


2025年6月24日、データ実務家コミュニティ「データ横丁」は「マイナビTECH+」との共催で「エンタメ業界のデータエンジニアリング最前線」を開いた。2025年11月までに全6回開かれる予定の同イベントの初回は、Googleの渋谷ストリームで行われ、オンライン・オフラインの約300人が参加。講演後の懇親会「楽市楽座」を含めて熱気溢れる滑り出しとなった。同イベントで登壇した株式会社GENDAの松村聡士さんと、株式会社バンダイナムコセブンズの山口大貴さんが語ったエンタメ業界特有の事情・現場で実施されている課題解決への取り組みについて、読者の方にも共有しよう。


GENDA IT戦略部 データエンジニア課 マネージャー 松村 聡士さん
株式会社GENDAはアミューズメント施設・カラオケ・F&B(フード&ビバレッジ)事業などを世界規模で展開する総合エンターテイメント企業だ。同社の事業展開の大きな特徴は、セガ エンタテインメントの株式取得に代表される積極的なM&Aである。
松村聡士さんは、同社でデータマネージャーとデータエンジニアを兼任しており、データ基盤の管理やパイプラインの要件定義、設計開発などを幅広く担っている。松村さんはグループのデータ基盤の構築を初期段階から担い、急成長するビジネスとともに生じて変化する様々な課題・壁に向き合ってきた。エンタメ業界のデータエンジニアリング最前線では、データ基盤のこれまでと現在、これからを各フェーズごとに話した。
現在、同社のデータ基盤にはアミューズメント施設事業、カラオケ事業、ツーリズム事業、F&B事業など多岐にわたるデータが入っている。一方、2021~23年夏までの初期フェーズのデータ基盤は非常にシンプルで、収集したデータを整備・加工・分析するまでの流れである「データのパイプライン」の数も少なかった。データエンジニアが当時1名体制だったこともあり、急速に成長する事業に伴って次々と生じるニーズに応じて最適な技術を選択できるよう、スピードを最優先にした構成だったという。

中期フェーズは主に初期フェーズで上がった課題に対して具体的な解決策を講じた。例えば、案件ごとに異なる手法を用いたパイプラインの標準化や連携方式の統一だ。また、手動だった運用の自動化に取り組んだほか、データカタログを整備してより多くの利用者がデータ管理活用できる環境の構築にも着手。このワークフロー管理とインフラ自動化データ、データカタログの整備の3本柱で、初期の課題を解決・カバーした。
中期フェーズにおいても、カタログ機能の限界や分析基盤の不足やBIツールの運用コストなどの大きな課題が残されていた。カタログ機能の陳腐化を防ぐために、自作カタログからオープンメタデータに切り替えた。また、AIと組み合わせた分析環境を構築するなど、様々なツールやサービスを組み合わせることで高度な分析・多彩なデータ活用が可能な環境を作り上げてきた。
その一方で、現在も直面している課題もある。例えばツールとサービスの乱立による「役割の重複」や「管理の手間」の増大のほか、権限・ガバナンス設計の複雑化を挙げた。組織の拡大し、グループが多様化するにつれて各基盤ごとに権限を設計管理してコントロールすることが特に難しくなったという。そしてコードベースであったり、AIと連携しやすい「AIフレンドリー」な基盤への対応も求められている。このような課題を解決するために、まずは各ツールとサービスの役割を整理して重複や無駄の少ないチップの基盤を目指していく。
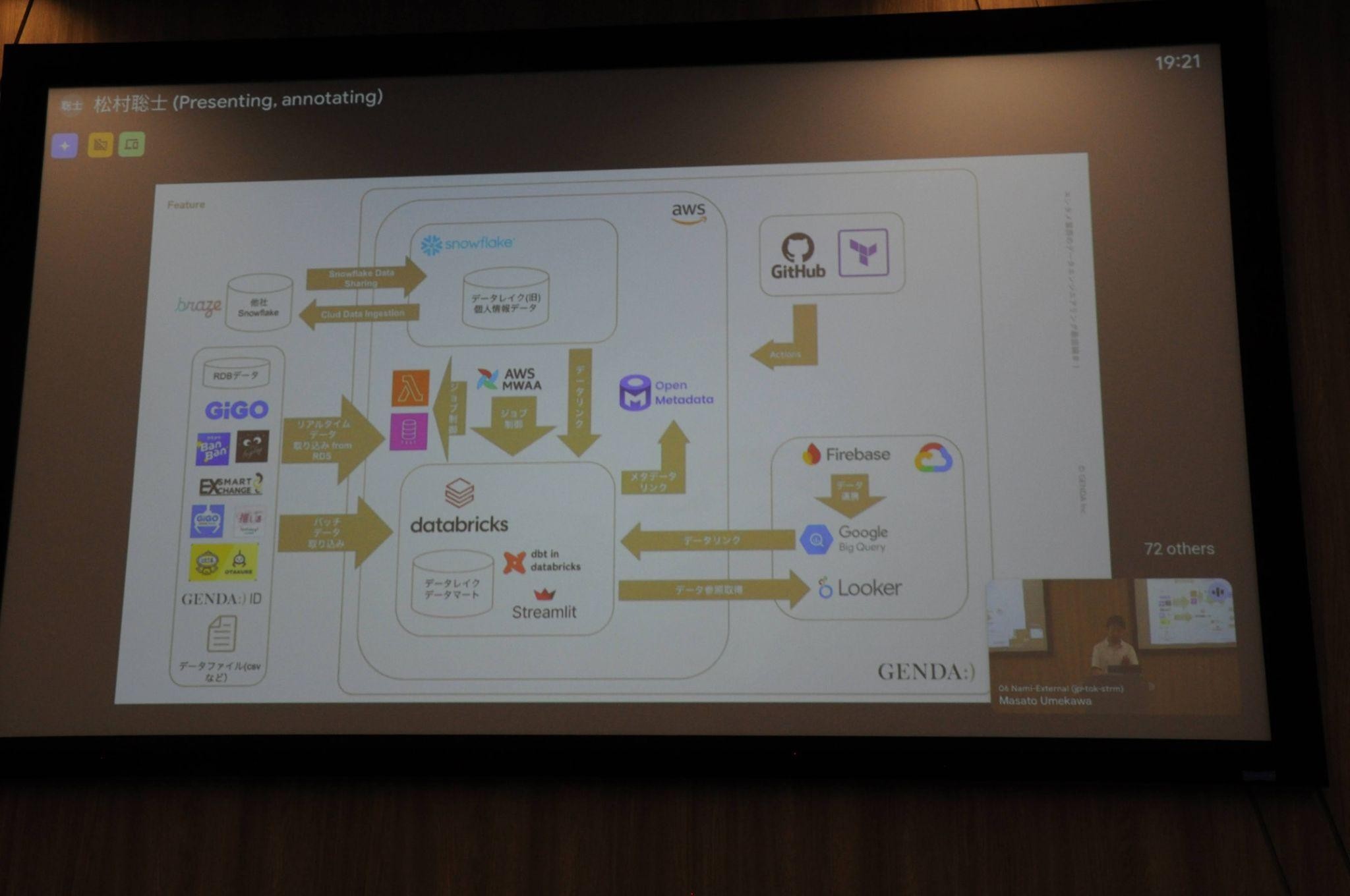
今後はサイエンティスト向けだけでなく、エンジニア以外のビジネスサイドや現場メンバーが直感的にデータ活用できる環境の構築を目指す。また、さらにはグループ会社が増えたときも、大枠を保ちつつ柔軟に拡張できる設計を目標とし、リバースのサービス連携とかAIと将来像を見据えて、拡大、進化、運用コストのバランスの最適化を両立する規定の基盤を目指していく。データ権限についても柔軟にデータ共有しつつも、不要なユーザーはしっかりと制限できる設計を実現したいという。
「データ基盤の構築で大切なのは、課題解決と改善を継続することです。 環境やニーズが変わる中でも、重要なアップデートを重ねて変化に寄り添い、進化し続ける基盤を実現しようと思っております」

バンダイナムコセブンズ テクノロジーイノベーション部 新規サービス開発課 プロダクト研究チーム チームリーダー ソフトウェアエンジニア 山口 大貴さん
株式会社バンダイナムコセブンズの山口大貴さんは、新卒でバンダイナムコエンターテインメントの遊技機部門に入社。その後、2016年に株式会社バンダイナムコセブンズが設立された際に移籍した。このような豊富なキャリアと「課題を見つけると首を突っ込みたくなる」という性格から、解決に必要な技術に触れ続けた結果、多彩なスキルセットを有することになった。そして現在は「多面的エンジニア」もしくは「超自己主張エンジニア」として業務にあたっている。
①遊技機エンジニア
・サウンド制御
・演出抽選制御
・映像開発環境構築
②データエンジニア
・ユーザリサーチ
・口コミ分析
・社内BI構築
③研究開発エンジニア
・Vアバター収録
・キャラ会話デバイス
・小説コンテスト審査員
山口さんが発表したAIの活用事例は、パチンコ・パチスロ現場の「アニメ50話分の一覧資料」の作成業務の効率化だ。一段資料とは、アニメ資料から場面写(場面カット)を作成してまとめたものであり、アニメを再生してキャプチャーを撮り、台詞を文字起こしする作業が伴う。50話で換算すると合計21時間分にも及ぶ資料を、従来は全て手作業で行っていたという。このような膨大な作業を効率化するために、山口さんが着手したのがAIを活用した「PoC(概念実証)」だ。
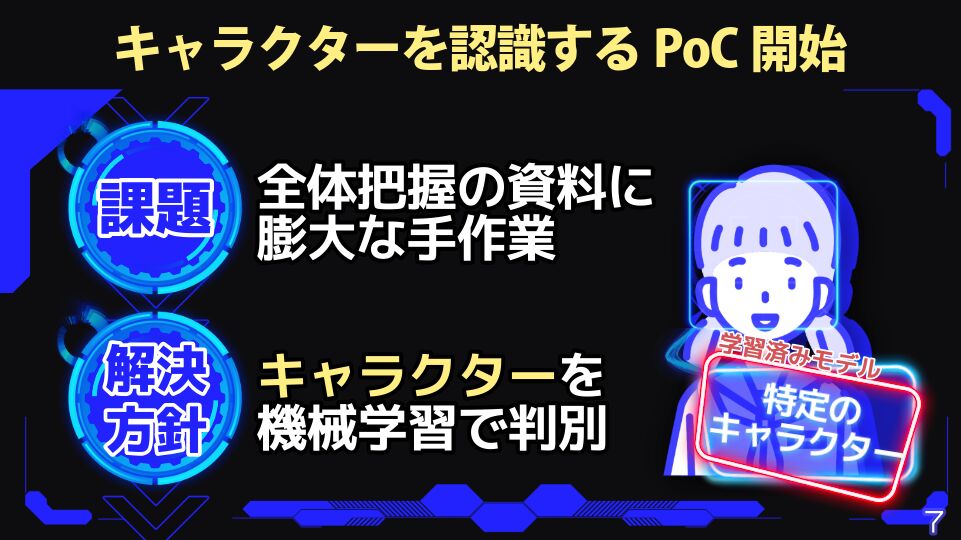
企画時にキャラクターの行動などを確認しやすくするため、手始めに主人公のキャラクターを自動で検出することを目的としたPoCをスタート。キャラクターの顔を四角で囲んで学習データとし、既存のモデルに転移・学習させることで判定可能なモデルを作成した。検証ではAWSの画像サービス「Custom Labels(カスタムラベル)」を活用。0.5秒おきにキャプチャした画像を用意し、API経由でモデルに画像の判定を行わせた。もし特定のキャラクターの判定するモデルがうまくいけば、アニメの映像の中からそのキャラクターの顔を自動的に出して効率化が図れる予定だった。
しかし、この検証は失敗に終わった。本来、自動的に出すはずだったキャラクター以外の登場人物まで、解釈されてしまうケースが多すぎてしまったのだ。結論、カスタムラベルは少ない学習データであってもパターン表示できれば、人物の検知の精度は挙げられるものの、キャラクター個別の判別に大きなハードルがあったことが、検証失敗の大きな要因だった。ただ、ツールの特性だけではなく「コミュニケーション」と「技術者のこだわり」こそが重要な反省点だったと、山口さんは振り返る。
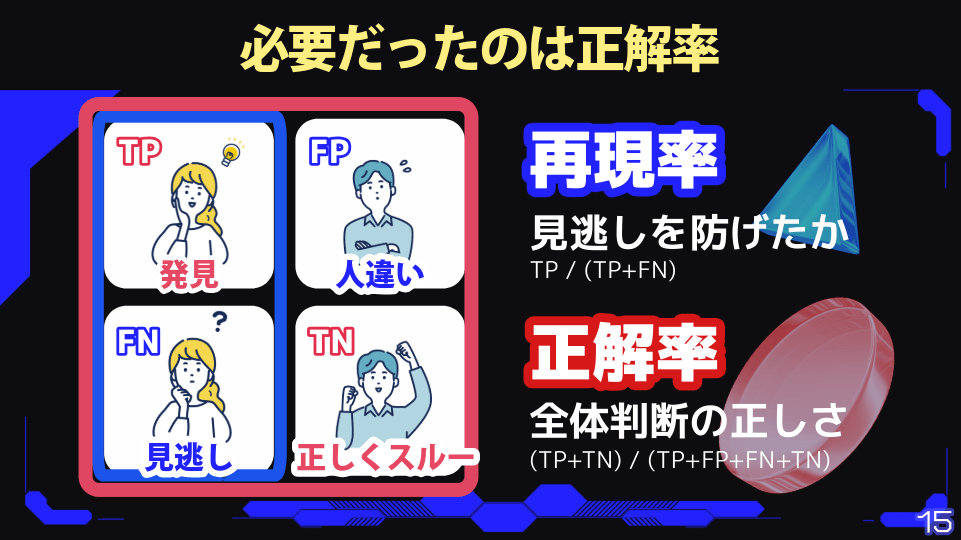
失敗した原因の一つ目は、意思決定者とエンジニア(山口さん)の認識の齟齬だったと振り返る。当初、意思決定者からは「キャラクターの取りこぼしはNG」「登場シーンを見逃したらツールとして使えない」という強い要望があった。そこで山口さんはどのくらい見逃しを防げたかという「再現率」が評価基準であると考え、走り出してしまったという。ただ、本当に求められていたのは人違いなどを防ぐための基準「正解率」だったのだ。さらに「設定資料集から完璧に判断したい」という要望に応えるべく過学習させてしまったことも、失敗の原因だったと述べた。その結果、再現率は90%にまで近づいたものの正解率は35%と低い数値になり、「人違いが多くなり使えない」という評価が下されたのだ。

この失敗を経て山口さんは「本当に現場が欲しかったもの」について、直接声を聞くなどしてリサーチを実施。その結果、完璧にキャラクターの顔を見つける以前に「膨大過ぎる作業の工数を少しでも減らして欲しい」という要望が出てきた。それに対応するために「シーンの切り替わりを判断し、場面写資料そのものの作業工数を減らす」という全く異なるアプローチで検証に着手した。実は「映像を場面ごとに切り分けて表示する」という、現場の要望に応えられる機能は、失敗した最初のPoCの20%程度の進捗の段階で完成されており、現場からはすぐに「この機能で良いからすぐに通過してください」という声が上がったという。その後、検証を続けて、機械学習サービスを活用することで映像の切り替わりを俯瞰する「CutSplitter」の開発までこぎつけ、場面写資料を作成する工数を半分まで削減することに成功した。
「私はこだわりすぎていて、実は最初のPoCの初期段階で現場の役に立てることに気付いていませんでした。『認識共有は迅速』ということです。私のように意外と進捗の20%程度の浅い状況であっても、関係者とゴールイメージを再認識することで成果を得られる可能性もありますし、出戻りも少ないですから。今後、私自身も進捗の20%程度で共有を図っていきたいと思います。」
最後に、大盛況だった講演後の懇親会「楽市楽座」についても紹介しよう。

楽市楽座は、登壇者の質問会テーブル、協賛企業のミニ展示会のテーブルを屋台風に設けた懇親会だ。楽市楽座の参加は原則必須なこともあり、会場は多くの人でが名刺交換や登壇者への質問などが行われており熱気に包まれていた。
メルマガ登録をしていただくと、記事やイベントなどの最新情報をお届けいたします。
学びをシェアする



30秒で理解!インフォグラフィックや動画で解説!フォローして『1日1記事』インプットしよう!























データ越境者に寄り添うメデイア「データのじかん」が提供する便利ツールです。
本ツールは、JavaScriptを用いてお客様のブラウザ上で処理を行います。サーバーとの通信は行われず、入力データはお客様のみの端末内で処理されます。





































