向いているといえます。
データレイクとデータウェアハウスは“データを事前に整理するか否か”で分けられます。
データレイクは先に述べた通り、生データ(ローデータ)をそのまま格納することができます。
一方、データウェアハウスは行と列で定義されたリレーショナルデータを分析することに最適化されており、格納前にデータのスキーマ(構造、仕組み)が定義されます(スキーマオンライト)。
構造化のコストがかからないため、データレイクはデータウェアハウスよりも安価に大容量なデータを格納できますが、データを適切に取り出し加工するためには専門の知識が必要です。
その点データウェアハウスは、誰でもチャートやスプレッドシートでデータを用意し分析・加工が可能です。
魚が自由に泳ぐ湖(レイク)と釣り上げられ整理して格納される倉庫(ウェアハウス)の関係をイメージするとわかりやすいでしょう。
データレイクとデータマートの違いは、“データを用途に応じて抽出・保管しているか否か”です。
データマートとは、データの利用部門や用途・目的に応じて必要なものを抽出して、利用しやすいように加工した上で格納する場所を指します。
あらゆるデータを素材のまま保管するデータレイク(データの湖)とは、情報の質が異なります。
前述したイメージで例えると、魚が自由に泳ぐ湖が「データレイク」、釣り上げられ整理して格納される倉庫を「データウェアハウス」、倉庫内の魚をさらに観賞用や食用に整理し格納したものを「データマート」です。
データレイク・データウェアハウスとデータマートの違いは以下の記事でも解説しているので、ぜひ参考にしてみてください。

ここまではデータレイクの概要をその他のデータ保管方法などと比較して解説してきました。
ここからは、データレイクのメリットを以下の6つにまとめて紹介します。
データを素材のまま保管する「データの油田」ともいえるデータレイクを正しく効果的に活用するためにも、データレイクがもたらすメリットを理解していきましょう。
1つ目のメリットは、データの一元化ができる点です。データレイクは、構造化されているか否かに関わらず、異なるソースからのデータを一元的に保管することが可能です。
これにより、データを必要とする部門や組織が必要な情報にすばやくアクセスできるようになります。また、大容量の保管ができるため収集するデータが増加しても複数のデータ格納庫を往復する手間も省けるでしょう。
2つ目のメリットは、データ連携が疎結合(そけつごう)である点です。疎結合とは密結合の反対の言葉で、データ同士が干渉しあわず独立して保管されているという意味です。
データレイクはデータを特定の形式(スキーマ)に合わせる必要がなく、さまざまな形式でデータを保存できるため、データの抽出時や加工時に他のデータへ影響を及ぼす心配がありません。
3つ目のメリットは、スケーラビリティが高さです。
データレイクは、データ量が増えてもその性能を保つことができる大規模なストレージシステムです。
そのため、データの増加にともなって、迅速なリソースのスケールアップまたはスケールダウン(ストレージ容量の増減)、データの種類や量に応じた最適なストレージソリューションの選択、並列処理、分散ストレージといったデータを効率的に処理することが可能です。
4つ目のメリットは、データの分析や応用に使いやすい点です。
データレイクはさまざまなデータを1つの格納庫に保存しているため、複数のデータ格納庫を往来する必要がなく、必要な形式のデータや欲しい情報だけを抽出できます。
そのため、ビジネスの意思決定の場面で複数のデータ保管庫を往来する手間が省けます。
5つ目のメリットは、機械学習やデータマイニングとの相性のよさです。
データレイクは膨大かつさまざまなデータを格納できるため、情報量が多いほど精度が高くなる傾向にある機械学習やデータマイニングの有効活用ができます。
また、膨大なデータを読み込ませた機械学習をビジネスへ活用することで、新しいビジネスチャンスの創出にも役立てられるでしょう。
6つ目のメリットは、コストをコントロールしやすい点です。
データレイクは、従来のデータウェアハウスと比較してコスト効率がよいとされています。
特にHadoopやAWSなどの、クラウドベースのデータレイクは必要に応じてストレージや計算能力をスケールアップ・ダウンできるため、必要なリソースに応じてコストを節約できます。

データレイクの導入や運用はメリットだけでなく、課題や問題点といったデメリットも存在します。
ここからは、データレイクのデメリットや注意点を6つにまとめて解説します。
それぞれ詳しくみていきましょう。
1つ目のデメリットは、データに統一性がない点です。
データレイクの多種多様なデータが集められるといった特徴は、、品質や形式が統一されていないというデメリットにもなり得ます。
データが不完全であったり、不正確であったりすると、分析結果に影響を及ぼすため、データ利用時に大きな障害となる可能性があります。
2つ目のデメリットは、データへの不正アクセスのリスクです。
データレイクには企業の重要な情報が含まれるため、データのセキュリティとプライバシーが重要になります。
ビジネスの重要な意思決定の判断材料となる情報を保存する場合は気をつけなければなりません。
不適切なアクセスやデータ漏洩を防ぐための適切なセキュリティ対策が必要不可欠です。
3つ目のデメリットは、データの維持・管理とガバナンスが必要になる点です。
データレイクが大きくなると、データの管理やガバナンス(統制)が難しくなります。
どのようなデータが、どこの保管され、何に使用されるかを理解するためには、メタデータの管理やデータのライフサイクル管理などが必要です。
4つ目のデメリットは、人材やスキルが足りない点です。
データレイクの設計、実装、運用は高度な専門知識や特別な技術が必要であり、精通した人材が必要不可欠です。
しかし、データサイエンティストやデータエンジニアなどの専門家は限られているため、データレイクを活用したくても、人材やスキルの不足が課題となりやすいです。
5つ目のデメリットは、パフォーマンスが不安定になりやすい点です。
大量のデータを効率的に抽出・分析するためには、データレイクそのものの高度なパフォーマンスも求められます。
しかし、データレイクの規模が大きくなると、データの精度が低くなる場合があり、パフォーマンスへ影響を及ぼす恐れがあります。
6つ目のデメリットは、「データの沼」となる恐れがある点です。
適切なデータ管理やガバナンスがなされていないデータレイクは、「データ湖(データの品質が悪く、有用な情報を取り出すのが難しい状態)」に陥る可能性があります。
この状態では、データレイクはただのデータの蓄積場所となり、データレイク本来の価値を発揮しません。
なお、「データの沼」については「データの沼」に陥らない方法とは?データカタログを活用するメリット3つで詳しく解説しています。

ここからは、以下の業界別にデータレイクの活用方法をご紹介していきます。
それぞれ詳しくみていきましょう。
ヘルスケア業界では、病院やクリニック、研究施設が生成する膨大な量のデータをデータレイクへ格納して活用できます。
例えば、患者の治療履歴、臨床試験のデータ、遺伝子情報などを組み合わせて、よりパーソナライズされた治療法を開発したり、新薬の発見のきっかけとなる可能性があります。
小売業者は、売上データ、在庫データ、顧客データ、Webサイトのクリックストリームデータなどをデータレイクに集め、顧客行動の分析や、在庫管理の最適化といった、マーケティングが実践可能になります。
機械学習や生成AIもあわせて活用することで、工数削減やコスト削減も実現できるでしょう。
銀行や保険会社などの金融業では、トランザクションデータ、顧客データ、リスクデータ、マーケットデータなどをデータレイクに格納し、不正行為の検出、リスク管理の強化、顧客エンゲージメントの向上などに活用できます。
ただし、重要な情報を格納する場合はセキュリティ対策が必要となるため、信頼できるデータレイク専門家の任命が欠かせません。
製造業では、機械や装置から収集されるIoTデータをデータレイクに保存し、生産ラインの効率性を向上させる方法を得たり、製品の品質を向上、予防保守などを可能にします。
エネルギー企業では、地質学・天候などのデータをデータレイクへ格納し、エネルギー生産の最適化、供給網の管理、リスクの識別と緩和などに活用できます。
大企業では取り扱うデータと関わる人材が膨大となるため、アクセスしやすく一元管理が可能なデータレイクは相性がよいといえるでしょう。
教育業界では、生徒の個性や成績、行動履歴などをデータレイクへ格納し、おおよその成長曲線や得意または苦手分野の発見、教師の意思決定などへ活用できます。
近年では生徒へタブレット端末を配布し、学習記録をすべてデータ化することでデータを収集し、データ活用を推進する施策が進められています。
物流業界では、トラックの配送ルートや配送スケジュール、受注管理、顧客情報などあらゆる情報をデータレイクへ格納し活用できます。
人材不足が懸念される物流業界では配送・管理のコストを削減し、ロボットやドローンの活用も早急に求められているため、データレイクの有効活用も早期に導入が検討されています。

データレイクのデメリット・注意点のなかでも最も気をつけたいのは「データの沼(データスワンプ)」です。
データが無作為に放り込まれ、もはやどこにどのようなデータがあるのか、どう活用すればいいのかが分からないブラックボックス化した状態のデータレイクは意味をなしません。
データレイクのスワンプ化を防ぐためには「データカタログ」の活用が必要です。
データカタログはいわば「データの管理台帳」であり、分類番号や所有者などデータを特徴づけるメタデータを収集・蓄積し、データのアクセス性と品質を担保してくれます。
データカタログの例として挙げられるのが日本政府が公開するオープンデータをカタログ化した「DATA.GO.JP」です。

「組織」「グループ」「タグ」など、利用者に合わせた検索性をそなえたデータカタログと適切なメタデータを収集・追加・改定・削除できる仕組みを構築することで、データレイクを澄んだ湖として保つことができます。
また、企業内のデータをデータカタログとして、ツールで利用するには、データウェアハウスとデータレイクを論理的に統合する「データ仮想化」といった技術の導入も必要です。

データレイクとデータウェアハウスの違いでも述べたとおり、データウェアハウスは事前にデータを整理した上で格納します。
例えば、代表的なツールである『Denodo Platform』を導入すると次のようなメリットを受けられます。
従来の各システムに対するデータ抽出・統合作業が不要となり、クイックにデータにアクセスできるため、高度な専門知識がなくてもビジネスに応用しやすくなります。
データの形式、場所に関係なく、すべてのエンタープライズシステムにまたがるデータを仮想で統合します。
管理がしやすいように仮想で統合されているため、データ自体には影響を及ぼしません。
利用可能なすべての仮想テーブルをカタログ化するため、検索・検出、管理するための一元化された安全なレイヤを提供します。
データレイクはAWSの「Amazon S3」を利用することで構築できます。
容量に合わせてストレージのスケールアップやスケールダウンが可能であり、また強固なセキュリティ対策によってデータを不正なアクセスから守ってくれます。

データレイクは、ビッグデータ時代に活躍が期待される拡張性・汎用性の高いデータ保管庫です。
さまざまなビジネスへの応用が期待され、AIや機械学習などの先端技術とあわせて有効活用すれば小さなコストで大きな利益を生み出すツールにもなりえます。
しかし、有効活用するには高度な専門知識が必要なため、導入を検討している場合は専門家へ依頼してみることをおすすめします。
(宮田文机)
・データ・レイクとは何か? ガートナーが解説する企業導入・活用のポイント┃ビジネス+IT
・清水 響子「「データレイク」はデータウェアハウスとどこが違うの?」┃IT Leaders
・谷川 耕一「第3回DBオフライン開催します。お題は「データレイクって必要ですか?」」┃EnterPrizeZine
・“ビッグデータの湖”データレイクとは何だ? EMCが答える┃ASCII.jp×TECH
・DATAFLUCT「データサイエンティストのためのデータカタログ」┃note
・データレイクとは┃AWS
・データカタログ構築を成功に導く! 失敗する4つのアンチパターンとその回避策とは┃IT Leaders
・Narimichi Nakatani「最適なデータカタログを構築するには?」┃InformaticaBlog
メルマガ登録をしていただくと、記事やイベントなどの最新情報をお届けいたします。
学びをシェアする




30秒で理解!インフォグラフィックや動画で解説!フォローして『1日1記事』インプットしよう!

 データのじかんをもっと詳しく データのじかんフィーチャーズ
データのじかんをもっと詳しく データのじかんフィーチャーズ 

 データで越境するあなたへおすすめの 『ブックレビュー』
データで越境するあなたへおすすめの 『ブックレビュー』  BIツールユーザーによる、BIツールユーザーのための、BIツールのトリセツ
BIツールユーザーによる、BIツールユーザーのための、BIツールのトリセツ  CIOの履歴書 by 一般社団法人CIOシェアリング協議会
CIOの履歴書 by 一般社団法人CIOシェアリング協議会  なぜ、日本企業のIT化が進まないのか――日本のSI構造から考える
なぜ、日本企業のIT化が進まないのか――日本のSI構造から考える  日本ビジネスの血流である帳票のトレンドを徹底解説
日本ビジネスの血流である帳票のトレンドを徹底解説  データを武器にした課題解決家「柏木吉基」のあなたの組織がデータを活かせていないワケ
データを武器にした課題解決家「柏木吉基」のあなたの組織がデータを活かせていないワケ  BI(ビジネスインテリジェンス)のトリセツ
BI(ビジネスインテリジェンス)のトリセツ  入社1年目に知っておきたい 差が付くKPIマネジメント
入社1年目に知っておきたい 差が付くKPIマネジメント  CIOLounge矢島氏が紐解く トップランナーたちのDXの“ホンネ”
CIOLounge矢島氏が紐解く トップランナーたちのDXの“ホンネ”  データのじかん Resources 越境者のためのお役立ち資料集 AI実装の現在地点-トップITベンダーの捉え方
データのじかん Resources 越境者のためのお役立ち資料集 AI実装の現在地点-トップITベンダーの捉え方  データでビジネス、ライフを変える、 面白くするDATA LOVERS
データでビジネス、ライフを変える、 面白くするDATA LOVERS  データマネジメント・ラジオ by データ横丁 データのじかんNews
データマネジメント・ラジオ by データ横丁 データのじかんNews  データ・情報は生もの! 『DX Namamono information』 ちょびっとラビット耳よりラピッドニュース
データ・情報は生もの! 『DX Namamono information』 ちょびっとラビット耳よりラピッドニュース  AI事務員宮西さん(データ組織立ち上げ編) 藤谷先生と一緒に学ぶ、DXリーダーのための危機管理入門
AI事務員宮西さん(データ組織立ち上げ編) 藤谷先生と一緒に学ぶ、DXリーダーのための危機管理入門  生情報取材班AI時代に逆行?ヒトが体感した「生情報」のみをお届け!
生情報取材班AI時代に逆行?ヒトが体感した「生情報」のみをお届け!  データはともだち 〜怖くないよ!by UpdataTV Original
データはともだち 〜怖くないよ!by UpdataTV Original  データ飯店〜データに携わるモノたちの2.5thプレイス by UpdataTV〜
データ飯店〜データに携わるモノたちの2.5thプレイス by UpdataTV〜  インサイトーク〜データで世界を覗いてみたら〜by WingArc1st + IDEATECH
インサイトーク〜データで世界を覗いてみたら〜by WingArc1st + IDEATECH  データの壁を越え、文化で繋ぐ。データ界隈100人カイギ
データの壁を越え、文化で繋ぐ。データ界隈100人カイギ データ越境者に寄り添うメデイア「データのじかん」が提供する便利ツールです。
本ツールは、JavaScriptを用いてお客様のブラウザ上で処理を行います。サーバーとの通信は行われず、入力データはお客様のみの端末内で処理されます。















