



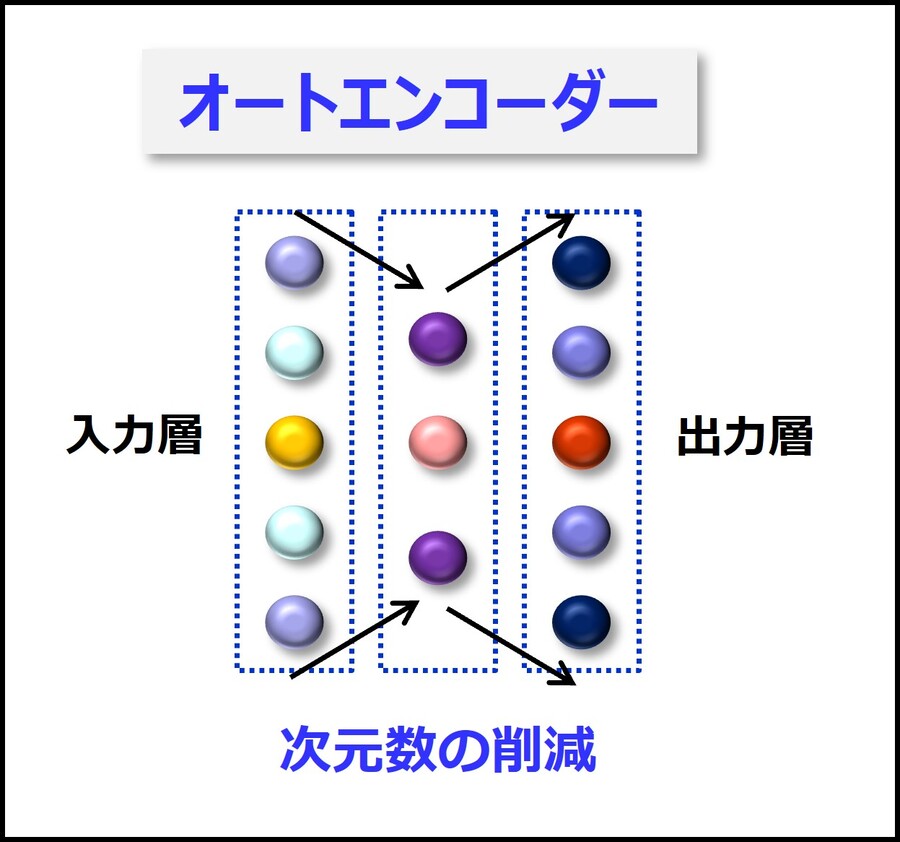
※図版:筆者作成「オートエンコーダーの仕組み」
![]()
これならAI入門講座の最初の方で登場しますね
![]()
そうです。これは入力データと同じデータを出力するネットワークですが、データの次元数を削減することができます。次元数の削減とは、ファイルや画像の圧縮のようなものです。
ディープラーニング入門の解説書に詳しく書いてありますが、次元数を削減することで、その画像の特徴量を抽出することができます。つまりネコの画像をネットワークに大量に読み込ませることで、ネコの特徴をネットワークに学習させ、イヌと識別することができるようになるのです
![]()
そうでした。次元圧縮と特徴抽出は、ディープラーニングの基本でしたね。それでなぜ画像生成ができるのですか?
![]()
特徴量を抽出できたということは、いわば抽象的概念を理解できたようなものです。ということは、詳細なデータがなくても再現可能だという事です
![]()
う~ん、つまりネコを見ないでネコの絵を描けるようなものか。ボクでもできるな
![]()
そのとおり。拡散モデルは、元画像を完全にノイズ化して、そこから元画像に戻せるようになるまでひたすらネットワークを訓練するのです
![]()
すごいな。スパルタ教育だ

※図版:筆者作成「拡散モデルの学習過程」
![]()
この訓練が終わると、このネットワークはノイズから元画像が生成できるようになります
![]()
でもこれだと学習した画像だけしか生成できませんよ
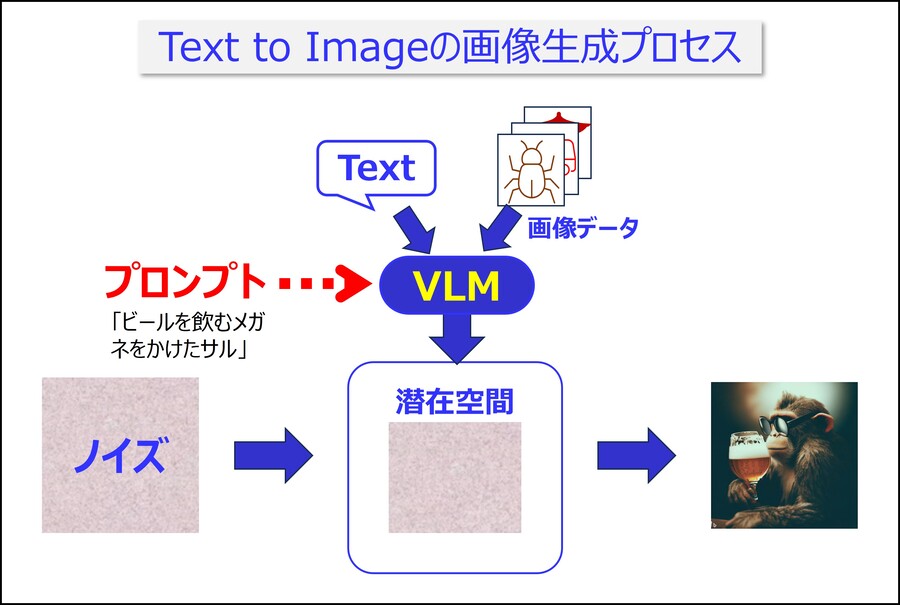
※図版:筆者作成「画像生成プロセス」
![]()
まだ先があります。Text to Imageの生成AIは、プロンプトで指示すると、その指示通りの画像を生成できます。これはVLM(Visual Language Model)と呼ばれる、画像とその画像を説明するテキストをセットで学習したマルチモーダルな学習モデルを利用しているからです。
このVLMは、画像と対応するテキストの関係性を学習して、テキストに付与されている画像の概念のような情報を扱えるようになります。その情報を拡散モデルのノイズデータに追加することで、そのノイズデータは画像の概念情報を持つノイズとなります。このような情報を扱う場所を潜在空間と呼びます
![]()
まぁ今の説明だと、分かったような漠然としたイメージでしかボクは理解できてませんが、ちょうどそれと同じように画像の概念をAIが持てたということかな
![]()
そんなところですね。この潜在空間にある情報を基にして、VLMはプロンプトで指示された情報を組み合わせ、拡散モデルが画像を生成しているのです
![]()
つまり、画像の概念を理解しているVLMと画像を生成できる拡散モデルを組み合わせたということか
![]()
その通りです。”ビールを飲むサルの絵の描き方”のイメージ図を参考にしてください
![]()
なかなか上手い絵ですね。で、前置きが長いのですが、肝心の動画生成の解説はまだですか?
![]()
動画生成AIの仕組みを理解するためには、まず画像生成の原理である拡散モデルを理解する必要があるので、今まで説明してきました。Soraの技術のポイントは、Transformerアーキテクチャを用いた拡散モデルです。つまり、Soraは生成した画像に大量のノイズを加え、次にノイズを除去していくという大規模な訓練をすることで学習していきます
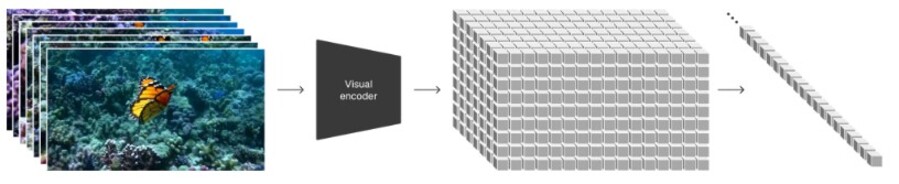
出典:Video generation models as world simulators
![]()
すなわち、初めに動画データを”低次元の潜在空間”に圧縮して、データ量を大幅に削減します。次に圧縮した低次元の潜在空間をさらに”時空潜在パッチ”へ分解することでパッチ化します。次に”Transformerアーキテクチャを用いた拡散モデル”で処理します
![]()
ちょっと待った!さりげなく説明を飛ばさないでください。時空潜在パッチへ分解する、の意味が分かりません
![]()
そうですか。時空間パッチに分解するとは、動画を扱いやすくするために、その動画を時間と空間の両方で小さな部分(パッチ)に分割する方法のことです。
サルくんでも知っているように、動画は連続する静止画(フレーム)の集まりですね。例えば、時間軸なら30フレーム/秒を1秒単位で分割し、空間軸ではフレームサイズ1920×1080ピクセルを64×64ピクセルに分割します。
こうすることで、計算量を大幅に減らして全体の処理効率を向上させています
![]()
なるほど。ディープラーニングの画像認識方法を、時間軸にも拡張したのか
![]()
次ですが、パッチ化されたデータに画像生成の拡散モデルと同様に、ノイズを加え除去するプロセスで、ノイズから動画を生成するための大量のトレーニングを行います
![]()
それだと、そのトレーニング用の動画はどうやって準備するんですか?YouTubeのようなネット上にある動画だと、その動画がどんな動画なのか具体的に説明がないから、動画生成のお勉強には使えませんよ。そもそも著作権の問題もあるし
![]()
鋭い指摘ですね。大規模なAIを開発する際に、常に大きな問題となるのがトレーニングデータです。特にこのText-To-Video生成システムのトレーニングでは、テキスト・キャプションつまり動画を説明する文章を持つ、大量の動画が必要になります。
この問題に対して、Open AIは素晴らしいアイデアで解決しています。それは、Open AI のDALL-E3で導入されたキャプショニング技術を利用したのです
![]()
キャプショニングって用語、どこかで習いましたか?
![]()
キャプショニングとは、画像やビデオの内容に対して適切な説明文を生成するプロセスのことです。DALL-E3のキャプショニング技術は性能が高く、対象となる画像の具体的な説明を生成できます。そこでトレーニング用の動画に応用し、テキスト・キャプションを生成させたのです
![]()
なるほど。動画生成をさせるために、トレーニング用の動画を自ら用意したのか。ということは、動画生成の品質はキャプショニングの生成品質に依存してしまいますね。
でもまぁ、Soraが生成した動画の品質はそれほど問題ないから発表したんだろうな。でも、大量に用意しなければならないトレーニング用動画そのものは、どうやって入手したんですか?
![]()
100万時間以上のYouTube動画でトレーニングしたという噂はありますが、動画の入手先に関しては公表していないので不明です
![]()
それは怪しい。現実問題として、大量にある公開された動画はYouTube動画しかないから、当然利用しているだろうな
![]()
とにかくライセンス問題が解決するまでは公表しないでしょうね。興味があるならWSJのOpenAI最高技術責任者(CTO)へのインタビューを確認してください。以上で、Soraの動画生成技術についての概念の説明になります
![]()
まるで魔法のような動画生成技術が、とりあえず魔法でないことは分かった気もします。それにしても動画全体にノイズをかけて、もう一度そのノイズを取り去ることで動画が生成できる、なんてやっぱり不思議だな。そういえば、冒頭での質問、なぜSoraのタイトルにワールドシミュレータという言葉があるのか、という説明がまだですが
![]()
今回も講義が長くなったので、次回にしましょう
・画像生成AIは、画像の次元数を削減して特徴量を抽出し、その画像を説明するテキストもセットで学習することで画像の概念を把握して、テキストの指示により元画像を再生している。
・soraは、動画データを時空間パッチに分解してデータ圧縮し、各パッチにノイズを加えてノイズ化し、そこからノイズを取り除く訓練を大量にすることで、動画生成をしている。
終わり
著者:谷田部卓
AIセミナー講師、著述業、CGイラストレーターなど、主な著書に、MdN社「アフターコロナのITソリューション」「これからのAIビジネス」、日経メディカル「医療AI概論」他、美術展の入賞実績もある。
(TEXT:谷田部卓 編集:藤冨啓之)
メルマガ登録をしていただくと、記事やイベントなどの最新情報をお届けいたします。
学びをシェアする



30秒で理解!インフォグラフィックや動画で解説!フォローして『1日1記事』インプットしよう!























データ越境者に寄り添うメデイア「データのじかん」が提供する便利ツールです。
本ツールは、JavaScriptを用いてお客様のブラウザ上で処理を行います。サーバーとの通信は行われず、入力データはお客様のみの端末内で処理されます。







































今回は、Text-To-Videoモデルである動画生成AI・Soraの仕組みについて説明します。なおここでの情報は、OpenAI が2024年2月に公開した”Video generation models as world simulators”をベースとしています
動画生成AIの技術レポートなのに、なんでタイトルにワールドシミュレータなんて大げさな言葉があるのですか?
初めは私も同じ疑問があったのですが、このレポートを最後まで読み込めば分かります。つまり仕組みを理解しないと理由が分からないので、後ほど説明しましょう。ではサルくん、動画生成AIには、どんな技術が必要ですか?
え~と、動画といってもパラパラ漫画と同じだから、時系列に並んだ大量の画像があればいいだけか。そうか、描きたい画像を学習させた画像生成AIがあれば、時間の経過を意識して、オブジェクトや視点の移動を細かにプロンプトで指示さえすれば、ボクもできそうだな
そう、誰でも最初はそう思いますね。ところが、当然ながらそんな簡単な話ではありません。では動画生成の説明の前に、必要となる画像生成の技術について話します。だいぶ前の講座になりますが、画像生成のアルゴリズムGAN(敵対的生成ネットワーク)を説明したと思います。現在は、GANより安定して画像生成ができる画像生成アルゴリズム“拡散モデル(Diffusion model)”が主流となっています。Soraの動画生成技術を理解するためには、この拡散モデルの概念だけでも理解する必要があるので、簡単に説明しましょう。
拡散モデルは、対象の画像に段階的にガウシアン・ノイズを加えていくことで劣化させ、最終的にノイズだけに変換します。その後、劣化の過程をさかのぼるように段階的に再構築していく過程を学習させた生成モデルです
ちょっと待ってください。仕組みとしてはそうなのかもしれませんが、なぜその仕組みで画像が生成できるのかまったく理解できません
そうですよね。ネット上にある大半の解説はこれだけで終わりですが、もう少し解説しましょう。AIの基本にあるニューラルネットワークの一種で、オートエンコーダーというネットワークがあります